 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLandslide Hazard Mapping with Geospatial Foundation Models: Geographical Generalizability, Data Scarcity, and Band Adaptability
Nov 06, 2025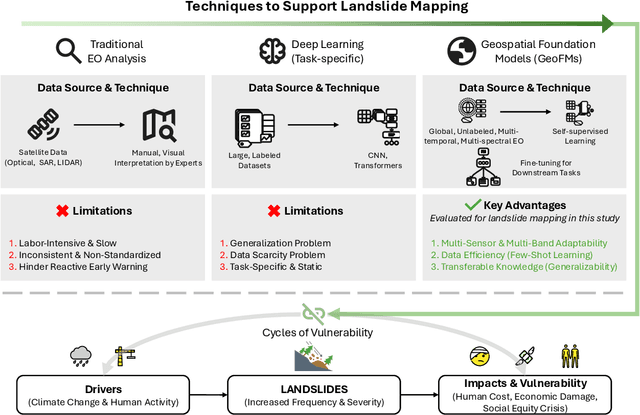
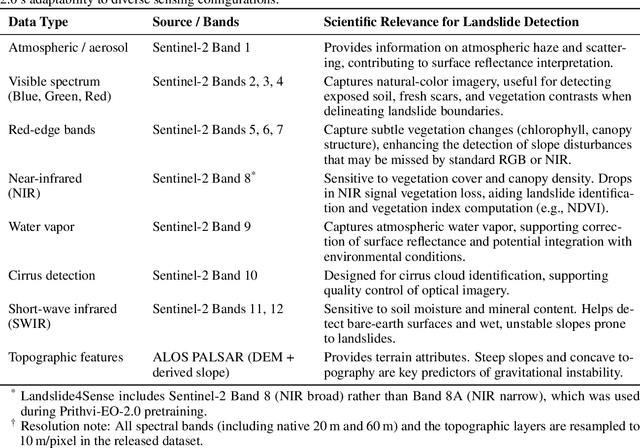
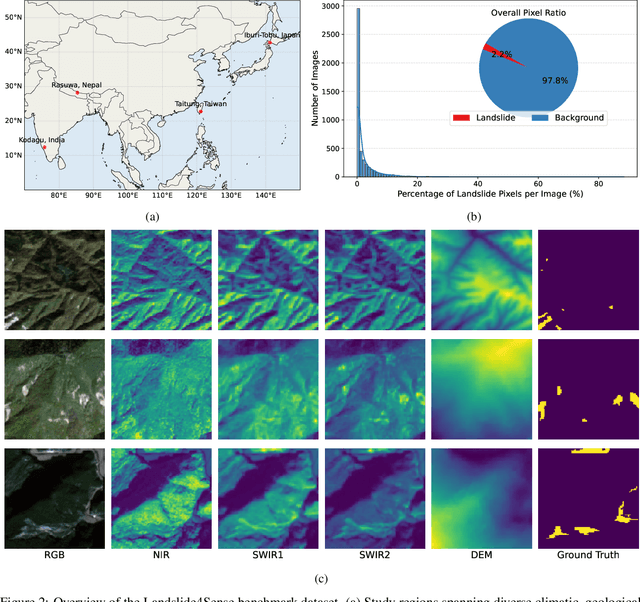
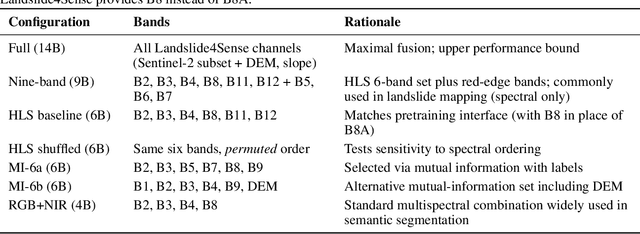
Landslides cause severe damage to lives, infrastructure, and the environment, making accurate and timely mapping essential for disaster preparedness and response. However, conventional deep learning models often struggle when applied across different sensors, regions, or under conditions of limited training data. To address these challenges, we present a three-axis analytical framework of sensor, label, and domain for adapting geospatial foundation models (GeoFMs), focusing on Prithvi-EO-2.0 for landslide mapping. Through a series of experiments, we show that it consistently outperforms task-specific CNNs (U-Net, U-Net++), vision transformers (Segformer, SwinV2-B), and other GeoFMs (TerraMind, SatMAE). The model, built on global pretraining, self-supervision, and adaptable fine-tuning, proved resilient to spectral variation, maintained accuracy under label scarcity, and generalized more reliably across diverse datasets and geographic settings. Alongside these strengths, we also highlight remaining challenges such as computational cost and the limited availability of reusable AI-ready training data for landslide research. Overall, our study positions GeoFMs as a step toward more robust and scalable approaches for landslide risk reduction and environmental monitoring.
