 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntoLogX: Ontology-Guided Knowledge Graph Extraction from Cybersecurity Logs with Large Language Models
Oct 01, 2025System logs represent a valuable source of Cyber Threat Intelligence (CTI), capturing attacker behaviors, exploited vulnerabilities, and traces of malicious activity. Yet their utility is often limited by lack of structure, semantic inconsistency, and fragmentation across devices and sessions. Extracting actionable CTI from logs therefore requires approaches that can reconcile noisy, heterogeneous data into coherent and interoperable representations. We introduce OntoLogX, an autonomous Artificial Intelligence (AI) agent that leverages Large Language Models (LLMs) to transform raw logs into ontology-grounded Knowledge Graphs (KGs). OntoLogX integrates a lightweight log ontology with Retrieval Augmented Generation (RAG) and iterative correction steps, ensuring that generated KGs are syntactically and semantically valid. Beyond event-level analysis, the system aggregates KGs into sessions and employs a LLM to predict MITRE ATT&CK tactics, linking low-level log evidence to higher-level adversarial objectives. We evaluate OntoLogX on both logs from a public benchmark and a real-world honeypot dataset, demonstrating robust KG generation across multiple KGs backends and accurate mapping of adversarial activity to ATT&CK tactics. Results highlight the benefits of retrieval and correction for precision and recall, the effectiveness of code-oriented models in structured log analysis, and the value of ontology-grounded representations for actionable CTI extraction.
HAVA: Hybrid Approach to Value-Alignment through Reward Weighing for Reinforcement Learning
May 21, 2025Our society is governed by a set of norms which together bring about the values we cherish such as safety, fairness or trustworthiness. The goal of value-alignment is to create agents that not only do their tasks but through their behaviours also promote these values. Many of the norms are written as laws or rules (legal / safety norms) but even more remain unwritten (social norms). Furthermore, the techniques used to represent these norms also differ. Safety / legal norms are often represented explicitly, for example, in some logical language while social norms are typically learned and remain hidden in the parameter space of a neural network. There is a lack of approaches in the literature that could combine these various norm representations into a single algorithm. We propose a novel method that integrates these norms into the reinforcement learning process. Our method monitors the agent's compliance with the given norms and summarizes it in a quantity we call the agent's reputation. This quantity is used to weigh the received rewards to motivate the agent to become value-aligned. We carry out a series of experiments including a continuous state space traffic problem to demonstrate the importance of the written and unwritten norms and show how our method can find the value-aligned policies. Furthermore, we carry out ablations to demonstrate why it is better to combine these two groups of norms rather than using either separately.
Toward Foundation Models for Online Complex Event Detection in CPS-IoT: A Case Study
Mar 15, 2025



Complex events (CEs) play a crucial role in CPS-IoT applications, enabling high-level decision-making in domains such as smart monitoring and autonomous systems. However, most existing models focus on short-span perception tasks, lacking the long-term reasoning required for CE detection. CEs consist of sequences of short-time atomic events (AEs) governed by spatiotemporal dependencies. Detecting them is difficult due to long, noisy sensor data and the challenge of filtering out irrelevant AEs while capturing meaningful patterns. This work explores CE detection as a case study for CPS-IoT foundation models capable of long-term reasoning. We evaluate three approaches: (1) leveraging large language models (LLMs), (2) employing various neural architectures that learn CE rules from data, and (3) adopting a neurosymbolic approach that integrates neural models with symbolic engines embedding human knowledge. Our results show that the state-space model, Mamba, which belongs to the second category, outperforms all methods in accuracy and generalization to longer, unseen sensor traces. These findings suggest that state-space models could be a strong backbone for CPS-IoT foundation models for long-span reasoning tasks.
NARCE: A Mamba-Based Neural Algorithmic Reasoner Framework for Online Complex Event Detection
Feb 11, 2025Current machine learning models excel in short-span perception tasks but struggle to derive high-level insights from long-term observation, a capability central to understanding complex events (CEs). CEs, defined as sequences of short-term atomic events (AEs) governed by spatiotemporal rules, are challenging to detect online due to the need to extract meaningful patterns from long and noisy sensor data while ignoring irrelevant events. We hypothesize that state-based methods are well-suited for CE detection, as they capture event progression through state transitions without requiring long-term memory. Baseline experiments validate this, demonstrating that the state-space model Mamba outperforms existing architectures. However, Mamba's reliance on extensive labeled data, which are difficult to obtain, motivates our second hypothesis: decoupling CE rule learning from noisy sensor data can reduce data requirements. To address this, we propose NARCE, a framework that combines Neural Algorithmic Reasoning (NAR) to split the task into two components: (i) learning CE rules independently of sensor data using synthetic concept traces generated by LLMs and (ii) mapping sensor inputs to these rules via an adapter. Our results show that NARCE outperforms baselines in accuracy, generalization to unseen and longer sensor data, and data efficiency, significantly reducing annotation costs while advancing robust CE detection.
