 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explainable Evaluation Metrics for Machine Translation
Jun 22, 2023



Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics for machine translation (for example, COMET or BERTScore) are based on black-box large language models. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are more transparent. To foster more widespread acceptance of novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties as well as key goals of explainable machine translation metrics and provide a comprehensive synthesis of recent techniques, relating them to our established goals and properties. In this context, we also discuss the latest state-of-the-art approaches to explainable metrics based on generative models such as ChatGPT and GPT4. Finally, we contribute a vision of next-generation approaches, including natural language explanations. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent machine translation systems.
Reducing Hallucinations in Neural Machine Translation with Feature Attribution
Nov 17, 2022



Neural conditional language generation models achieve the state-of-the-art in Neural Machine Translation (NMT) but are highly dependent on the quality of parallel training dataset. When trained on low-quality datasets, these models are prone to various error types, including hallucinations, i.e. outputs that are fluent, but unrelated to the source sentences. These errors are particularly dangerous, because on the surface the translation can be perceived as a correct output, especially if the reader does not understand the source language. We present a case study focusing on model understanding and regularisation to reduce hallucinations in NMT. We first use feature attribution methods to study the behaviour of an NMT model that produces hallucinations. We then leverage these methods to propose a novel loss function that substantially helps reduce hallucinations and does not require retraining the model from scratch.
Towards Explainable Evaluation Metrics for Natural Language Generation
Mar 21, 2022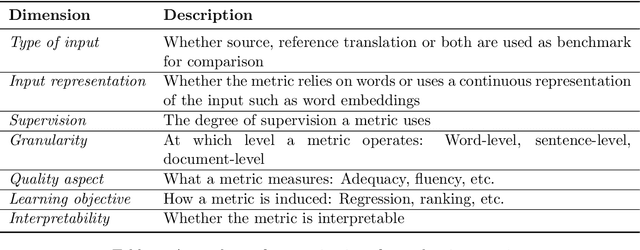
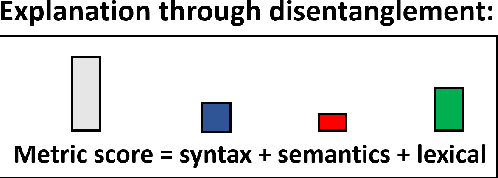
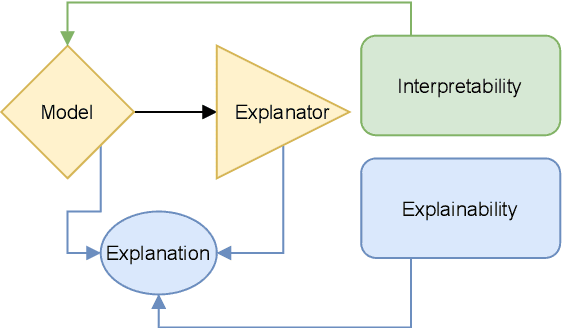

Unlike classical lexical overlap metrics such as BLEU, most current evaluation metrics (such as BERTScore or MoverScore) are based on black-box language models such as BERT or XLM-R. They often achieve strong correlations with human judgments, but recent research indicates that the lower-quality classical metrics remain dominant, one of the potential reasons being that their decision processes are transparent. To foster more widespread acceptance of the novel high-quality metrics, explainability thus becomes crucial. In this concept paper, we identify key properties and propose key goals of explainable machine translation evaluation metrics. We also provide a synthesizing overview over recent approaches for explainable machine translation metrics and discuss how they relate to those goals and properties. Further, we conduct own novel experiments, which (among others) find that current adversarial NLP techniques are unsuitable for automatically identifying limitations of high-quality black-box evaluation metrics, as they are not meaning-preserving. Finally, we provide a vision of future approaches to explainable evaluation metrics and their evaluation. We hope that our work can help catalyze and guide future research on explainable evaluation metrics and, mediately, also contribute to better and more transparent text generation systems.
The Eval4NLP Shared Task on Explainable Quality Estimation: Overview and Results
Oct 08, 2021
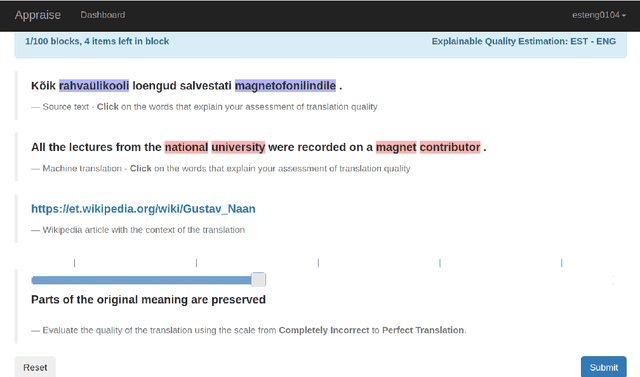
In this paper, we introduce the Eval4NLP-2021shared task on explainable quality estimation. Given a source-translation pair, this shared task requires not only to provide a sentence-level score indicating the overall quality of the translation, but also to explain this score by identifying the words that negatively impact translation quality. We present the data, annotation guidelines and evaluation setup of the shared task, describe the six participating systems, and analyze the results. To the best of our knowledge, this is the first shared task on explainable NLP evaluation metrics. Datasets and results are available at https://github.com/eval4nlp/SharedTask2021.