Finetuning AI Foundation Models to Develop Subgrid-Scale Parameterizations: A Case Study on Atmospheric Gravity Waves
Sep 04, 2025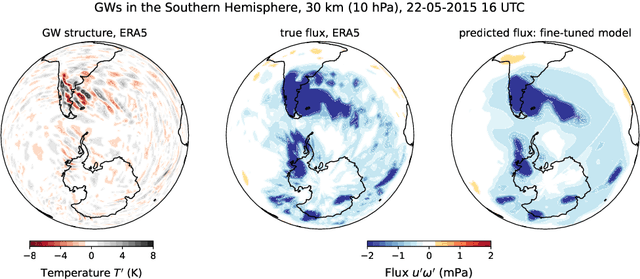



Global climate models parameterize a range of atmospheric-oceanic processes like gravity waves, clouds, moist convection, and turbulence that cannot be sufficiently resolved. These subgrid-scale closures for unresolved processes are a leading source of model uncertainty. Here, we present a new approach to developing machine learning parameterizations of small-scale climate processes by fine-tuning a pre-trained AI foundation model (FM). FMs are largely unexplored in climate research. A pre-trained encoder-decoder from a 2.3 billion parameter FM (NASA and IBM Research's Prithvi WxC) -- which contains a latent probabilistic representation of atmospheric evolution -- is fine-tuned (or reused) to create a deep learning parameterization for atmospheric gravity waves (GWs). The parameterization captures GW effects for a coarse-resolution climate model by learning the fluxes from an atmospheric reanalysis with 10 times finer resolution. A comparison of monthly averages and instantaneous evolution with a machine learning model baseline (an Attention U-Net) reveals superior predictive performance of the FM parameterization throughout the atmosphere, even in regions excluded from pre-training. This performance boost is quantified using the Hellinger distance, which is 0.11 for the baseline and 0.06 for the fine-tuned model. Our findings emphasize the versatility and reusability of FMs, which could be used to accomplish a range of atmosphere- and climate-related applications, leading the way for the creation of observations-driven and physically accurate parameterizations for more earth-system processes.
WxC-Bench: A Novel Dataset for Weather and Climate Downstream Tasks
Dec 03, 2024



High-quality machine learning (ML)-ready datasets play a foundational role in developing new artificial intelligence (AI) models or fine-tuning existing models for scientific applications such as weather and climate analysis. Unfortunately, despite the growing development of new deep learning models for weather and climate, there is a scarcity of curated, pre-processed machine learning (ML)-ready datasets. Curating such high-quality datasets for developing new models is challenging particularly because the modality of the input data varies significantly for different downstream tasks addressing different atmospheric scales (spatial and temporal). Here we introduce WxC-Bench (Weather and Climate Bench), a multi-modal dataset designed to support the development of generalizable AI models for downstream use-cases in weather and climate research. WxC-Bench is designed as a dataset of datasets for developing ML-models for a complex weather and climate system, addressing selected downstream tasks as machine learning phenomenon. WxC-Bench encompasses several atmospheric processes from meso-$\beta$ (20 - 200 km) scale to synoptic scales (2500 km), such as aviation turbulence, hurricane intensity and track monitoring, weather analog search, gravity wave parameterization, and natural language report generation. We provide a comprehensive description of the dataset and also present a technical validation for baseline analysis. The dataset and code to prepare the ML-ready data have been made publicly available on Hugging Face -- https://huggingface.co/datasets/nasa-impact/WxC-Bench
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024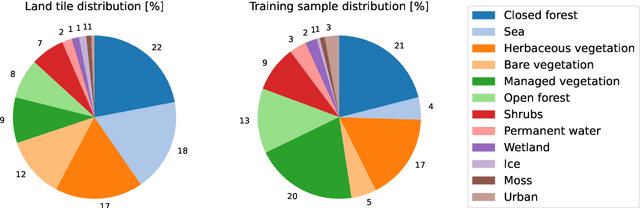