Risk-aware Classification via Uncertainty Quantification
Dec 04, 2024



Autonomous and semi-autonomous systems are using deep learning models to improve decision-making. However, deep classifiers can be overly confident in their incorrect predictions, a major issue especially in safety-critical domains. The present study introduces three foundational desiderata for developing real-world risk-aware classification systems. Expanding upon the previously proposed Evidential Deep Learning (EDL), we demonstrate the unity between these principles and EDL's operational attributes. We then augment EDL empowering autonomous agents to exercise discretion during structured decision-making when uncertainty and risks are inherent. We rigorously examine empirical scenarios to substantiate these theoretical innovations. In contrast to existing risk-aware classifiers, our proposed methodologies consistently exhibit superior performance, underscoring their transformative potential in risk-conscious classification strategies.
Approaches to human activity recognition via passive radar
Oct 31, 2024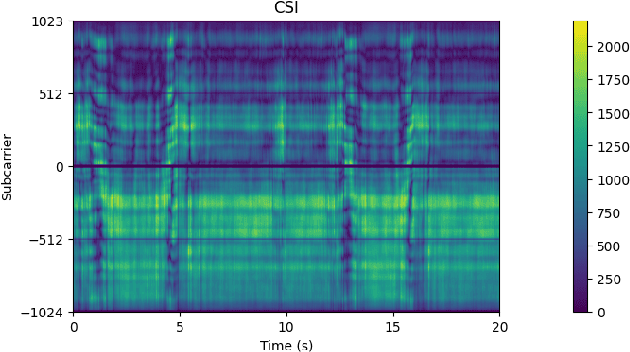
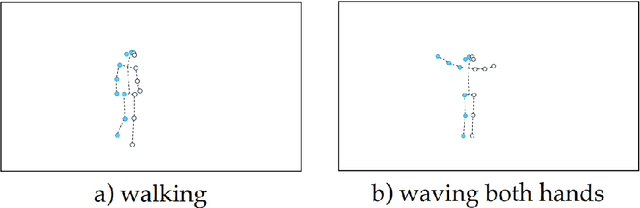

The thesis explores novel methods for Human Activity Recognition (HAR) using passive radar with a focus on non-intrusive Wi-Fi Channel State Information (CSI) data. Traditional HAR approaches often use invasive sensors like cameras or wearables, raising privacy issues. This study leverages the non-intrusive nature of CSI, using Spiking Neural Networks (SNN) to interpret signal variations caused by human movements. These networks, integrated with symbolic reasoning frameworks such as DeepProbLog, enhance the adaptability and interpretability of HAR systems. SNNs offer reduced power consumption, ideal for privacy-sensitive applications. Experimental results demonstrate SNN-based neurosymbolic models achieve high accuracy making them a promising alternative for HAR across various domains.
CHIRPs: Change-Induced Regret Proxy metrics for Lifelong Reinforcement Learning
Sep 05, 2024Reinforcement learning agents can achieve superhuman performance in static tasks but are costly to train and fragile to task changes. This limits their deployment in real-world scenarios where training experience is expensive or the context changes through factors like sensor degradation, environmental processes or changing mission priorities. Lifelong reinforcement learning aims to improve sample efficiency and adaptability by studying how agents perform in evolving problems. The difficulty that these changes pose to an agent is rarely measured directly, however. Agent performances can be compared across a change, but this is often prohibitively expensive. We propose Change-Induced Regret Proxy (CHIRP) metrics, a class of metrics for approximating a change's difficulty while avoiding the high costs of using trained agents. A relationship between a CHIRP metric and agent performance is identified in two environments, a simple grid world and MetaWorld's suite of robotic arm tasks. We demonstrate two uses for these metrics: for learning, an agent that clusters MDPs based on a CHIRP metric achieves $17\%$ higher average returns than three existing agents in a sequence of MetaWorld tasks. We also show how a CHIRP can be calibrated to compare the difficulty of changes across distinctly different environments.
