 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSinkhorn: IO-Aware Entropic Optimal Transport
Feb 03, 2026Entropic optimal transport (EOT) via Sinkhorn iterations is widely used in modern machine learning, yet GPU solvers remain inefficient at scale. Tensorized implementations suffer quadratic HBM traffic from dense $n\times m$ interactions, while existing online backends avoid storing dense matrices but still rely on generic tiled map-reduce reduction kernels with limited fusion. We present \textbf{FlashSinkhorn}, an IO-aware EOT solver for squared Euclidean cost that rewrites stabilized log-domain Sinkhorn updates as row-wise LogSumExp reductions of biased dot-product scores, the same normalization as transformer attention. This enables FlashAttention-style fusion and tiling: fused Triton kernels stream tiles through on-chip SRAM and update dual potentials in a single pass, substantially reducing HBM IO per iteration while retaining linear-memory operations. We further provide streaming kernels for transport application, enabling scalable first- and second-order optimization. On A100 GPUs, FlashSinkhorn achieves up to $32\times$ forward-pass and $161\times$ end-to-end speedups over state-of-the-art online baselines on point-cloud OT, improves scalability on OT-based downstream tasks. For reproducibility, we release an open-source implementation at https://github.com/ot-triton-lab/ot_triton.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
neuralRank: Searching and ranking ANN-based model repositories
Mar 02, 2019
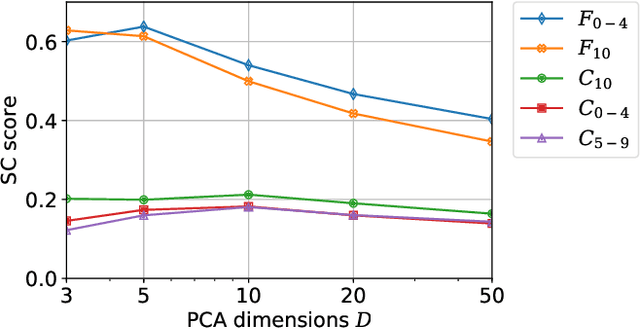
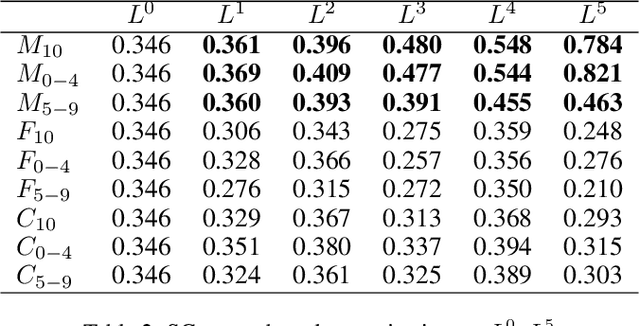
Widespread applications of deep learning have led to a plethora of pre-trained neural network models for common tasks. Such models are often adapted from other models via transfer learning. The models may have varying training sets, training algorithms, network architectures, and hyper-parameters. For a given application, what isthe most suitable model in a model repository? This is a critical question for practical deployments but it has not received much attention. This paper introduces the novel problem of searching and ranking models based on suitability relative to a target dataset and proposes a ranking algorithm called \textit{neuralRank}. The key idea behind this algorithm is to base model suitability on the discriminating power of a model, using a novel metric to measure it. With experimental results on the MNIST, Fashion, and CIFAR10 datasets, we demonstrate that (1) neuralRank is independent of the domain, the training set, or the network architecture and (2) that the models ranked highly by neuralRank ranking tend to have higher model accuracy in practice.