 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Deck Chairs and Sun Hats Have in Common? Uncovering Shared Properties in Large Concept Vocabularies
Oct 23, 2023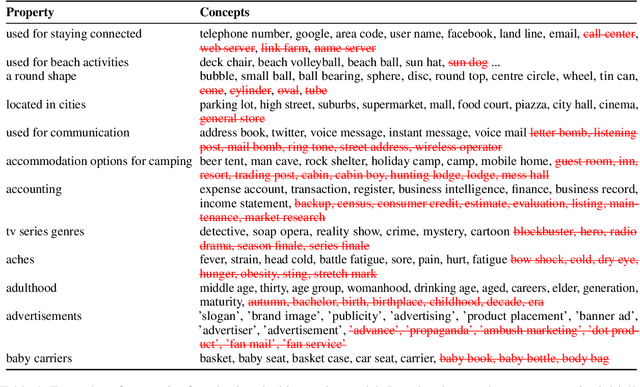
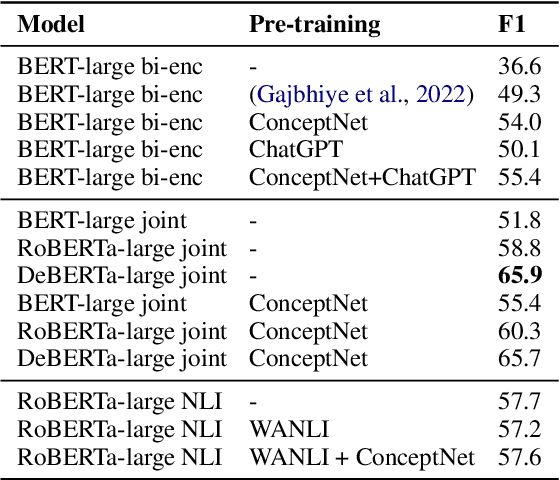
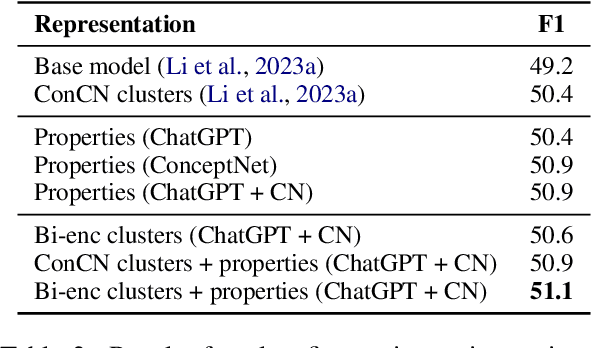

Concepts play a central role in many applications. This includes settings where concepts have to be modelled in the absence of sentence context. Previous work has therefore focused on distilling decontextualised concept embeddings from language models. But concepts can be modelled from different perspectives, whereas concept embeddings typically mostly capture taxonomic structure. To address this issue, we propose a strategy for identifying what different concepts, from a potentially large concept vocabulary, have in common with others. We then represent concepts in terms of the properties they share with the other concepts. To demonstrate the practical usefulness of this way of modelling concepts, we consider the task of ultra-fine entity typing, which is a challenging multi-label classification problem. We show that by augmenting the label set with shared properties, we can improve the performance of the state-of-the-art models for this task.
Cabbage Sweeter than Cake? Analysing the Potential of Large Language Models for Learning Conceptual Spaces
Oct 09, 2023



The theory of Conceptual Spaces is an influential cognitive-linguistic framework for representing the meaning of concepts. Conceptual spaces are constructed from a set of quality dimensions, which essentially correspond to primitive perceptual features (e.g. hue or size). These quality dimensions are usually learned from human judgements, which means that applications of conceptual spaces tend to be limited to narrow domains (e.g. modelling colour or taste). Encouraged by recent findings about the ability of Large Language Models (LLMs) to learn perceptually grounded representations, we explore the potential of such models for learning conceptual spaces. Our experiments show that LLMs can indeed be used for learning meaningful representations to some extent. However, we also find that fine-tuned models of the BERT family are able to match or even outperform the largest GPT-3 model, despite being 2 to 3 orders of magnitude smaller.