Pushing the Right Buttons: Adversarial Evaluation of Quality Estimation
Sep 22, 2021
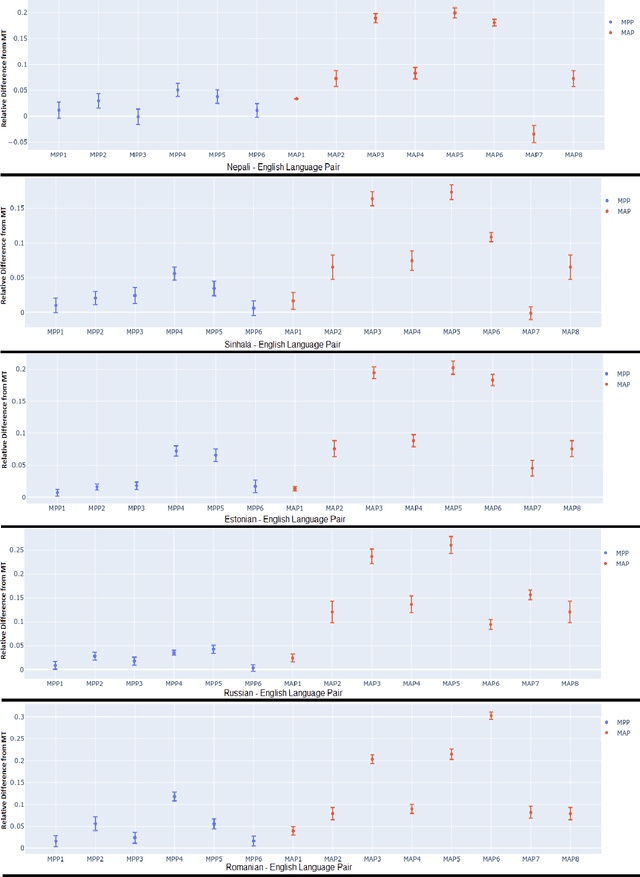

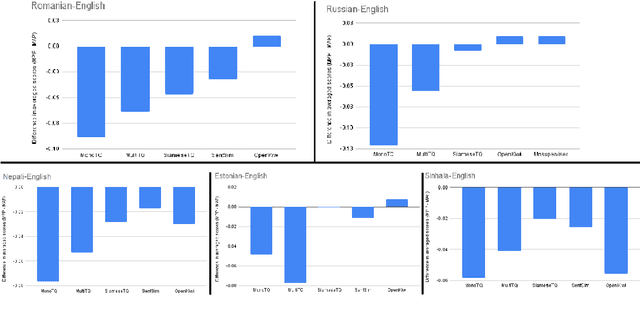
Current Machine Translation (MT) systems achieve very good results on a growing variety of language pairs and datasets. However, they are known to produce fluent translation outputs that can contain important meaning errors, thus undermining their reliability in practice. Quality Estimation (QE) is the task of automatically assessing the performance of MT systems at test time. Thus, in order to be useful, QE systems should be able to detect such errors. However, this ability is yet to be tested in the current evaluation practices, where QE systems are assessed only in terms of their correlation with human judgements. In this work, we bridge this gap by proposing a general methodology for adversarial testing of QE for MT. First, we show that despite a high correlation with human judgements achieved by the recent SOTA, certain types of meaning errors are still problematic for QE to detect. Second, we show that on average, the ability of a given model to discriminate between meaning-preserving and meaning-altering perturbations is predictive of its overall performance, thus potentially allowing for comparing QE systems without relying on manual quality annotation.
