 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAVA: Hybrid Approach to Value-Alignment through Reward Weighing for Reinforcement Learning
May 21, 2025Our society is governed by a set of norms which together bring about the values we cherish such as safety, fairness or trustworthiness. The goal of value-alignment is to create agents that not only do their tasks but through their behaviours also promote these values. Many of the norms are written as laws or rules (legal / safety norms) but even more remain unwritten (social norms). Furthermore, the techniques used to represent these norms also differ. Safety / legal norms are often represented explicitly, for example, in some logical language while social norms are typically learned and remain hidden in the parameter space of a neural network. There is a lack of approaches in the literature that could combine these various norm representations into a single algorithm. We propose a novel method that integrates these norms into the reinforcement learning process. Our method monitors the agent's compliance with the given norms and summarizes it in a quantity we call the agent's reputation. This quantity is used to weigh the received rewards to motivate the agent to become value-aligned. We carry out a series of experiments including a continuous state space traffic problem to demonstrate the importance of the written and unwritten norms and show how our method can find the value-aligned policies. Furthermore, we carry out ablations to demonstrate why it is better to combine these two groups of norms rather than using either separately.
CHIRPs: Change-Induced Regret Proxy metrics for Lifelong Reinforcement Learning
Sep 05, 2024Reinforcement learning agents can achieve superhuman performance in static tasks but are costly to train and fragile to task changes. This limits their deployment in real-world scenarios where training experience is expensive or the context changes through factors like sensor degradation, environmental processes or changing mission priorities. Lifelong reinforcement learning aims to improve sample efficiency and adaptability by studying how agents perform in evolving problems. The difficulty that these changes pose to an agent is rarely measured directly, however. Agent performances can be compared across a change, but this is often prohibitively expensive. We propose Change-Induced Regret Proxy (CHIRP) metrics, a class of metrics for approximating a change's difficulty while avoiding the high costs of using trained agents. A relationship between a CHIRP metric and agent performance is identified in two environments, a simple grid world and MetaWorld's suite of robotic arm tasks. We demonstrate two uses for these metrics: for learning, an agent that clusters MDPs based on a CHIRP metric achieves $17\%$ higher average returns than three existing agents in a sequence of MetaWorld tasks. We also show how a CHIRP can be calibrated to compare the difficulty of changes across distinctly different environments.
Explaining an Agent's Future Beliefs through Temporally Decomposing Future Reward Estimators
Aug 15, 2024
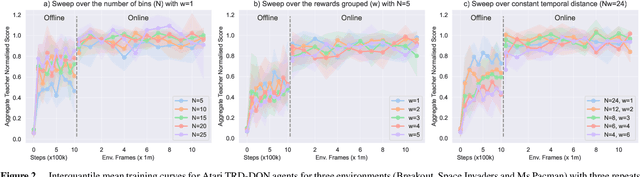
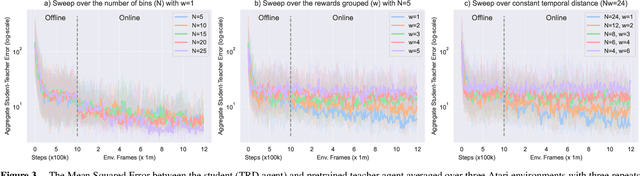
Future reward estimation is a core component of reinforcement learning agents; i.e., Q-value and state-value functions, predicting an agent's sum of future rewards. Their scalar output, however, obfuscates when or what individual future rewards an agent may expect to receive. We address this by modifying an agent's future reward estimator to predict their next N expected rewards, referred to as Temporal Reward Decomposition (TRD). This unlocks novel explanations of agent behaviour. Through TRD we can: estimate when an agent may expect to receive a reward, the value of the reward and the agent's confidence in receiving it; measure an input feature's temporal importance to the agent's action decisions; and predict the influence of different actions on future rewards. Furthermore, we show that DQN agents trained on Atari environments can be efficiently retrained to incorporate TRD with minimal impact on performance.
