 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMCF: A Human-in-the-loop Multi-Robot Collaboration Framework Based on Large Language Models
May 01, 2025Rapid advancements in artificial intelligence (AI) have enabled robots to performcomplex tasks autonomously with increasing precision. However, multi-robot systems (MRSs) face challenges in generalization, heterogeneity, and safety, especially when scaling to large-scale deployments like disaster response. Traditional approaches often lack generalization, requiring extensive engineering for new tasks and scenarios, and struggle with managing diverse robots. To overcome these limitations, we propose a Human-in-the-loop Multi-Robot Collaboration Framework (HMCF) powered by large language models (LLMs). LLMs enhance adaptability by reasoning over diverse tasks and robot capabilities, while human oversight ensures safety and reliability, intervening only when necessary. Our framework seamlessly integrates human oversight, LLM agents, and heterogeneous robots to optimize task allocation and execution. Each robot is equipped with an LLM agent capable of understanding its capabilities, converting tasks into executable instructions, and reducing hallucinations through task verification and human supervision. Simulation results show that our framework outperforms state-of-the-art task planning methods, achieving higher task success rates with an improvement of 4.76%. Real-world tests demonstrate its robust zero-shot generalization feature and ability to handle diverse tasks and environments with minimal human intervention.
Improving Controller Generalization with Dimensionless Markov Decision Processes
Apr 14, 2025



Controllers trained with Reinforcement Learning tend to be very specialized and thus generalize poorly when their testing environment differs from their training one. We propose a Model-Based approach to increase generalization where both world model and policy are trained in a dimensionless state-action space. To do so, we introduce the Dimensionless Markov Decision Process ($\Pi$-MDP): an extension of Contextual-MDPs in which state and action spaces are non-dimensionalized with the Buckingham-$\Pi$ theorem. This procedure induces policies that are equivariant with respect to changes in the context of the underlying dynamics. We provide a generic framework for this approach and apply it to a model-based policy search algorithm using Gaussian Process models. We demonstrate the applicability of our method on simulated actuated pendulum and cartpole systems, where policies trained on a single environment are robust to shifts in the distribution of the context.