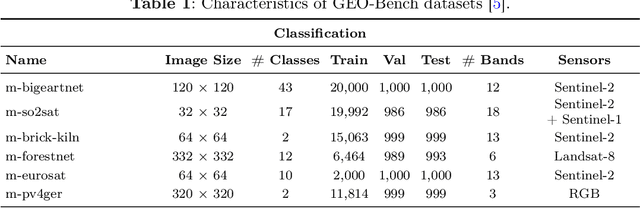
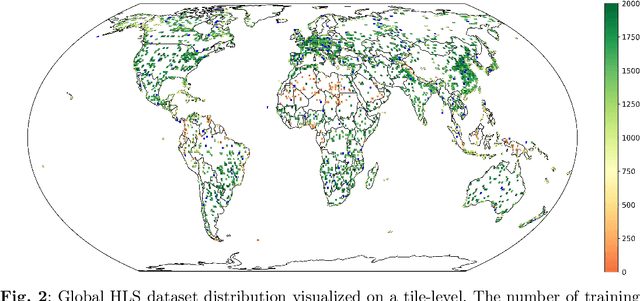
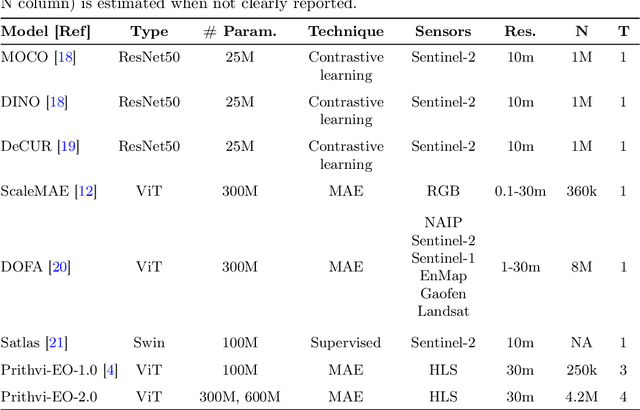
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Machine Learning Global Simulation of Nonlocal Gravity Wave Propagation
Jun 20, 2024Global climate models typically operate at a grid resolution of hundreds of kilometers and fail to resolve atmospheric mesoscale processes, e.g., clouds, precipitation, and gravity waves (GWs). Model representation of these processes and their sources is essential to the global circulation and planetary energy budget, but subgrid scale contributions from these processes are often only approximately represented in models using parameterizations. These parameterizations are subject to approximations and idealizations, which limit their capability and accuracy. The most drastic of these approximations is the "single-column approximation" which completely neglects the horizontal evolution of these processes, resulting in key biases in current climate models. With a focus on atmospheric GWs, we present the first-ever global simulation of atmospheric GW fluxes using machine learning (ML) models trained on the WINDSET dataset to emulate global GW emulation in the atmosphere, as an alternative to traditional single-column parameterizations. Using an Attention U-Net-based architecture trained on globally resolved GW momentum fluxes, we illustrate the importance and effectiveness of global nonlocality, when simulating GWs using data-driven schemes.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
AI Foundation Models for Weather and Climate: Applications, Design, and Implementation
Sep 20, 2023Machine learning and deep learning methods have been widely explored in understanding the chaotic behavior of the atmosphere and furthering weather forecasting. There has been increasing interest from technology companies, government institutions, and meteorological agencies in building digital twins of the Earth. Recent approaches using transformers, physics-informed machine learning, and graph neural networks have demonstrated state-of-the-art performance on relatively narrow spatiotemporal scales and specific tasks. With the recent success of generative artificial intelligence (AI) using pre-trained transformers for language modeling and vision with prompt engineering and fine-tuning, we are now moving towards generalizable AI. In particular, we are witnessing the rise of AI foundation models that can perform competitively on multiple domain-specific downstream tasks. Despite this progress, we are still in the nascent stages of a generalizable AI model for global Earth system models, regional climate models, and mesoscale weather models. Here, we review current state-of-the-art AI approaches, primarily from transformer and operator learning literature in the context of meteorology. We provide our perspective on criteria for success towards a family of foundation models for nowcasting and forecasting weather and climate predictions. We also discuss how such models can perform competitively on downstream tasks such as downscaling (super-resolution), identifying conditions conducive to the occurrence of wildfires, and predicting consequential meteorological phenomena across various spatiotemporal scales such as hurricanes and atmospheric rivers. In particular, we examine current AI methodologies and contend they have matured enough to design and implement a weather foundation model.