* 7 pages + 3 pages of supplementary material. Published at ECAI 2024
Speaking Your Language: Spatial Relationships in Interpretable Emergent Communication
Jun 11, 2024


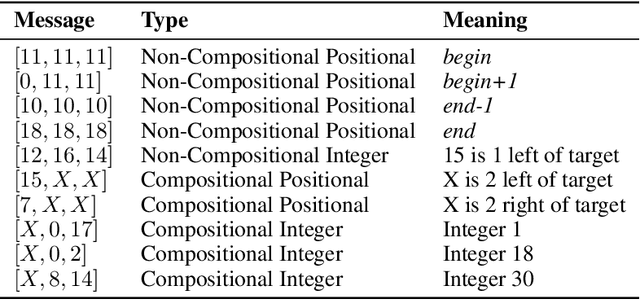
Effective communication requires the ability to refer to specific parts of an observation in relation to others. While emergent communication literature shows success in developing various language properties, no research has shown the emergence of such positional references. This paper demonstrates how agents can communicate about spatial relationships within their observations. The results indicate that agents can develop a language capable of expressing the relationships between parts of their observation, achieving over 90% accuracy when trained in a referential game which requires such communication. Using a collocation measure, we demonstrate how the agents create such references. This analysis suggests that agents use a mixture of non-compositional and compositional messages to convey spatial relationships. We also show that the emergent language is interpretable by humans. The translation accuracy is tested by communicating with the receiver agent, where the receiver achieves over 78% accuracy using parts of this lexicon, confirming that the interpretation of the emergent language was successful.
Combinatorial Client-Master Multiagent Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing
Feb 18, 2024Recently, there has been an explosion of mobile applications that perform computationally intensive tasks such as video streaming, data mining, virtual reality, augmented reality, image processing, video processing, face recognition, and online gaming. However, user devices (UDs), such as tablets and smartphones, have a limited ability to perform the computation needs of the tasks. Mobile edge computing (MEC) has emerged as a promising technology to meet the increasing computing demands of UDs. Task offloading in MEC is a strategy that meets the demands of UDs by distributing tasks between UDs and MEC servers. Deep reinforcement learning (DRL) is gaining attention in task-offloading problems because it can adapt to dynamic changes and minimize online computational complexity. However, the various types of continuous and discrete resource constraints on UDs and MEC servers pose challenges to the design of an efficient DRL-based task-offloading strategy. Existing DRL-based task-offloading algorithms focus on the constraints of the UDs, assuming the availability of enough storage resources on the server. Moreover, existing multiagent DRL (MADRL)--based task-offloading algorithms are homogeneous agents and consider homogeneous constraints as a penalty in their reward function. We proposed a novel combinatorial client-master MADRL (CCM\_MADRL) algorithm for task offloading in MEC (CCM\_MADRL\_MEC) that enables UDs to decide their resource requirements and the server to make a combinatorial decision based on the requirements of the UDs. CCM\_MADRL\_MEC is the first MADRL in task offloading to consider server storage capacity in addition to the constraints in the UDs. By taking advantage of the combinatorial action selection, CCM\_MADRL\_MEC has shown superior convergence over existing MADDPG and heuristic algorithms.
The Strain of Success: A Predictive Model for Injury Risk Mitigation and Team Success in Soccer