Learning Robust Reward Machines from Noisy Labels
Aug 27, 2024
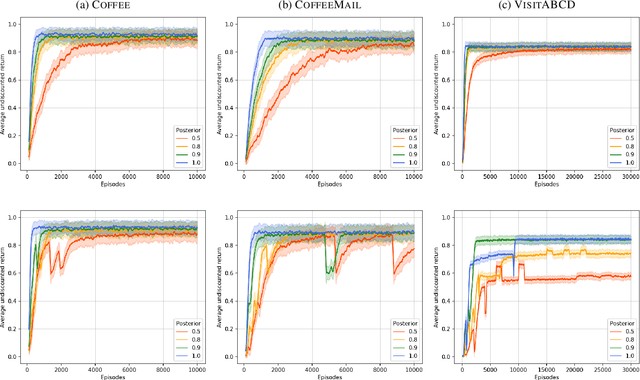
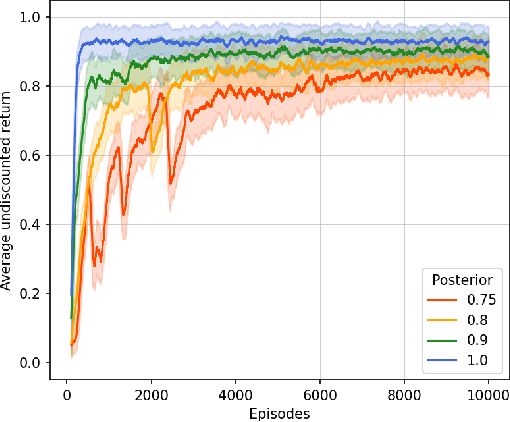
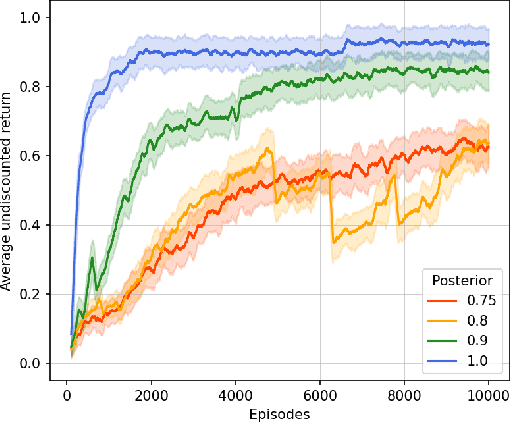
This paper presents PROB-IRM, an approach that learns robust reward machines (RMs) for reinforcement learning (RL) agents from noisy execution traces. The key aspect of RM-driven RL is the exploitation of a finite-state machine that decomposes the agent's task into different subtasks. PROB-IRM uses a state-of-the-art inductive logic programming framework robust to noisy examples to learn RMs from noisy traces using the Bayesian posterior degree of beliefs, thus ensuring robustness against inconsistencies. Pivotal for the results is the interleaving between RM learning and policy learning: a new RM is learned whenever the RL agent generates a trace that is believed not to be accepted by the current RM. To speed up the training of the RL agent, PROB-IRM employs a probabilistic formulation of reward shaping that uses the posterior Bayesian beliefs derived from the traces. Our experimental analysis shows that PROB-IRM can learn (potentially imperfect) RMs from noisy traces and exploit them to train an RL agent to solve its tasks successfully. Despite the complexity of learning the RM from noisy traces, agents trained with PROB-IRM perform comparably to agents provided with handcrafted RMs.
Accurate Passive Radar via an Uncertainty-Aware Fusion of Wi-Fi Sensing Data
Jul 01, 2024Wi-Fi devices can effectively be used as passive radar systems that sense what happens in the surroundings and can even discern human activity. We propose, for the first time, a principled architecture which employs Variational Auto-Encoders for estimating a latent distribution responsible for generating the data, and Evidential Deep Learning for its ability to sense out-of-distribution activities. We verify that the fused data processed by different antennas of the same Wi-Fi receiver results in increased accuracy of human activity recognition compared with the most recent benchmarks, while still being informative when facing out-of-distribution samples and enabling semantic interpretation of latent variables in terms of physical phenomena. The results of this paper are a first contribution toward the ultimate goal of providing a flexible, semantic characterisation of black-swan events, i.e., events for which we have limited to no training data.