A Data-Driven Framework for Identifying Investment Opportunities in Private Equity
Apr 04, 2022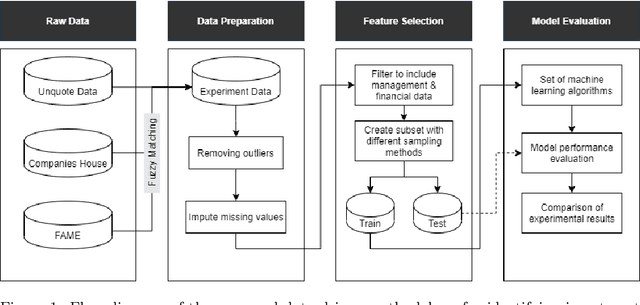
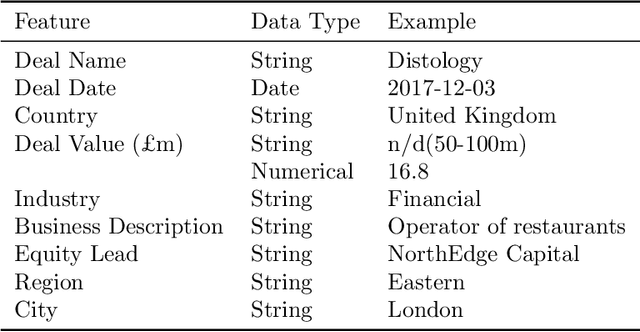
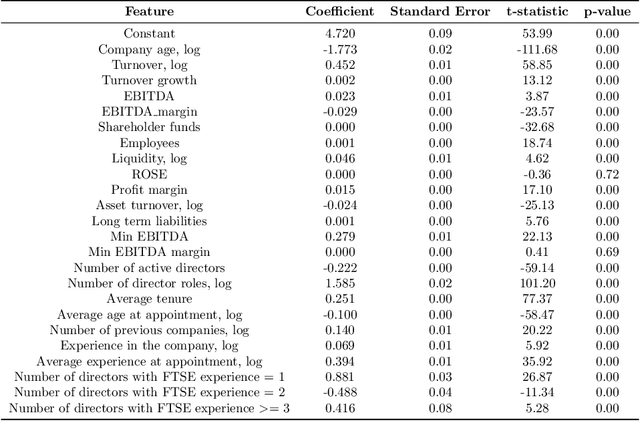
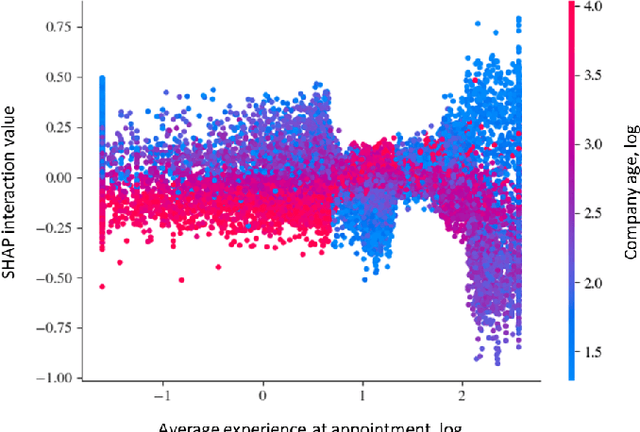
The core activity of a Private Equity (PE) firm is to invest into companies in order to provide the investors with profit, usually within 4-7 years. To invest into a company or not is typically done manually by looking at various performance indicators of the company and then making a decision often based on instinct. This process is rather unmanageable given the large number of companies to potentially invest. Moreover, as more data about company performance indicators becomes available and the number of different indicators one may want to consider increases, manual crawling and assessment of investment opportunities becomes inefficient and ultimately impossible. To address these issues, this paper proposes a framework for automated data-driven screening of investment opportunities and thus the recommendation of businesses to invest in. The framework draws on data from several sources to assess the financial and managerial position of a company, and then uses an explainable artificial intelligence (XAI) engine to suggest investment recommendations. The robustness of the model is validated using different AI algorithms, class imbalance-handling methods, and features extracted from the available data sources.