Feb 07, 2024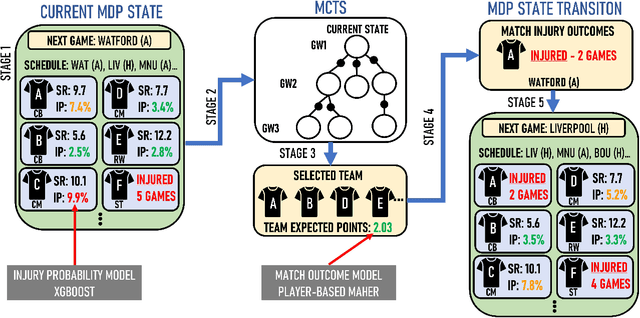
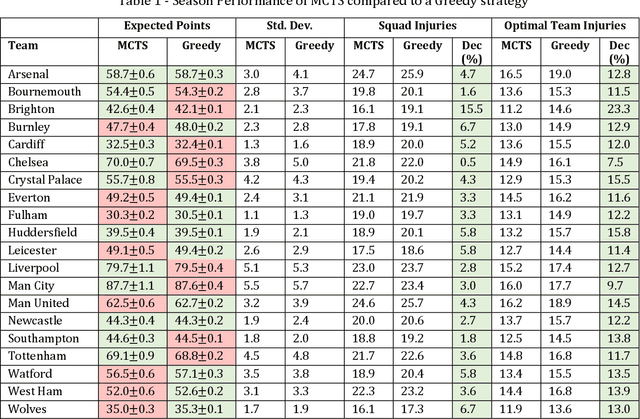
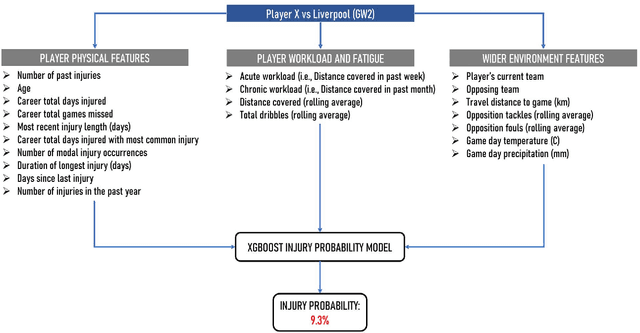
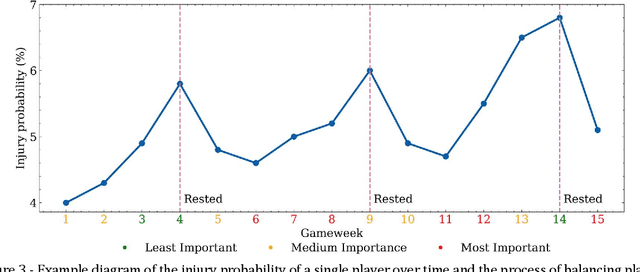
In this paper, we present a novel sequential team selection model in soccer. Specifically, we model the stochastic process of player injury and unavailability using player-specific information learned from real-world soccer data. Monte-Carlo Tree Search is used to select teams for games that optimise long-term team performance across a soccer season by reasoning over player injury probability. We validate our approach compared to benchmark solutions for the 2018/19 English Premier League season. Our model achieves similar season expected points to the benchmark whilst reducing first-team injuries by ~13% and the money inefficiently spent on injured players by ~11% - demonstrating the potential to reduce costs and improve player welfare in real-world soccer teams.
TAPE: Leveraging Agent Topology for Cooperative Multi-Agent Policy Gradient
Jan 15, 2024



Multi-Agent Policy Gradient (MAPG) has made significant progress in recent years. However, centralized critics in state-of-the-art MAPG methods still face the centralized-decentralized mismatch (CDM) issue, which means sub-optimal actions by some agents will affect other agent's policy learning. While using individual critics for policy updates can avoid this issue, they severely limit cooperation among agents. To address this issue, we propose an agent topology framework, which decides whether other agents should be considered in policy gradient and achieves compromise between facilitating cooperation and alleviating the CDM issue. The agent topology allows agents to use coalition utility as learning objective instead of global utility by centralized critics or local utility by individual critics. To constitute the agent topology, various models are studied. We propose Topology-based multi-Agent Policy gradiEnt (TAPE) for both stochastic and deterministic MAPG methods. We prove the policy improvement theorem for stochastic TAPE and give a theoretical explanation for the improved cooperation among agents. Experiment results on several benchmarks show the agent topology is able to facilitate agent cooperation and alleviate CDM issue respectively to improve performance of TAPE. Finally, multiple ablation studies and a heuristic graph search algorithm are devised to show the efficacy of the agent topology.
On Temporal References in Emergent Communication
Oct 10, 2023


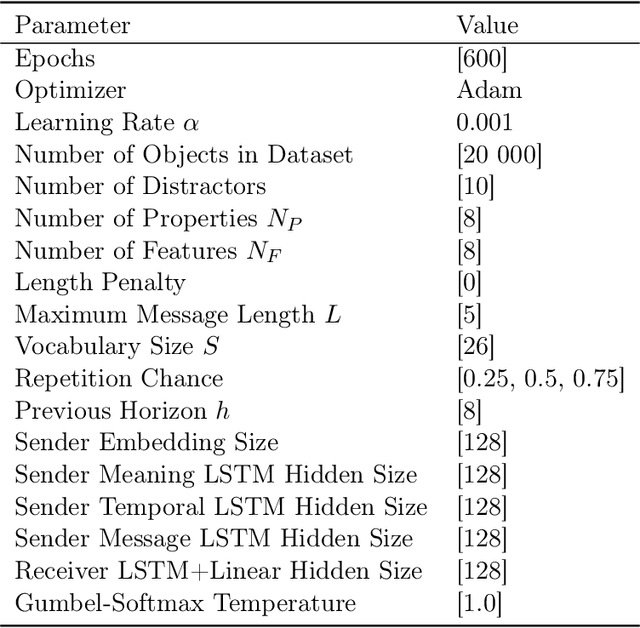
As humans, we use linguistic elements referencing time, such as before or tomorrow, to easily share past experiences and future predictions. While temporal aspects of the language have been considered in computational linguistics, no such exploration has been done within the field of emergent communication. We research this gap, providing the first reported temporal vocabulary within emergent communication literature. Our experimental analysis shows that a different agent architecture is sufficient for the natural emergence of temporal references, and that no additional losses are necessary. Our readily transferable architectural insights provide the basis for the incorporation of temporal referencing into other emergent communication environments.
