 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient OWL2QL Meta-reasoning Using ASP-based Hybrid Knowledge Bases
Feb 13, 2025Metamodeling refers to scenarios in ontologies in which classes and roles can be members of classes or occur in roles. This is a desirable modelling feature in several applications, but allowing it without restrictions is problematic for several reasons, mainly because it causes undecidability. Therefore, practical languages either forbid metamodeling explicitly or treat occurrences of classes as instances to be semantically different from other occurrences, thereby not allowing metamodeling semantically. Several extensions have been proposed to provide metamodeling to some extent. Building on earlier work that reduces metamodeling query answering to Datalog query answering, recently reductions to query answering over hybrid knowledge bases were proposed with the aim of using the Datalog transformation only where necessary. Preliminary work showed that the approach works, but the hoped-for performance improvements were not observed yet. In this work we expand on this body of work by improving the theoretical basis of the reductions and by using alternative tools that show competitive performance.
* In Proceedings ICLP 2024, arXiv:2502.08453
Evaluating Datalog Tools for Meta-reasoning over OWL 2 QL
Feb 05, 2024


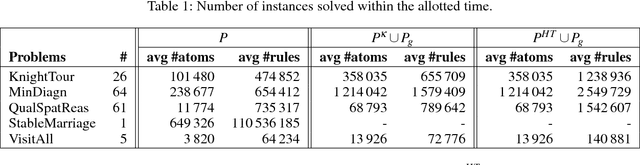
Metamodeling is a general approach to expressing knowledge about classes and properties in an ontology. It is a desirable modeling feature in multiple applications that simplifies the extension and reuse of ontologies. Nevertheless, allowing metamodeling without restrictions is problematic for several reasons, mainly due to undecidability issues. Practical languages, therefore, forbid classes to occur as instances of other classes or treat such occurrences as semantically different objects. Specifically, meta-querying in SPARQL under the Direct Semantic Entailment Regime (DSER) uses the latter approach, thereby effectively not supporting meta-queries. However, several extensions enabling different metamodeling features have been proposed over the last decade. This paper deals with the Metamodeling Semantics (MS) over OWL 2 QL and the Metamodeling Semantic Entailment Regime (MSER), as proposed in Lenzerini et al. (2015) and Lenzerini et al. (2020); Cima et al. (2017). A reduction from OWL 2 QL to Datalog for meta-querying was proposed in Cima et al. (2017). In this paper, we experiment with various logic programming tools that support Datalog querying to determine their suitability as back-ends to MSER query answering. These tools stem from different logic programming paradigms (Prolog, pure Datalog, Answer Set Programming, Hybrid Knowledge Bases). Our work shows that the Datalog approach to MSER querying is practical also for sizeable ontologies with limited resources (time and memory). This paper significantly extends Qureshi & Faber (2021) by a more detailed experimental analysis and more background. Under consideration in Theory and Practice of Logic Programming (TPLP).
An efficient solver for ASP(Q)
May 17, 2023Answer Set Programming with Quantifiers ASP(Q) extends Answer Set Programming (ASP) to allow for declarative and modular modeling of problems from the entire polynomial hierarchy. The first implementation of ASP(Q), called qasp, was based on a translation to Quantified Boolean Formulae (QBF) with the aim of exploiting the well-developed and mature QBF-solving technology. However, the implementation of the QBF encoding employed in qasp is very general and might produce formulas that are hard to evaluate for existing QBF solvers because of the large number of symbols and sub-clauses. In this paper, we present a new implementation that builds on the ideas of qasp and features both a more efficient encoding procedure and new optimized encodings of ASP(Q) programs in QBF. The new encodings produce smaller formulas (in terms of the number of quantifiers, variables, and clauses) and result in a more efficient evaluation process. An algorithm selection strategy automatically combines several QBF-solving back-ends to further increase performance. An experimental analysis, conducted on known benchmarks, shows that the new system outperforms qasp.
Aggregate Semantics for Propositional Answer Set Programs
Sep 17, 2021



Answer Set Programming (ASP) emerged in the late 1990ies as a paradigm for Knowledge Representation and Reasoning. The attractiveness of ASP builds on an expressive high-level modeling language along with the availability of powerful off-the-shelf solving systems. While the utility of incorporating aggregate expressions in the modeling language has been realized almost simultaneously with the inception of the first ASP solving systems, a general semantics of aggregates and its efficient implementation have been long-standing challenges. Aggregates have been proposed and widely used in database systems, and also in the deductive database language Datalog, which is one of the main precursors of ASP. The use of aggregates was, however, still restricted in Datalog (by either disallowing recursion or only allowing monotone aggregates), while several ways to integrate unrestricted aggregates evolved in the context of ASP. In this survey, we pick up at this point of development by presenting and comparing the main aggregate semantics that have been proposed for propositional ASP programs. We highlight crucial properties such as computational complexity and expressive power, and outline the capabilities and limitations of different approaches by illustrative examples.