Modelling Commonsense Properties using Pre-Trained Bi-Encoders
Oct 06, 2022

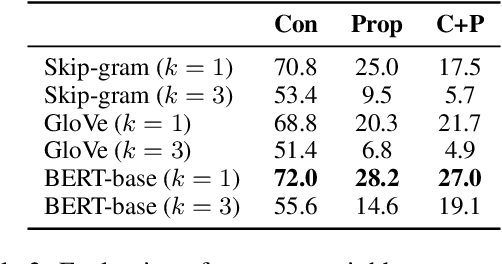
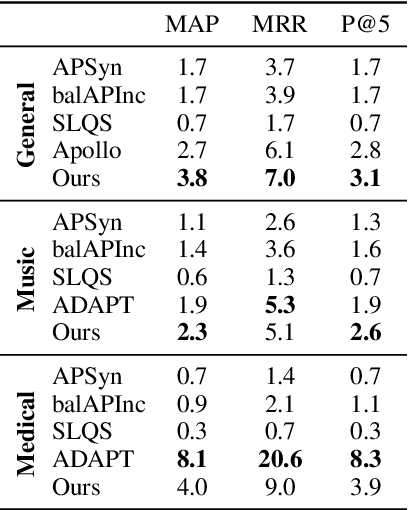
Grasping the commonsense properties of everyday concepts is an important prerequisite to language understanding. While contextualised language models are reportedly capable of predicting such commonsense properties with human-level accuracy, we argue that such results have been inflated because of the high similarity between training and test concepts. This means that models which capture concept similarity can perform well, even if they do not capture any knowledge of the commonsense properties themselves. In settings where there is no overlap between the properties that are considered during training and testing, we find that the empirical performance of standard language models drops dramatically. To address this, we study the possibility of fine-tuning language models to explicitly model concepts and their properties. In particular, we train separate concept and property encoders on two types of readily available data: extracted hyponym-hypernym pairs and generic sentences. Our experimental results show that the resulting encoders allow us to predict commonsense properties with much higher accuracy than is possible by directly fine-tuning language models. We also present experimental results for the related task of unsupervised hypernym discovery.
ExBERT: An External Knowledge Enhanced BERT for Natural Language Inference
Aug 03, 2021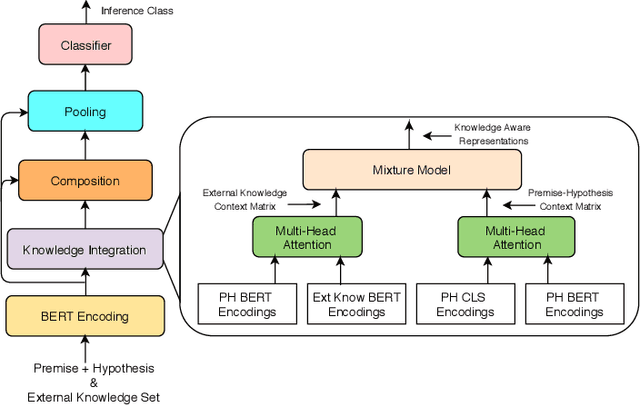
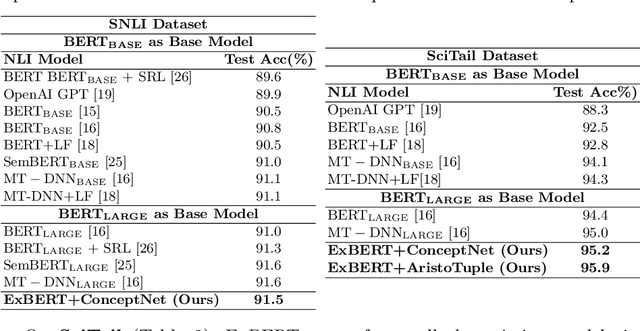

Neural language representation models such as BERT, pre-trained on large-scale unstructured corpora lack explicit grounding to real-world commonsense knowledge and are often unable to remember facts required for reasoning and inference. Natural Language Inference (NLI) is a challenging reasoning task that relies on common human understanding of language and real-world commonsense knowledge. We introduce a new model for NLI called External Knowledge Enhanced BERT (ExBERT), to enrich the contextual representation with real-world commonsense knowledge from external knowledge sources and enhance BERT's language understanding and reasoning capabilities. ExBERT takes full advantage of contextual word representations obtained from BERT and employs them to retrieve relevant external knowledge from knowledge graphs and to encode the retrieved external knowledge. Our model adaptively incorporates the external knowledge context required for reasoning over the inputs. Extensive experiments on the challenging SciTail and SNLI benchmarks demonstrate the effectiveness of ExBERT: in comparison to the previous state-of-the-art, we obtain an accuracy of 95.9% on SciTail and 91.5% on SNLI.