MADDM: Multi-Advisor Dynamic Binary Decision-Making by Maximizing the Utility
May 15, 2023Being able to infer ground truth from the responses of multiple imperfect advisors is a problem of crucial importance in many decision-making applications, such as lending, trading, investment, and crowd-sourcing. In practice, however, gathering answers from a set of advisors has a cost. Therefore, finding an advisor selection strategy that retrieves a reliable answer and maximizes the overall utility is a challenging problem. To address this problem, we propose a novel strategy for optimally selecting a set of advisers in a sequential binary decision-making setting, where multiple decisions need to be made over time. Crucially, we assume no access to ground truth and no prior knowledge about the reliability of advisers. Specifically, our approach considers how to simultaneously (1) select advisors by balancing the advisors' costs and the value of making correct decisions, (2) learn the trustworthiness of advisers dynamically without prior information by asking multiple advisers, and (3) make optimal decisions without access to the ground truth, improving this over time. We evaluate our algorithm through several numerical experiments. The results show that our approach outperforms two other methods that combine state-of-the-art models.
Inferring Player Location in Sports Matches: Multi-Agent Spatial Imputation from Limited Observations
Feb 13, 2023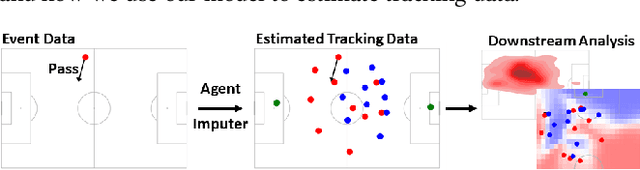
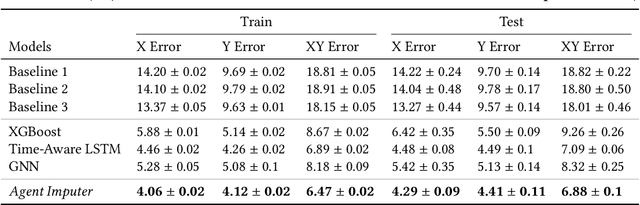
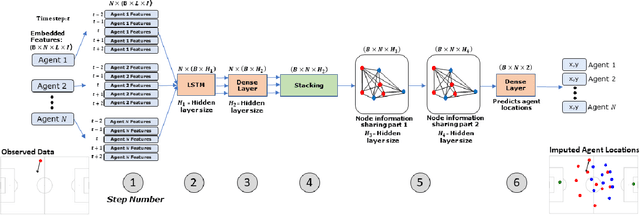
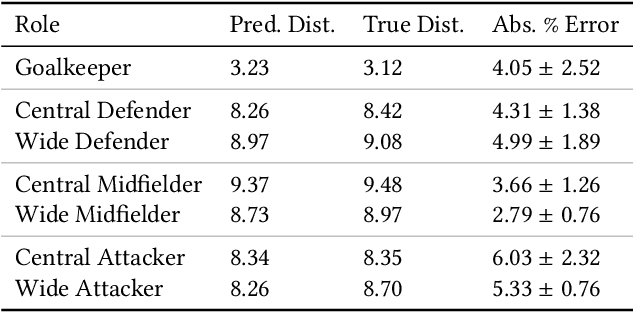
Understanding agent behaviour in Multi-Agent Systems (MAS) is an important problem in domains such as autonomous driving, disaster response, and sports analytics. Existing MAS problems typically use uniform timesteps with observations for all agents. In this work, we analyse the problem of agent location imputation, specifically posed in environments with non-uniform timesteps and limited agent observability (~95% missing values). Our approach uses Long Short-Term Memory and Graph Neural Network components to learn temporal and inter-agent patterns to predict the location of all agents at every timestep. We apply this to the domain of football (soccer) by imputing the location of all players in a game from sparse event data (e.g., shots and passes). Our model estimates player locations to within ~6.9m; a ~62% reduction in error from the best performing baseline. This approach facilitates downstream analysis tasks such as player physical metrics, player coverage, and team pitch control. Existing solutions to these tasks often require optical tracking data, which is expensive to obtain and only available to elite clubs. By imputing player locations from easy to obtain event data, we increase the accessibility of downstream tasks.