 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Graph Enhanced Memory-Augmented Retrieval for Long Context Modeling
Jun 12, 2026Long-context language modeling requires not only extending context windows but maintaining coherent understanding of entity states and relationships across thousands of tokens -- a challenge that semantic similarity alone cannot address. KGERMAR addresses this by constructing dynamic, context-specific knowledge graphs from input text during inference, enabling domain-adaptive retrieval that leverages both semantic similarity and explicit entity relationships. The framework performs real-time entity and relation extraction to build contextual knowledge graphs, then integrates graph-structural embeddings with textual semantics through a multi-component memory architecture. Three memory banks -- contextual, semantic, and structural -- are maintained with retrieval signals fused via learned weights to capture both surface-level semantics and deeper relational patterns. Evaluated on SlimPajama (84.7K training examples), WikiText-103 (4,358 examples), PG-19 (100 examples), and Proof-pile (46.3K examples), KGERMAR achieves up to 8.5\% lower perplexity and 2--2.5x better memory efficiency than memory-augmented baselines across context lengths from 1K to 32K tokens, with superior in-context learning performance across five NLU tasks. The dynamic knowledge graph construction approach advances memory-augmented language modeling by enabling domain-specific knowledge representation that adapts to input contexts rather than relying on fixed knowledge bases.
Mitigating Preference Leakage via Strict Estimator Separation for Normative Generative Ranking
Feb 25, 2026In Generative Information Retrieval (GenIR), the bottleneck has shifted from generation to the selection of candidates, particularly for normative criteria such as cultural relevance. Current LLM-as-a-Judge evaluations often suffer from circularity and preference leakage, where overlapping supervision and evaluation models inflate performance. We address this by formalising cultural relevance as a within-query ranking task and introducing a leakage-free two-judge framework that strictly separates supervision (Judge B) from evaluation (Judge A). On a new benchmark of 33,052 (NGR-33k) culturally grounded stories, we find that while classical baselines yield only modest gains, a dense bi-encoder distilled from a Judge-B-supervised Cross-Encoder is highly effective. Although the Cross-Encoder provides a strong supervision signal for distillation, the distilled BGE-M3 model substantially outperforms it under leakage-free Judge~A evaluation. We validate our framework on the human-curated Moral Stories dataset, showing strong alignment with human norms. Our results demonstrate that rigorous evaluator separation is a prerequisite for credible GenIR evaluation, proving that subtle cultural preferences can be distilled into efficient rankers without leakage.
CALM: Culturally Self-Aware Language Models
Jan 07, 2026Cultural awareness in language models is the capacity to understand and adapt to diverse cultural contexts. However, most existing approaches treat culture as static background knowledge, overlooking its dynamic and evolving nature. This limitation reduces their reliability in downstream tasks that demand genuine cultural sensitivity. In this work, we introduce CALM, a novel framework designed to endow language models with cultural self-awareness. CALM disentangles task semantics from explicit cultural concepts and latent cultural signals, shaping them into structured cultural clusters through contrastive learning. These clusters are then aligned via cross-attention to establish fine-grained interactions among related cultural features and are adaptively integrated through a Mixture-of-Experts mechanism along culture-specific dimensions. The resulting unified representation is fused with the model's original knowledge to construct a culturally grounded internal identity state, which is further enhanced through self-prompted reflective learning, enabling continual adaptation and self-correction. Extensive experiments conducted on multiple cross-cultural benchmark datasets demonstrate that CALM consistently outperforms state-of-the-art methods.