Neuro-Symbolic Fusion of Wi-Fi Sensing Data for Passive Radar with Inter-Modal Knowledge Transfer
Jul 01, 2024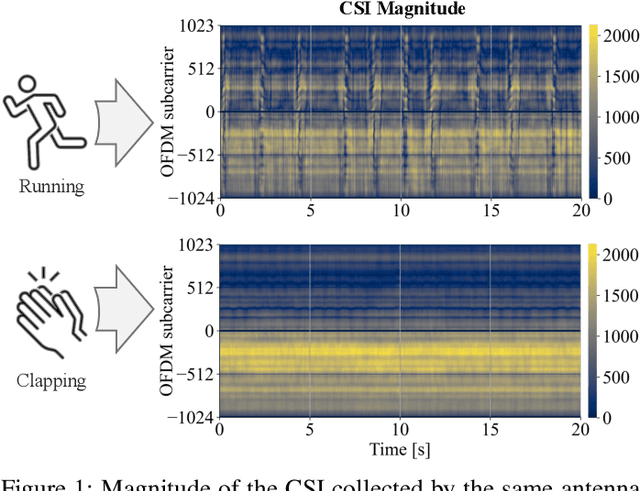
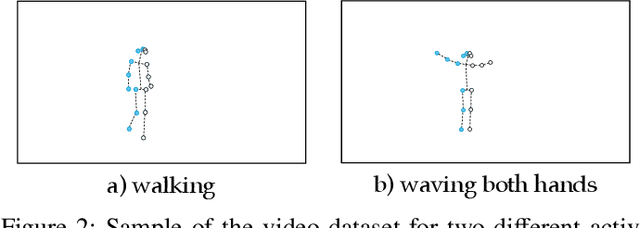
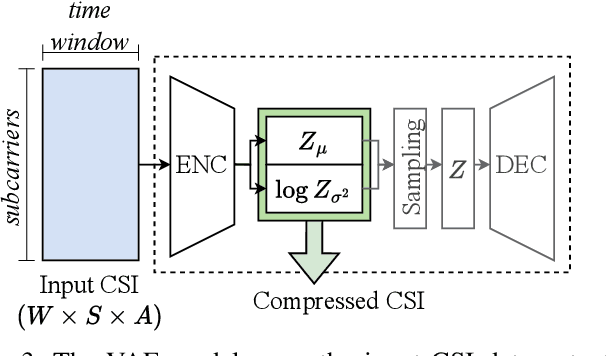
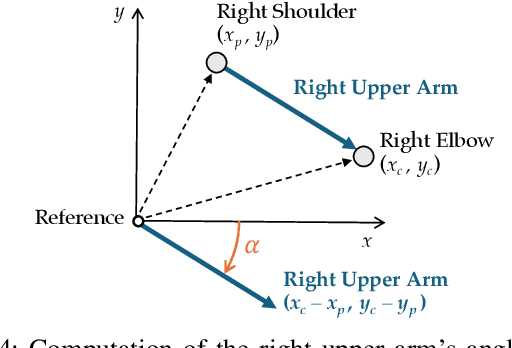
Wi-Fi devices, akin to passive radars, can discern human activities within indoor settings due to the human body's interaction with electromagnetic signals. Current Wi-Fi sensing applications predominantly employ data-driven learning techniques to associate the fluctuations in the physical properties of the communication channel with the human activity causing them. However, these techniques often lack the desired flexibility and transparency. This paper introduces DeepProbHAR, a neuro-symbolic architecture for Wi-Fi sensing, providing initial evidence that Wi-Fi signals can differentiate between simple movements, such as leg or arm movements, which are integral to human activities like running or walking. The neuro-symbolic approach affords gathering such evidence without needing additional specialised data collection or labelling. The training of DeepProbHAR is facilitated by declarative domain knowledge obtained from a camera feed and by fusing signals from various antennas of the Wi-Fi receivers. DeepProbHAR achieves results comparable to the state-of-the-art in human activity recognition. Moreover, as a by-product of the learning process, DeepProbHAR generates specialised classifiers for simple movements that match the accuracy of models trained on finely labelled datasets, which would be particularly costly.