 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Systematic Relational Reasoning with Large Language and Reasoning Models
Mar 30, 2025

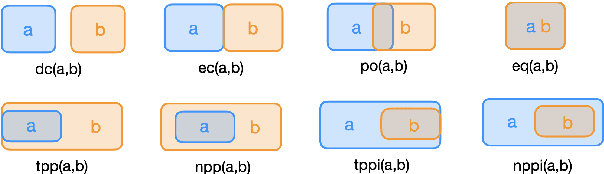

Large Language Models (LLMs) have been found to struggle with systematic reasoning. Even on tasks where they appear to perform well, their performance often depends on shortcuts, rather than on genuine reasoning abilities, leading them to collapse on out-of-distribution examples. Post-training strategies based on reinforcement learning and chain-of-thought prompting have recently been hailed as a step change. However, little is still known about the potential of the resulting ``Large Reasoning Models'' (LRMs) beyond problem solving in mathematics and programming, where finding genuine out-of-distribution problems can be difficult. In this paper, we focus on tasks that require systematic reasoning about relational compositions, especially for qualitative spatial and temporal reasoning. These tasks allow us to control the difficulty of problem instances, and measure in a precise way to what extent models can generalise. We find that that the considered LLMs and LRMs overall perform poorly overall, albeit better than random chance.
Modelling Multi-modal Cross-interaction for ML-FSIC Based on Local Feature Selection
Dec 18, 2024
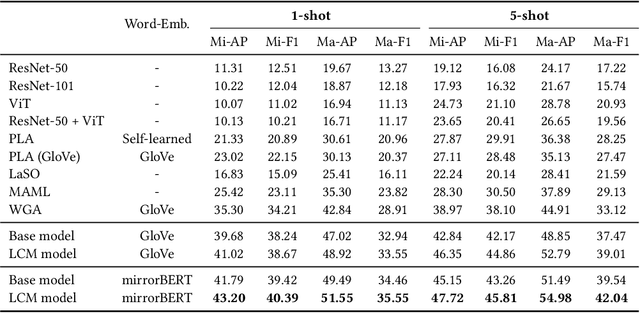

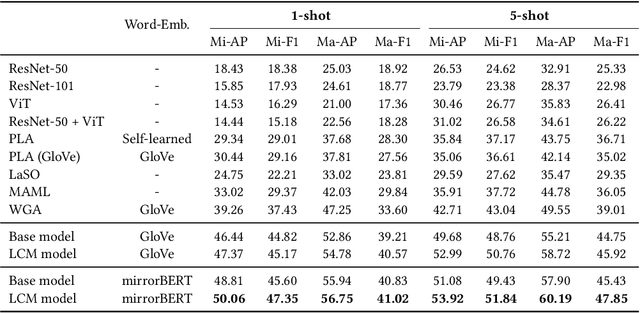
The aim of multi-label few-shot image classification (ML-FSIC) is to assign semantic labels to images, in settings where only a small number of training examples are available for each label. A key feature of the multi-label setting is that images often have several labels, which typically refer to objects appearing in different regions of the image. When estimating label prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data and the noisy nature of local features make this highly challenging. As a solution, we propose a strategy in which label prototypes are gradually refined. First, we initialize the prototypes using word embeddings, which allows us to leverage prior knowledge about the meaning of the labels. Second, taking advantage of these initial prototypes, we then use a Loss Change Measurement~(LCM) strategy to select the local features from the training images (i.e.\ the support set) that are most likely to be representative of a given label. Third, we construct the final prototype of the label by aggregating these representative local features using a multi-modal cross-interaction mechanism, which again relies on the initial word embedding-based prototypes. Experiments on COCO, PASCAL VOC, NUS-WIDE, and iMaterialist show that our model substantially improves the current state-of-the-art.
Systematic Reasoning About Relational Domains With Graph Neural Networks
Jul 24, 2024



Developing models that can learn to reason is a notoriously challenging problem. We focus on reasoning in relational domains, where the use of Graph Neural Networks (GNNs) seems like a natural choice. However, previous work on reasoning with GNNs has shown that such models tend to fail when presented with test examples that require longer inference chains than those seen during training. This suggests that GNNs lack the ability to generalize from training examples in a systematic way, which would fundamentally limit their reasoning abilities. A common solution is to instead rely on neuro-symbolic methods, which are capable of reasoning in a systematic way by design. Unfortunately, the scalability of such methods is often limited and they tend to rely on overly strong assumptions, e.g.\ that queries can be answered by inspecting a single relational path. In this paper, we revisit the idea of reasoning with GNNs, showing that systematic generalization is possible as long as the right inductive bias is provided. In particular, we argue that node embeddings should be treated as epistemic states and that GNN should be parameterised accordingly. We propose a simple GNN architecture which is based on this view and show that it is capable of achieving state-of-the-art results. We furthermore introduce a benchmark which requires models to aggregate evidence from multiple relational paths. We show that existing neuro-symbolic approaches fail on this benchmark, whereas our considered GNN model learns to reason accurately.
Differentiable Reasoning about Knowledge Graphs with Region-based Graph Neural Networks
Jun 13, 2024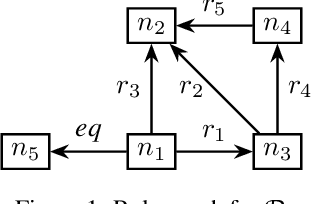