Flick: Few Labels Text Classification using K-Aware Intermediate Learning in Multi-Task Low-Resource Languages
Jun 12, 2025Training deep learning networks with minimal supervision has gained significant research attention due to its potential to reduce reliance on extensive labelled data. While self-training methods have proven effective in semi-supervised learning, they remain vulnerable to errors from noisy pseudo labels. Moreover, most recent approaches to the few-label classification problem are either designed for resource-rich languages such as English or involve complex cascading models that are prone to overfitting. To address the persistent challenge of few-label text classification in truly low-resource linguistic contexts, where existing methods often struggle with noisy pseudo-labels and domain adaptation, we propose Flick. Unlike prior methods that rely on generic multi-cluster pseudo-labelling or complex cascading architectures, Flick leverages the fundamental insight that distilling high-confidence pseudo-labels from a broader set of initial clusters can dramatically improve pseudo-label quality, particularly for linguistically diverse, low-resource settings. Flick introduces a novel pseudo-label refinement component, a departure from traditional pseudo-labelling strategies by identifying and leveraging top-performing pseudo-label clusters. This component specifically learns to distil highly reliable pseudo-labels from an initial broad set by focusing on single-cluster cohesion and leveraging an adaptive top-k selection mechanism. This targeted refinement process is crucial for mitigating the propagation of errors inherent in low-resource data, allowing for robust fine-tuning of pre-trained language models with only a handful of true labels. We demonstrate Flick's efficacy across 14 diverse datasets, encompassing challenging low-resource languages such as Arabic, Urdu, and Setswana, alongside English, showcasing its superior performance and adaptability.
DeepChest: Dynamic Gradient-Free Task Weighting for Effective Multi-Task Learning in Chest X-ray Classification
May 29, 2025



While Multi-Task Learning (MTL) offers inherent advantages in complex domains such as medical imaging by enabling shared representation learning, effectively balancing task contributions remains a significant challenge. This paper addresses this critical issue by introducing DeepChest, a novel, computationally efficient and effective dynamic task-weighting framework specifically designed for multi-label chest X-ray (CXR) classification. Unlike existing heuristic or gradient-based methods that often incur substantial overhead, DeepChest leverages a performance-driven weighting mechanism based on effective analysis of task-specific loss trends. Given a network architecture (e.g., ResNet18), our model-agnostic approach adaptively adjusts task importance without requiring gradient access, thereby significantly reducing memory usage and achieving a threefold increase in training speed. It can be easily applied to improve various state-of-the-art methods. Extensive experiments on a large-scale CXR dataset demonstrate that DeepChest not only outperforms state-of-the-art MTL methods by 7% in overall accuracy but also yields substantial reductions in individual task losses, indicating improved generalization and effective mitigation of negative transfer. The efficiency and performance gains of DeepChest pave the way for more practical and robust deployment of deep learning in critical medical diagnostic applications. The code is publicly available at https://github.com/youssefkhalil320/DeepChest-MTL