Facilitating Automated Online Consensus Building through Parallel Thinking
Mar 16, 2025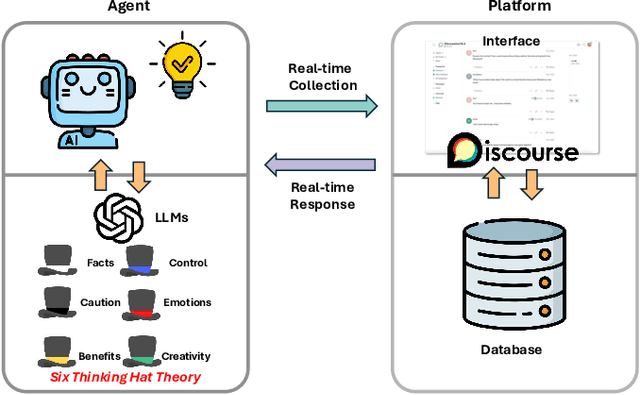

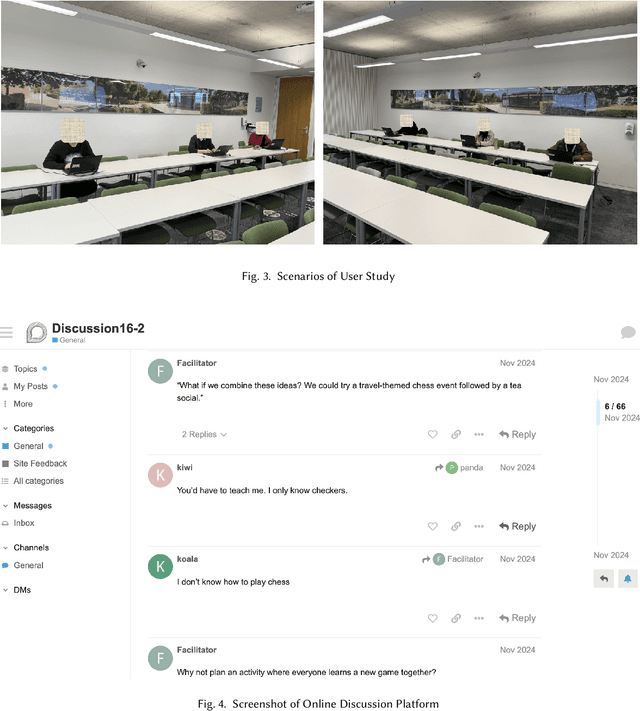
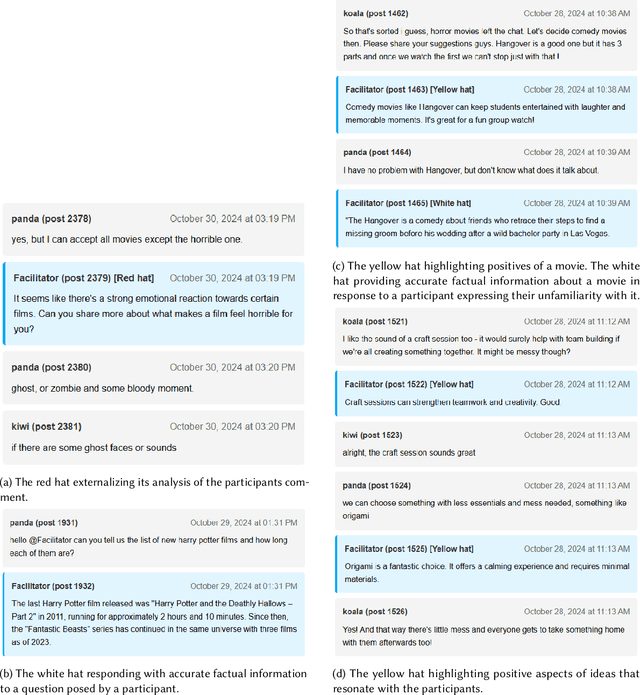
Consensus building is inherently challenging due to the diverse opinions held by stakeholders. Effective facilitation is crucial to support the consensus building process and enable efficient group decision making. However, the effectiveness of facilitation is often constrained by human factors such as limited experience and scalability. In this research, we propose a Parallel Thinking-based Facilitation Agent (PTFA) that facilitates online, text-based consensus building processes. The PTFA automatically collects textual posts and leverages large language models (LLMs) to perform all of the six distinct roles of the well-established Six Thinking Hats technique in parallel thinking. To illustrate the potential of PTFA, a pilot study was carried out and PTFA's ability in idea generation, emotional probing, and deeper analysis of ideas was demonstrated. Furthermore, a comprehensive dataset that contains not only the conversational content among the participants but also between the participants and the agent is constructed for future study.
Active Inference and Human--Computer Interaction
Dec 19, 2024



Active Inference is a closed-loop computational theoretical basis for understanding behaviour, based on agents with internal probabilistic generative models that encode their beliefs about how hidden states in their environment cause their sensations. We review Active Inference and how it could be applied to model the human-computer interaction loop. Active Inference provides a coherent framework for managing generative models of humans, their environments, sensors and interface components. It informs off-line design and supports real-time, online adaptation. It provides model-based explanations for behaviours observed in HCI, and new tools to measure important concepts such as agency and engagement. We discuss how Active Inference offers a new basis for a theory of interaction in HCI, tools for design of modern, complex sensor-based systems, and integration of artificial intelligence technologies, enabling it to cope with diversity in human users and contexts. We discuss the practical challenges in implementing such Active Inference-based systems.