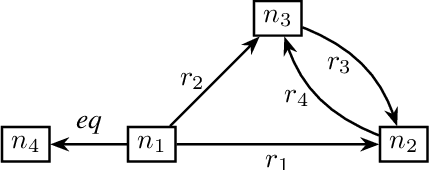

Methods for knowledge graph (KG) completion need to capture semantic regularities and use these regularities to infer plausible knowledge that is not explicitly stated. Most embedding-based methods are opaque in the kinds of regularities they can capture, although region-based KG embedding models have emerged as a more transparent alternative. By modeling relations as geometric regions in high-dimensional vector spaces, such models can explicitly capture semantic regularities in terms of the spatial arrangement of these regions. Unfortunately, existing region-based approaches are severely limited in the kinds of rules they can capture. We argue that this limitation arises because the considered regions are defined as the Cartesian product of two-dimensional regions. As an alternative, in this paper, we propose RESHUFFLE, a simple model based on ordering constraints that can faithfully capture a much larger class of rule bases than existing approaches. Moreover, the embeddings in our framework can be learned by a monotonic Graph Neural Network (GNN), which effectively acts as a differentiable rule base. This approach has the important advantage that embeddings can be easily updated as new knowledge is added to the KG. At the same time, since the resulting representations can be used similarly to standard KG embeddings, our approach is significantly more efficient than existing approaches to differentiable reasoning.
Ontology Completion with Natural Language Inference and Concept Embeddings: An Analysis
Mar 25, 2024We consider the problem of finding plausible knowledge that is missing from a given ontology, as a generalisation of the well-studied taxonomy expansion task. One line of work treats this task as a Natural Language Inference (NLI) problem, thus relying on the knowledge captured by language models to identify the missing knowledge. Another line of work uses concept embeddings to identify what different concepts have in common, taking inspiration from cognitive models for category based induction. These two approaches are intuitively complementary, but their effectiveness has not yet been compared. In this paper, we introduce a benchmark for evaluating ontology completion methods and thoroughly analyse the strengths and weaknesses of both approaches. We find that both approaches are indeed complementary, with hybrid strategies achieving the best overall results. We also find that the task is highly challenging for Large Language Models, even after fine-tuning.
Modelling Commonsense Commonalities with Multi-Facet Concept Embeddings
Mar 25, 2024Concept embeddings offer a practical and efficient mechanism for injecting commonsense knowledge into downstream tasks. Their core purpose is often not to predict the commonsense properties of concepts themselves, but rather to identify commonalities, i.e.\ sets of concepts which share some property of interest. Such commonalities are the basis for inductive generalisation, hence high-quality concept embeddings can make learning easier and more robust. Unfortunately, standard embeddings primarily reflect basic taxonomic categories, making them unsuitable for finding commonalities that refer to more specific aspects (e.g.\ the colour of objects or the materials they are made of). In this paper, we address this limitation by explicitly modelling the different facets of interest when learning concept embeddings. We show that this leads to embeddings which capture a more diverse range of commonsense properties, and consistently improves results in downstream tasks such as ultra-fine entity typing and ontology completion.
Ranking Entities along Conceptual Space Dimensions with LLMs: An Analysis of Fine-Tuning Strategies
Feb 23, 2024


Conceptual spaces represent entities in terms of their primitive semantic features. Such representations are highly valuable but they are notoriously difficult to learn, especially when it comes to modelling perceptual and subjective features. Distilling conceptual spaces from Large Language Models (LLMs) has recently emerged as a promising strategy. However, existing work has been limited to probing pre-trained LLMs using relatively simple zero-shot strategies. We focus in particular on the task of ranking entities according to a given conceptual space dimension. Unfortunately, we cannot directly fine-tune LLMs on this task, because ground truth rankings for conceptual space dimensions are rare. We therefore use more readily available features as training data and analyse whether the ranking capabilities of the resulting models transfer to perceptual and subjective features. We find that this is indeed the case, to some extent, but having perceptual and subjective features in the training data seems essential for achieving the best results. We furthermore find that pointwise ranking strategies are competitive against pairwise approaches, in defiance of common wisdom.
Capturing Knowledge Graphs and Rules with Octagon Embeddings
Jan 29, 2024