TAGS: A Test-Time Generalist-Specialist Framework with Retrieval-Augmented Reasoning and Verification
May 23, 2025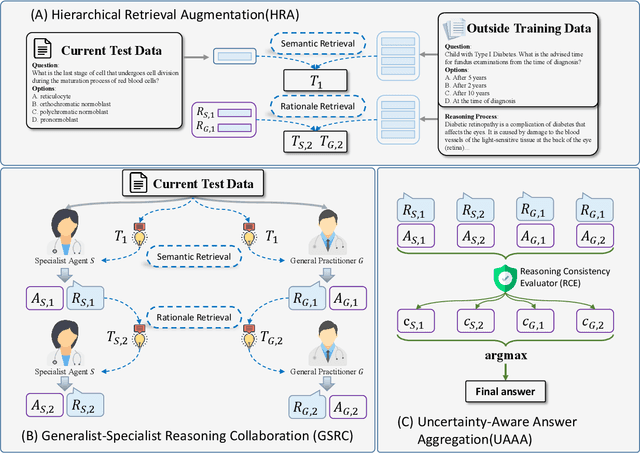
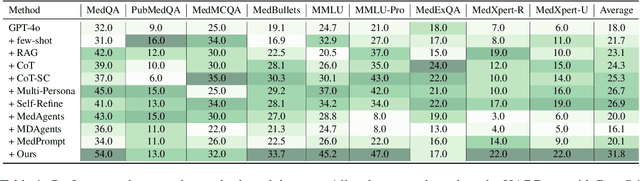
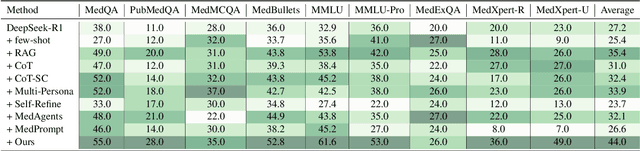
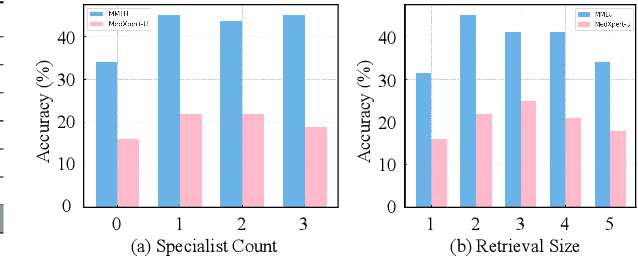
Recent advances such as Chain-of-Thought prompting have significantly improved large language models (LLMs) in zero-shot medical reasoning. However, prompting-based methods often remain shallow and unstable, while fine-tuned medical LLMs suffer from poor generalization under distribution shifts and limited adaptability to unseen clinical scenarios. To address these limitations, we present TAGS, a test-time framework that combines a broadly capable generalist with a domain-specific specialist to offer complementary perspectives without any model fine-tuning or parameter updates. To support this generalist-specialist reasoning process, we introduce two auxiliary modules: a hierarchical retrieval mechanism that provides multi-scale exemplars by selecting examples based on both semantic and rationale-level similarity, and a reliability scorer that evaluates reasoning consistency to guide final answer aggregation. TAGS achieves strong performance across nine MedQA benchmarks, boosting GPT-4o accuracy by 13.8%, DeepSeek-R1 by 16.8%, and improving a vanilla 7B model from 14.1% to 23.9%. These results surpass several fine-tuned medical LLMs, without any parameter updates. The code will be available at https://github.com/JianghaoWu/TAGS.
The Eye as a Window to Systemic Health: A Survey of Retinal Imaging from Classical Techniques to Oculomics
May 06, 2025The unique vascularized anatomy of the human eye, encased in the retina, provides an opportunity to act as a window for human health. The retinal structure assists in assessing the early detection, monitoring of disease progression and intervention for both ocular and non-ocular diseases. The advancement in imaging technology leveraging Artificial Intelligence has seized this opportunity to bridge the gap between the eye and human health. This track paves the way for unveiling systemic health insight from the ocular system and surrogating non-invasive markers for timely intervention and identification. The new frontiers of oculomics in ophthalmology cover both ocular and systemic diseases, and getting more attention to explore them. In this survey paper, we explore the evolution of retinal imaging techniques, the dire need for the integration of AI-driven analysis, and the shift of retinal imaging from classical techniques to oculomics. We also discuss some hurdles that may be faced in the progression of oculomics, highlighting the research gaps and future directions.
Less but Better: Parameter-Efficient Fine-Tuning of Large Language Models for Personality Detection
Apr 07, 2025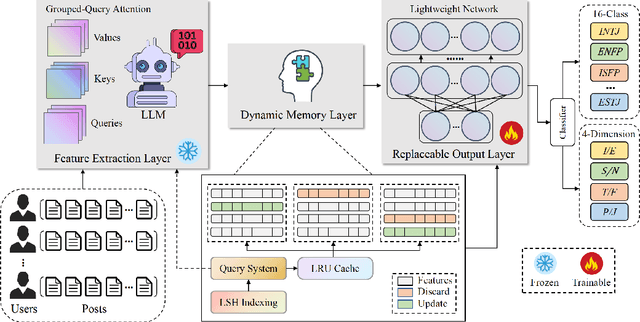
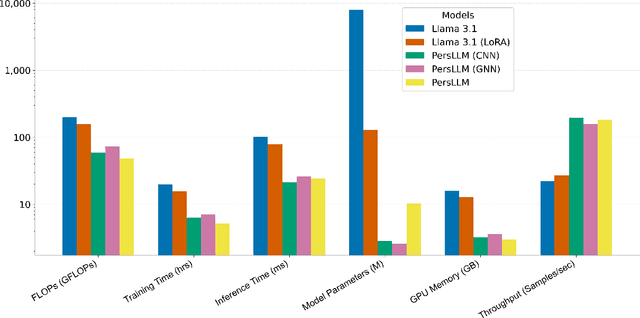
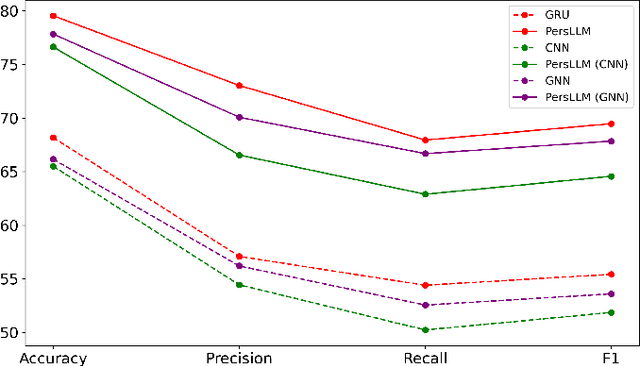
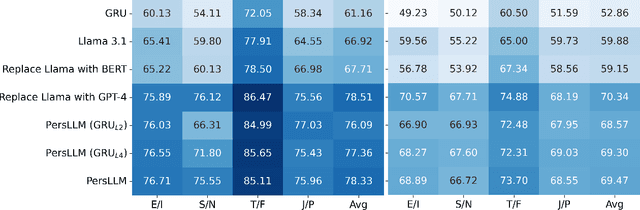