Integrating LSTM and BERT for Long-Sequence Data Analysis in Intelligent Tutoring Systems
Apr 24, 2024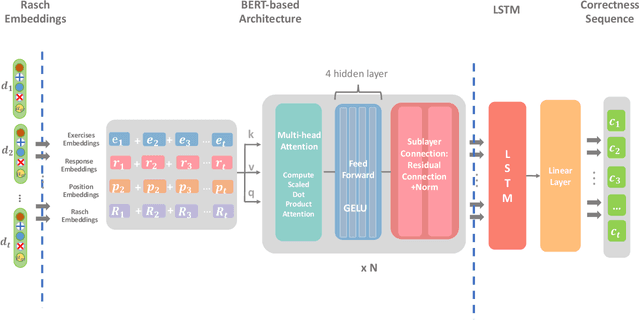
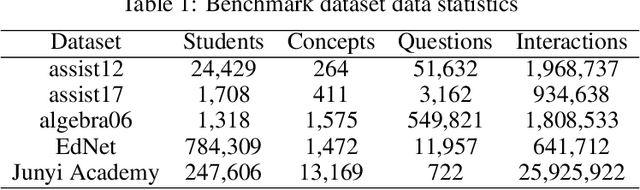
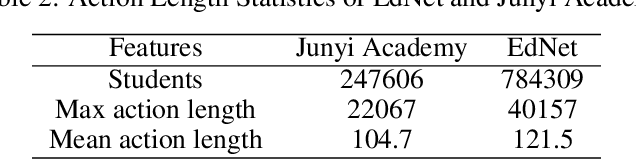
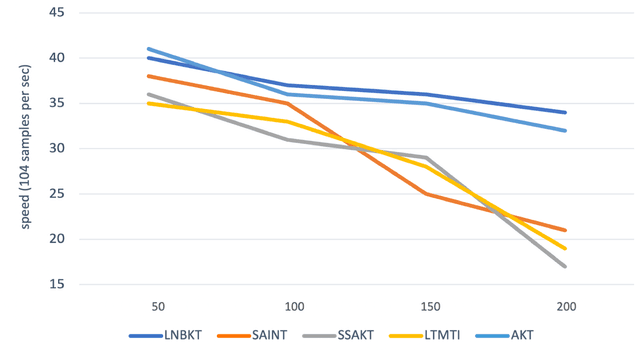
The field of Knowledge Tracing aims to understand how students learn and master knowledge over time by analyzing their historical behaviour data. To achieve this goal, many researchers have proposed Knowledge Tracing models that use data from Intelligent Tutoring Systems to predict students' subsequent actions. However, with the development of Intelligent Tutoring Systems, large-scale datasets containing long-sequence data began to emerge. Recent deep learning based Knowledge Tracing models face obstacles such as low efficiency, low accuracy, and low interpretability when dealing with large-scale datasets containing long-sequence data. To address these issues and promote the sustainable development of Intelligent Tutoring Systems, we propose a LSTM BERT-based Knowledge Tracing model for long sequence data processing, namely LBKT, which uses a BERT-based architecture with a Rasch model-based embeddings block to deal with different difficulty levels information and an LSTM block to process the sequential characteristic in students' actions. LBKT achieves the best performance on most benchmark datasets on the metrics of ACC and AUC. Additionally, an ablation study is conducted to analyse the impact of each component of LBKT's overall performance. Moreover, we used t-SNE as the visualisation tool to demonstrate the model's embedding strategy. The results indicate that LBKT is faster, more interpretable, and has a lower memory cost than the traditional deep learning based Knowledge Tracing methods.
Combinatorial Client-Master Multiagent Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing
Feb 18, 2024Recently, there has been an explosion of mobile applications that perform computationally intensive tasks such as video streaming, data mining, virtual reality, augmented reality, image processing, video processing, face recognition, and online gaming. However, user devices (UDs), such as tablets and smartphones, have a limited ability to perform the computation needs of the tasks. Mobile edge computing (MEC) has emerged as a promising technology to meet the increasing computing demands of UDs. Task offloading in MEC is a strategy that meets the demands of UDs by distributing tasks between UDs and MEC servers. Deep reinforcement learning (DRL) is gaining attention in task-offloading problems because it can adapt to dynamic changes and minimize online computational complexity. However, the various types of continuous and discrete resource constraints on UDs and MEC servers pose challenges to the design of an efficient DRL-based task-offloading strategy. Existing DRL-based task-offloading algorithms focus on the constraints of the UDs, assuming the availability of enough storage resources on the server. Moreover, existing multiagent DRL (MADRL)--based task-offloading algorithms are homogeneous agents and consider homogeneous constraints as a penalty in their reward function. We proposed a novel combinatorial client-master MADRL (CCM\_MADRL) algorithm for task offloading in MEC (CCM\_MADRL\_MEC) that enables UDs to decide their resource requirements and the server to make a combinatorial decision based on the requirements of the UDs. CCM\_MADRL\_MEC is the first MADRL in task offloading to consider server storage capacity in addition to the constraints in the UDs. By taking advantage of the combinatorial action selection, CCM\_MADRL\_MEC has shown superior convergence over existing MADDPG and heuristic algorithms.