Knowledge Distillation for Quality Estimation
Jul 01, 2021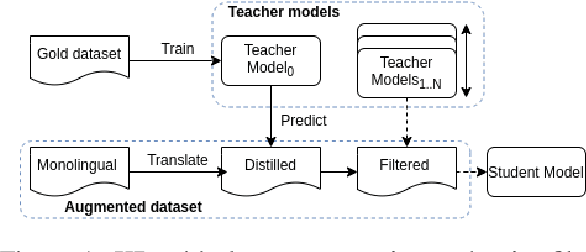
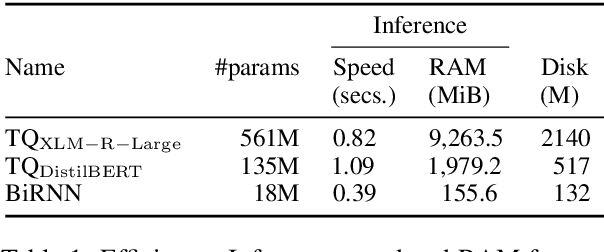
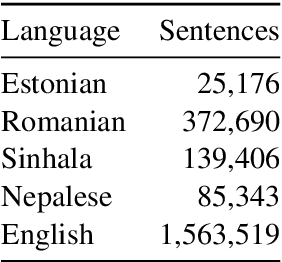
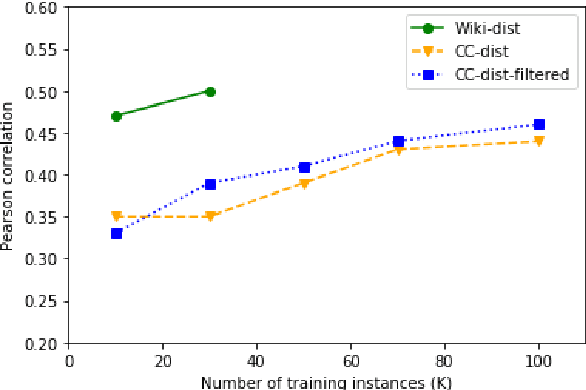
Quality Estimation (QE) is the task of automatically predicting Machine Translation quality in the absence of reference translations, making it applicable in real-time settings, such as translating online social media conversations. Recent success in QE stems from the use of multilingual pre-trained representations, where very large models lead to impressive results. However, the inference time, disk and memory requirements of such models do not allow for wide usage in the real world. Models trained on distilled pre-trained representations remain prohibitively large for many usage scenarios. We instead propose to directly transfer knowledge from a strong QE teacher model to a much smaller model with a different, shallower architecture. We show that this approach, in combination with data augmentation, leads to light-weight QE models that perform competitively with distilled pre-trained representations with 8x fewer parameters.
Bilinear Fusion of Commonsense Knowledge with Attention-Based NLI Models
Oct 22, 2020


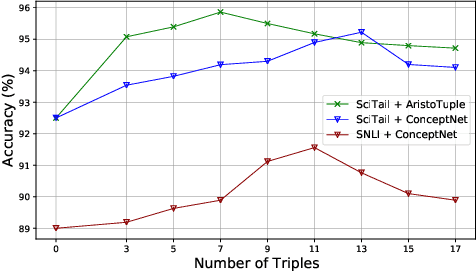
We consider the task of incorporating real-world commonsense knowledge into deep Natural Language Inference (NLI) models. Existing external knowledge incorporation methods are limited to lexical level knowledge and lack generalization across NLI models, datasets, and commonsense knowledge sources. To address these issues, we propose a novel NLI model-independent neural framework, BiCAM. BiCAM incorporates real-world commonsense knowledge into NLI models. Combined with convolutional feature detectors and bilinear feature fusion, BiCAM provides a conceptually simple mechanism that generalizes well. Quantitative evaluations with two state-of-the-art NLI baselines on SNLI and SciTail datasets in conjunction with ConceptNet and Aristo Tuple KGs show that BiCAM considerably improves the accuracy the incorporated NLI baselines. For example, our BiECAM model, an instance of BiCAM, on the challenging SciTail dataset, improves the accuracy of incorporated baselines by 7.0% with ConceptNet, and 8.0% with Aristo Tuple KG.