Personality detection automatically identifies an individual's personality from various data sources, such as social media texts. However, as the parameter scale of language models continues to grow, the computational cost becomes increasingly difficult to manage. Fine-tuning also grows more complex, making it harder to justify the effort and reliably predict outcomes. We introduce a novel parameter-efficient fine-tuning framework, PersLLM, to address these challenges. In PersLLM, a large language model (LLM) extracts high-dimensional representations from raw data and stores them in a dynamic memory layer. PersLLM then updates the downstream layers with a replaceable output network, enabling flexible adaptation to various personality detection scenarios. By storing the features in the memory layer, we eliminate the need for repeated complex computations by the LLM. Meanwhile, the lightweight output network serves as a proxy for evaluating the overall effectiveness of the framework, improving the predictability of results. Experimental results on key benchmark datasets like Kaggle and Pandora show that PersLLM significantly reduces computational cost while maintaining competitive performance and strong adaptability.
LL4G: Self-Supervised Dynamic Optimization for Graph-Based Personality Detection
Apr 02, 2025Graph-based personality detection constructs graph structures from textual data, particularly social media posts. Current methods often struggle with sparse or noisy data and rely on static graphs, limiting their ability to capture dynamic changes between nodes and relationships. This paper introduces LL4G, a self-supervised framework leveraging large language models (LLMs) to optimize graph neural networks (GNNs). LLMs extract rich semantic features to generate node representations and to infer explicit and implicit relationships. The graph structure adaptively adds nodes and edges based on input data, continuously optimizing itself. The GNN then uses these optimized representations for joint training on node reconstruction, edge prediction, and contrastive learning tasks. This integration of semantic and structural information generates robust personality profiles. Experimental results on Kaggle and Pandora datasets show LL4G outperforms state-of-the-art models.
Enforcing Consistency and Fairness in Multi-level Hierarchical Classification with a Mask-based Output Layer
Mar 19, 2025Traditional Multi-level Hierarchical Classification (MLHC) classifiers often rely on backbone models with $n$ independent output layers. This structure tends to overlook the hierarchical relationships between classes, leading to inconsistent predictions that violate the underlying taxonomy. Additionally, once a backbone architecture for an MLHC classifier is selected, adapting the model to accommodate new tasks can be challenging. For example, incorporating fairness to protect sensitive attributes within a hierarchical classifier necessitates complex adjustments to maintain the class hierarchy while enforcing fairness constraints. In this paper, we extend this concept to hierarchical classification by introducing a fair, model-agnostic layer designed to enforce taxonomy and optimize specific objectives, including consistency, fairness, and exact match. Our evaluations demonstrate that the proposed layer not only improves the fairness of predictions but also enforces the taxonomy, resulting in consistent predictions and superior performance. Compared to Large Language Models (LLMs) employing in-processing de-biasing techniques and models without any bias correction, our approach achieves better outcomes in both fairness and accuracy, making it particularly valuable in sectors like e-commerce, healthcare, and education, where predictive reliability is crucial.