Region based knowledge graph embeddings represent relations as geometric regions. This has the advantage that the rules which are captured by the model are made explicit, making it straightforward to incorporate prior knowledge and to inspect learned models. Unfortunately, existing approaches are severely restricted in their ability to model relational composition, and hence also their ability to model rules, thus failing to deliver on the main promise of region based models. With the aim of addressing these limitations, we investigate regions which are composed of axis-aligned octagons. Such octagons are particularly easy to work with, as intersections and compositions can be straightforwardly computed, while they are still sufficiently expressive to model arbitrary knowledge graphs. Among others, we also show that our octagon embeddings can properly capture a non-trivial class of rule bases. Finally, we show that our model achieves competitive experimental results.
Entity or Relation Embeddings? An Analysis of Encoding Strategies for Relation Extraction
Dec 18, 2023



Relation extraction is essentially a text classification problem, which can be tackled by fine-tuning a pre-trained language model (LM). However, a key challenge arises from the fact that relation extraction cannot straightforwardly be reduced to sequence or token classification. Existing approaches therefore solve the problem in an indirect way: they fine-tune an LM to learn embeddings of the head and tail entities, and then predict the relationship from these entity embeddings. Our hypothesis in this paper is that relation extraction models can be improved by capturing relationships in a more direct way. In particular, we experiment with appending a prompt with a [MASK] token, whose contextualised representation is treated as a relation embedding. While, on its own, this strategy significantly underperforms the aforementioned approach, we find that the resulting relation embeddings are highly complementary to what is captured by embeddings of the head and tail entity. By jointly considering both types of representations, we end up with a simple model that outperforms the state-of-the-art across several relation extraction benchmarks.
What do Deck Chairs and Sun Hats Have in Common? Uncovering Shared Properties in Large Concept Vocabularies
Oct 23, 2023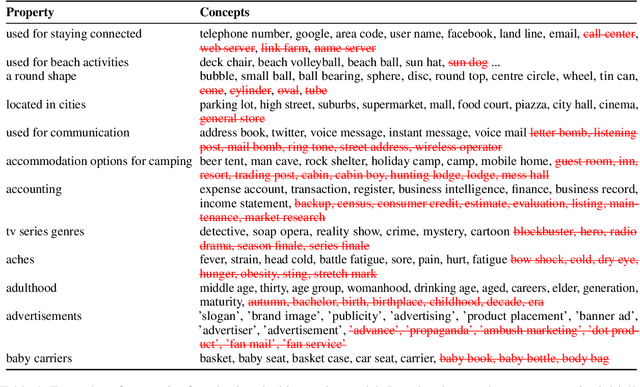
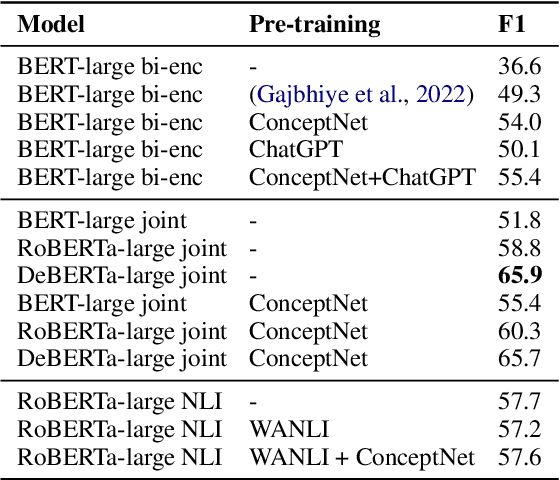
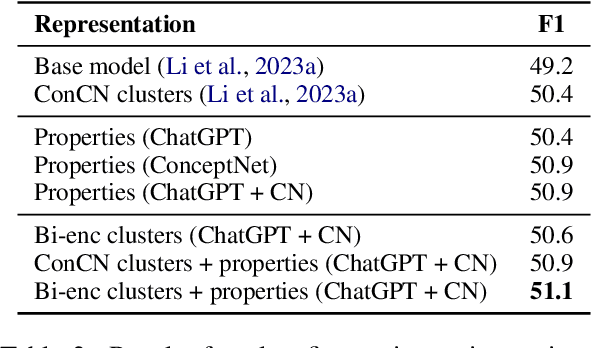

Concepts play a central role in many applications. This includes settings where concepts have to be modelled in the absence of sentence context. Previous work has therefore focused on distilling decontextualised concept embeddings from language models. But concepts can be modelled from different perspectives, whereas concept embeddings typically mostly capture taxonomic structure. To address this issue, we propose a strategy for identifying what different concepts, from a potentially large concept vocabulary, have in common with others. We then represent concepts in terms of the properties they share with the other concepts. To demonstrate the practical usefulness of this way of modelling concepts, we consider the task of ultra-fine entity typing, which is a challenging multi-label classification problem. We show that by augmenting the label set with shared properties, we can improve the performance of the state-of-the-art models for this task.