CLUE: Contextualised Unified Explainable Learning of User Engagement in Video Lectures
Jan 14, 2022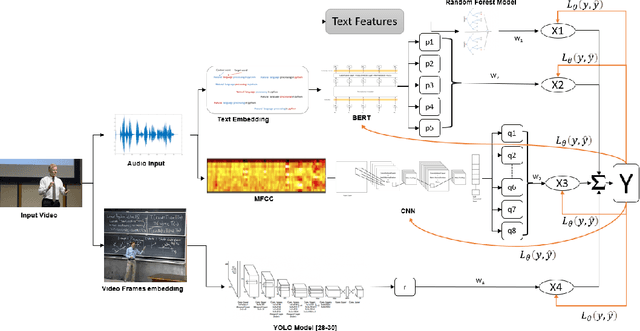
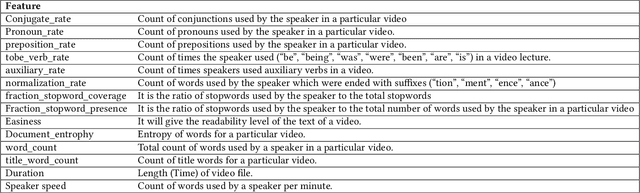
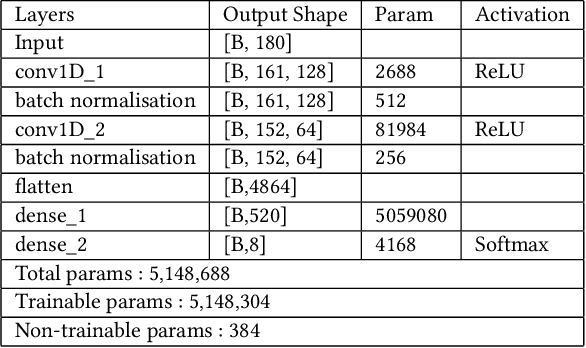
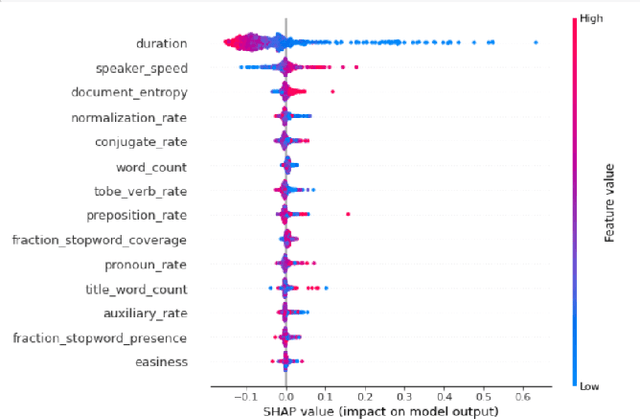
Predicting contextualised engagement in videos is a long-standing problem that has been popularly attempted by exploiting the number of views or the associated likes using different computational methods. The recent decade has seen a boom in online learning resources, and during the pandemic, there has been an exponential rise of online teaching videos without much quality control. The quality of the content could be improved if the creators could get constructive feedback on their content. Employing an army of domain expert volunteers to provide feedback on the videos might not scale. As a result, there has been a steep rise in developing computational methods to predict a user engagement score that is indicative of some form of possible user engagement, i.e., to what level a user would tend to engage with the content. A drawback in current methods is that they model various features separately, in a cascaded approach, that is prone to error propagation. Besides, most of them do not provide crucial explanations on how the creator could improve their content. In this paper, we have proposed a new unified model, CLUE for the educational domain, which learns from the features extracted from freely available public online teaching videos and provides explainable feedback on the video along with a user engagement score. Given the complexity of the task, our unified framework employs different pre-trained models working together as an ensemble of classifiers. Our model exploits various multi-modal features to model the complexity of language, context agnostic information, textual emotion of the delivered content, animation, speaker's pitch and speech emotions. Under a transfer learning setup, the overall model, in the unified space, is fine-tuned for downstream applications.