An Exploration of Dropout with RNNs for Natural Language Inference
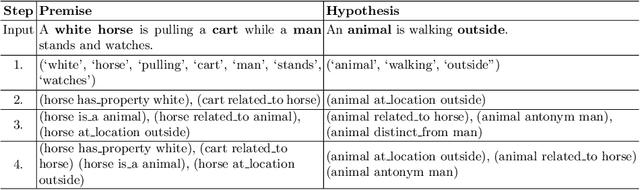
Oct 22, 2018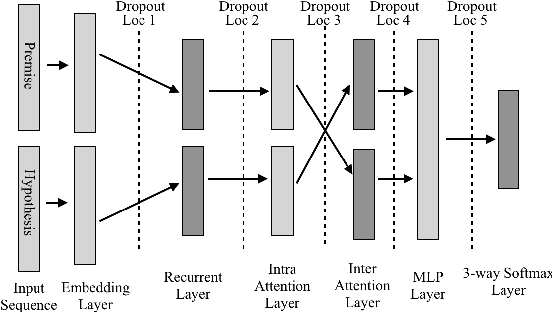
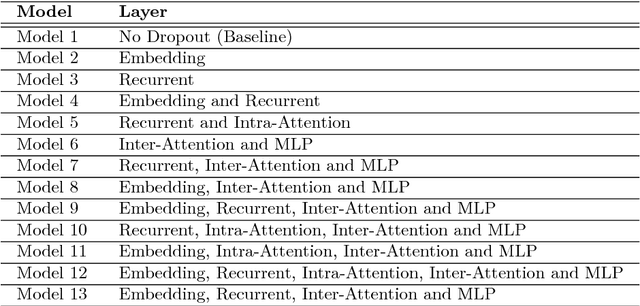
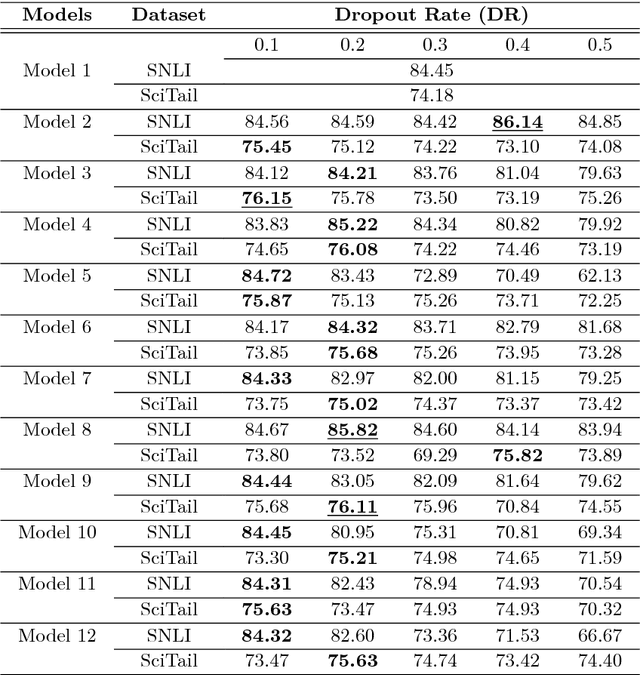
Dropout is a crucial regularization technique for the Recurrent Neural Network (RNN) models of Natural Language Inference (NLI). However, dropout has not been evaluated for the effectiveness at different layers and dropout rates in NLI models. In this paper, we propose a novel RNN model for NLI and empirically evaluate the effect of applying dropout at different layers in the model. We also investigate the impact of varying dropout rates at these layers. Our empirical evaluation on a large (Stanford Natural Language Inference (SNLI)) and a small (SciTail) dataset suggest that dropout at each feed-forward connection severely affects the model accuracy at increasing dropout rates. We also show that regularizing the embedding layer is efficient for SNLI whereas regularizing the recurrent layer improves the accuracy for SciTail. Our model achieved an accuracy 86.14% on the SNLI dataset and 77.05% on SciTail.