 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLUE: Contextualised Unified Explainable Learning of User Engagement in Video Lectures
Paper and Code
Jan 14, 2022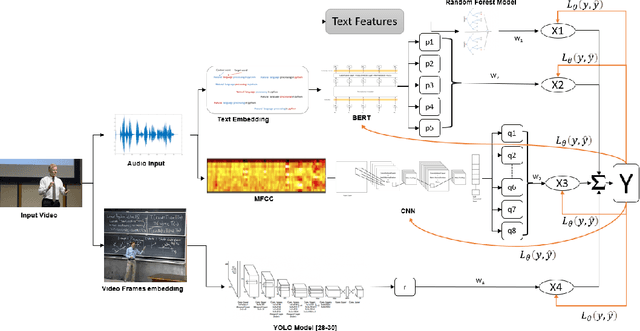
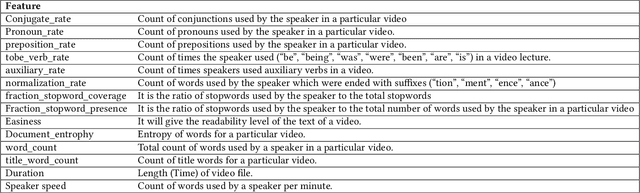
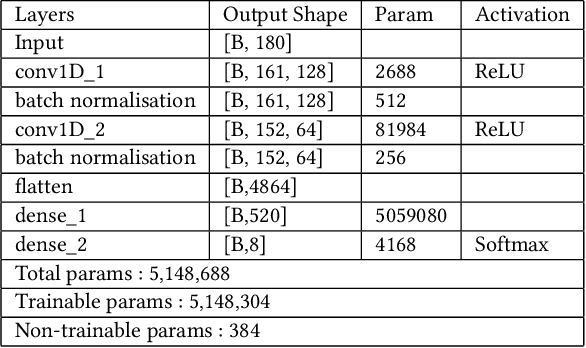
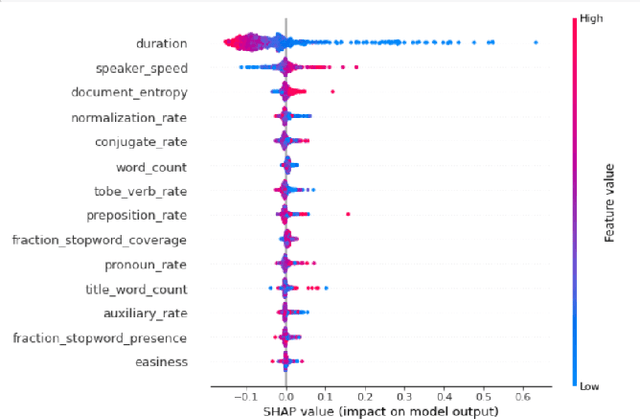
Predicting contextualised engagement in videos is a long-standing problem that has been popularly attempted by exploiting the number of views or the associated likes using different computational methods. The recent decade has seen a boom in online learning resources, and during the pandemic, there has been an exponential rise of online teaching videos without much quality control. The quality of the content could be improved if the creators could get constructive feedback on their content. Employing an army of domain expert volunteers to provide feedback on the videos might not scale. As a result, there has been a steep rise in developing computational methods to predict a user engagement score that is indicative of some form of possible user engagement, i.e., to what level a user would tend to engage with the content. A drawback in current methods is that they model various features separately, in a cascaded approach, that is prone to error propagation. Besides, most of them do not provide crucial explanations on how the creator could improve their content. In this paper, we have proposed a new unified model, CLUE for the educational domain, which learns from the features extracted from freely available public online teaching videos and provides explainable feedback on the video along with a user engagement score. Given the complexity of the task, our unified framework employs different pre-trained models working together as an ensemble of classifiers. Our model exploits various multi-modal features to model the complexity of language, context agnostic information, textual emotion of the delivered content, animation, speaker's pitch and speech emotions. Under a transfer learning setup, the overall model, in the unified space, is fine-tuned for downstream applications.