Thirty years of Epistemic Specifications
Aug 17, 2021
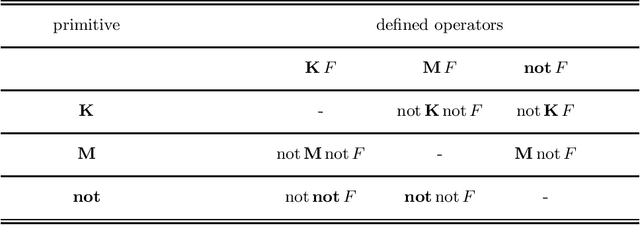
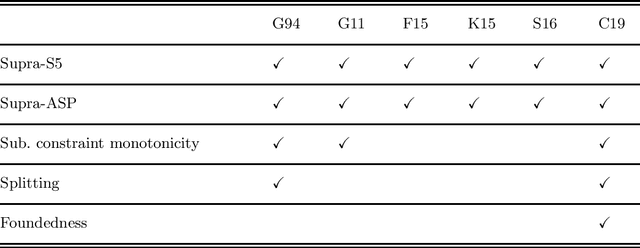
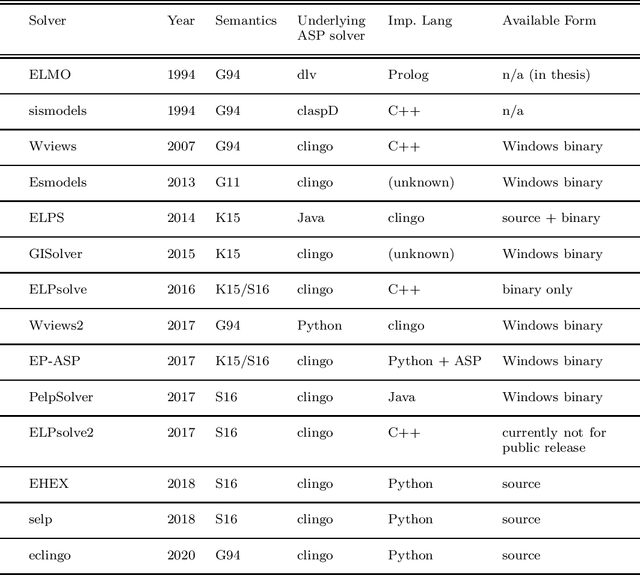
The language of epistemic specifications and epistemic logic programs extends disjunctive logic programs under the stable model semantics with modal constructs called subjective literals. Using subjective literals, it is possible to check whether a regular literal is true in every or some stable models of the program, those models, in this context also called \emph{belief sets}, being collected in a set called world view. This allows for representing, within the language, whether some proposition should be understood accordingly to the open or the closed world assumption. Several attempts for capturing the intuitions underlying the language by means of a formal semantics were given, resulting in a multitude of proposals that makes it difficult to understand the current state of the art. In this paper, we provide an overview of the inception of the field and the knowledge representation and reasoning tasks it is suitable for. We also provide a detailed analysis of properties of proposed semantics, and an outlook of challenges to be tackled by future research in the area. Under consideration in Theory and Practice of Logic Programming (TPLP)
Determining ActionReversibility in STRIPS Using Answer Set and Epistemic Logic Programming
Aug 11, 2021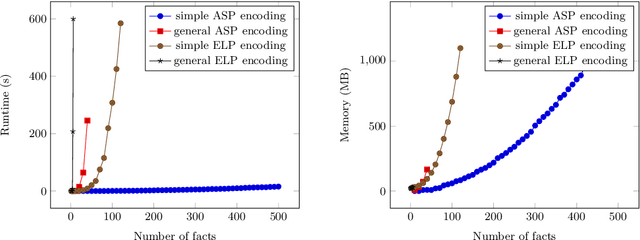
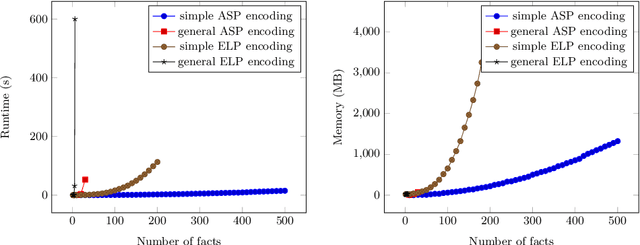
In the context of planning and reasoning about actions and change, we call an action reversible when its effects can be reverted by applying other actions, returning to the original state. Renewed interest in this area has led to several results in the context of the PDDL language, widely used for describing planning tasks. In this paper, we propose several solutions to the computational problem of deciding the reversibility of an action. In particular, we leverage an existing translation from PDDL to Answer Set Programming (ASP), and then use several different encodings to tackle the problem of action reversibility for the STRIPS fragment of PDDL. For these, we use ASP, as well as Epistemic Logic Programming (ELP), an extension of ASP with epistemic operators, and compare and contrast their strengths and weaknesses. Under consideration for acceptance in TPLP.