From Intelligent Agents to Trustworthy Human-Centred Multiagent Systems
Oct 05, 2022
The Agents, Interaction and Complexity research group at the University of Southampton has a long track record of research in multiagent systems (MAS). We have made substantial scientific contributions across learning in MAS, game-theoretic techniques for coordinating agent systems, and formal methods for representation and reasoning. We highlight key results achieved by the group and elaborate on recent work and open research challenges in developing trustworthy autonomous systems and deploying human-centred AI systems that aim to support societal good.
* Appears in the Special Issue on Multi-Agent Systems Research in the United Kingdom
Evaluating Bayesian Model Visualisations
Jan 10, 2022


Probabilistic models inform an increasingly broad range of business and policy decisions ultimately made by people. Recent algorithmic, computational, and software framework development progress facilitate the proliferation of Bayesian probabilistic models, which characterise unobserved parameters by their joint distribution instead of point estimates. While they can empower decision makers to explore complex queries and to perform what-if-style conditioning in theory, suitable visualisations and interactive tools are needed to maximise users' comprehension and rational decision making under uncertainty. In this paper, propose a protocol for quantitative evaluation of Bayesian model visualisations and introduce a software framework implementing this protocol to support standardisation in evaluation practice and facilitate reproducibility. We illustrate the evaluation and analysis workflow on a user study that explores whether making Boxplots and Hypothetical Outcome Plots interactive can increase comprehension or rationality and conclude with design guidelines for researchers looking to conduct similar studies in the future.
Mechanism Design for Efficient Online and Offline Allocation of Electric Vehicles to Charging Stations
Jul 19, 2020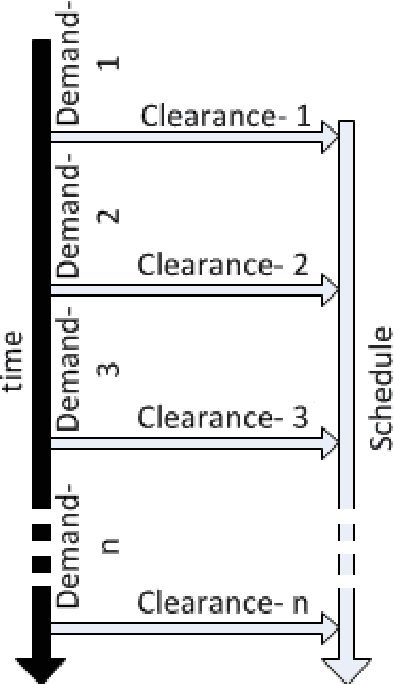

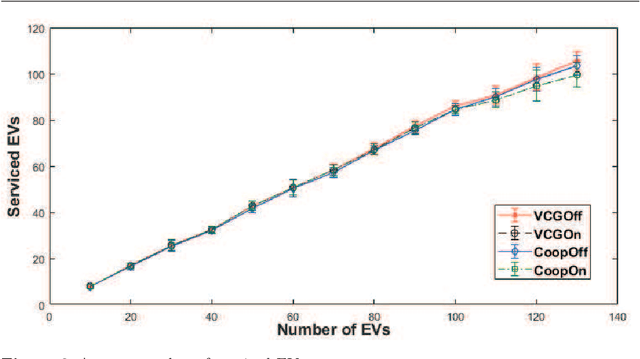
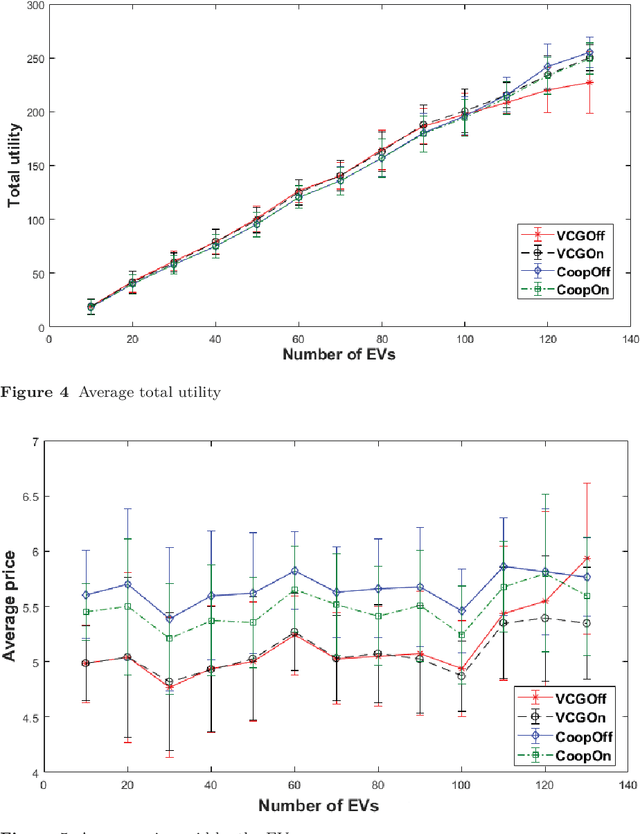