ASP-Core-2 Input Language Format
Nov 11, 2019Standardization of solver input languages has been a main driver for the growth of several areas within knowledge representation and reasoning, fostering the exploitation in actual applications. In this document we present the ASP-Core-2 standard input language for Answer Set Programming, which has been adopted in ASP Competition events since 2013.
On Uniform Equivalence of Epistemic Logic Programs
Jul 25, 2019Epistemic Logic Programs (ELPs) extend Answer Set Programming (ASP) with epistemic negation and have received renewed interest in recent years. This led to the development of new research and efficient solving systems for ELPs. In practice, ELPs are often written in a modular way, where each module interacts with other modules by accepting sets of facts as input, and passing on sets of facts as output. An interesting question then presents itself: under which conditions can such a module be replaced by another one without changing the outcome, for any set of input facts? This problem is known as uniform equivalence, and has been studied extensively for ASP. For ELPs, however, such an investigation is, as of yet, missing. In this paper, we therefore propose a characterization of uniform equivalence that can be directly applied to the language of state-of-the-art ELP solvers. We also investigate the computational complexity of deciding uniform equivalence for two ELPs, and show that it is on the third level of the polynomial hierarchy.
On the Computation of Paracoherent Answer Sets
Jul 21, 2017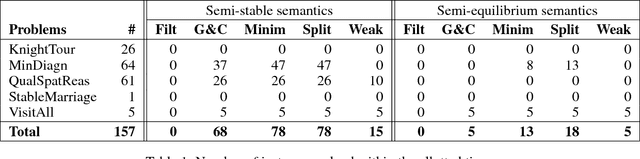
Answer Set Programming (ASP) is a well-established formalism for nonmonotonic reasoning. An ASP program can have no answer set due to cyclic default negation. In this case, it is not possible to draw any conclusion, even if this is not intended. Recently, several paracoherent semantics have been proposed that address this issue, and several potential applications for these semantics have been identified. However, paracoherent semantics have essentially been inapplicable in practice, due to the lack of efficient algorithms and implementations. In this paper, this lack is addressed, and several different algorithms to compute semi-stable and semi-equilibrium models are proposed and implemented into an answer set solving framework. An empirical performance comparison among the new algorithms on benchmarks from ASP competitions is given as well.
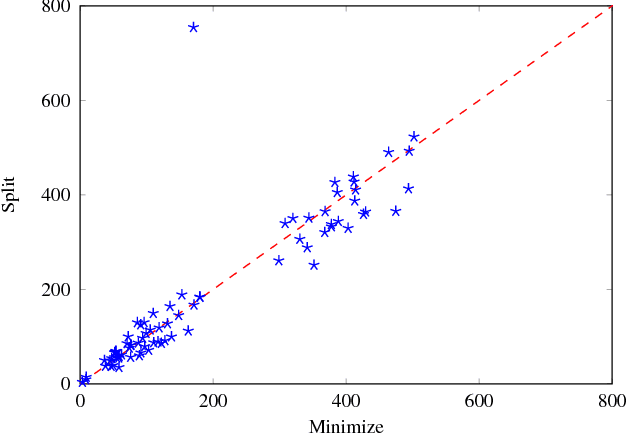
Solving Set Optimization Problems by Cardinality Optimization via Weak Constraints with an Application to Argumentation
Dec 22, 2016

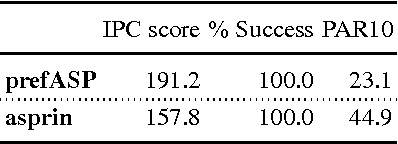

Optimization - minimization or maximization - in the lattice of subsets is a frequent operation in Artificial Intelligence tasks. Examples are subset-minimal model-based diagnosis, nonmonotonic reasoning by means of circumscription, or preferred extensions in abstract argumentation. Finding the optimum among many admissible solutions is often harder than finding admissible solutions with respect to both computational complexity and methodology. This paper addresses the former issue by means of an effective method for finding subset-optimal solutions. It is based on the relationship between cardinality-optimal and subset-optimal solutions, and the fact that many logic-based declarative programming systems provide constructs for finding cardinality-optimal solutions, for example maximum satisfiability (MaxSAT) or weak constraints in Answer Set Programming (ASP). Clearly each cardinality-optimal solution is also a subset-optimal one, and if the language also allows for the addition of particular restricting constructs (both MaxSAT and ASP do) then all subset-optimal solutions can be found by an iterative computation of cardinality-optimal solutions. As a showcase, the computation of preferred extensions of abstract argumentation frameworks using the proposed method is studied.