We study the problem of allocating Electric Vehicles (EVs) to charging stations and scheduling their charging. We develop offline and online solutions that treat EV users as self-interested agents that aim to maximise their profit and minimise the impact on their schedule. We formulate the problem of the optimal EV to charging station allocation as a Mixed Integer Programming (MIP) one and we propose two pricing mechanisms: A fixed-price one, and another that is based on the well known Vickrey-Clark-Groves (VCG) mechanism. Later, we develop online solutions that incrementally call the MIP-based algorithm. We empirically evaluate our mechanisms and we observe that both scale well. Moreover, the VCG mechanism services on average $1.5\%$ more EVs than the fixed-price one. In addition, when the stations get congested, VCG leads to higher prices for the EVs and higher profit for the stations, but lower utility for the EVs. However, we theoretically prove that the VCG mechanism guarantees truthful reporting of the EVs' preferences. In contrast, the fixed-price one is vulnerable to agents' strategic behaviour as non-truthful EVs can charge in place of truthful ones. Finally, we observe that the online algorithms are on average at $98\%$ of the optimal in EV satisfaction.
neuralRank: Searching and ranking ANN-based model repositories
Mar 02, 2019
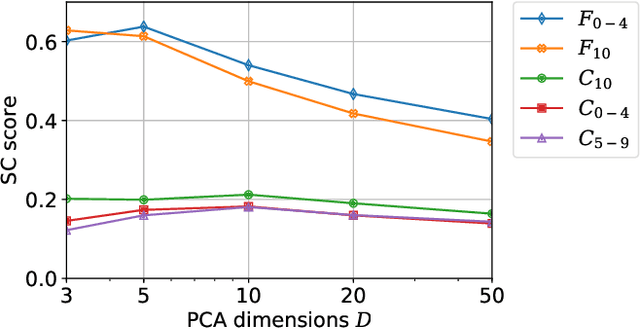
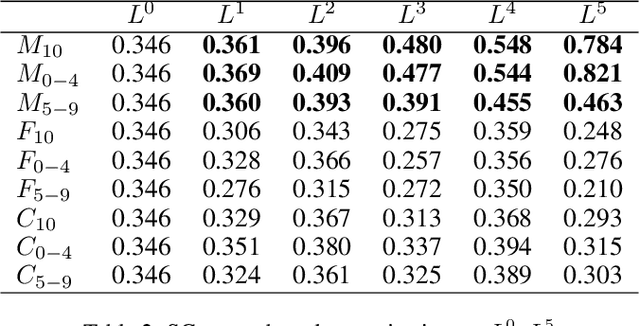
Widespread applications of deep learning have led to a plethora of pre-trained neural network models for common tasks. Such models are often adapted from other models via transfer learning. The models may have varying training sets, training algorithms, network architectures, and hyper-parameters. For a given application, what isthe most suitable model in a model repository? This is a critical question for practical deployments but it has not received much attention. This paper introduces the novel problem of searching and ranking models based on suitability relative to a target dataset and proposes a ranking algorithm called \textit{neuralRank}. The key idea behind this algorithm is to base model suitability on the discriminating power of a model, using a novel metric to measure it. With experimental results on the MNIST, Fashion, and CIFAR10 datasets, we demonstrate that (1) neuralRank is independent of the domain, the training set, or the network architecture and (2) that the models ranked highly by neuralRank ranking tend to have higher model accuracy in practice.