Translation Error Detection as Rationale Extraction
Aug 27, 2021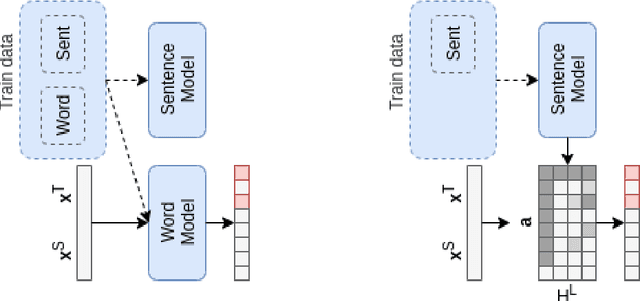
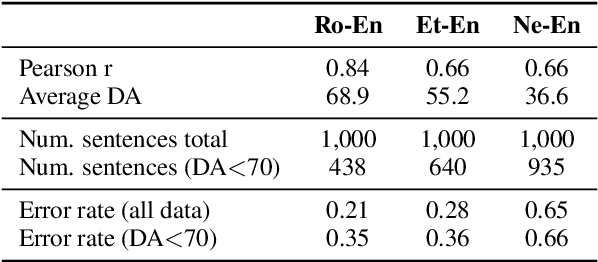
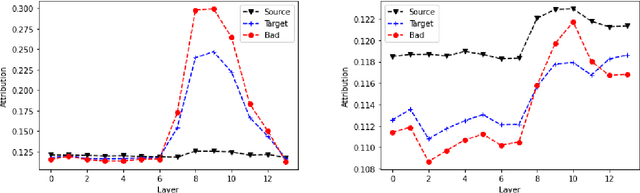
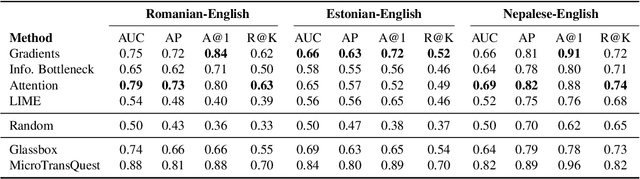
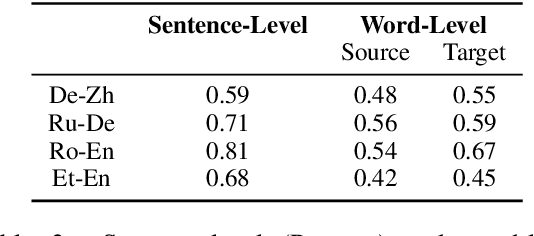
Recent Quality Estimation (QE) models based on multilingual pre-trained representations have achieved very competitive results when predicting the overall quality of translated sentences. Predicting translation errors, i.e. detecting specifically which words are incorrect, is a more challenging task, especially with limited amounts of training data. We hypothesize that, not unlike humans, successful QE models rely on translation errors to predict overall sentence quality. By exploring a set of feature attribution methods that assign relevance scores to the inputs to explain model predictions, we study the behaviour of state-of-the-art sentence-level QE models and show that explanations (i.e. rationales) extracted from these models can indeed be used to detect translation errors. We therefore (i) introduce a novel semi-supervised method for word-level QE and (ii) propose to use the QE task as a new benchmark for evaluating the plausibility of feature attribution, i.e. how interpretable model explanations are to humans.
Knowledge Distillation for Quality Estimation
Jul 01, 2021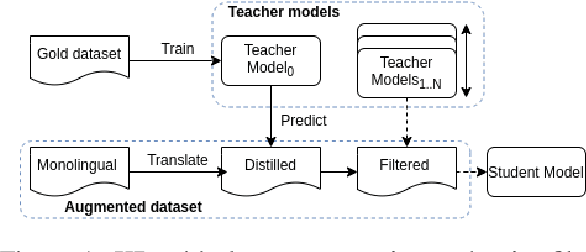
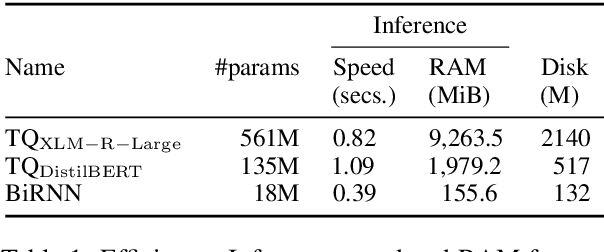
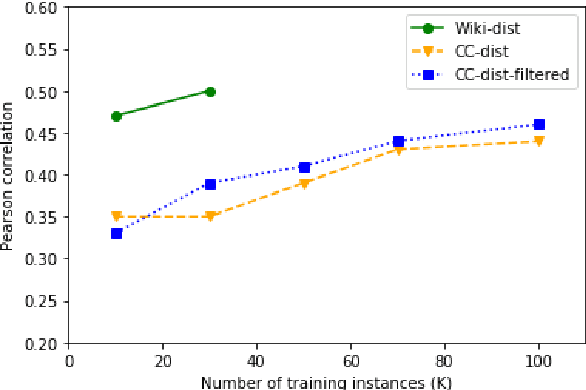
Quality Estimation (QE) is the task of automatically predicting Machine Translation quality in the absence of reference translations, making it applicable in real-time settings, such as translating online social media conversations. Recent success in QE stems from the use of multilingual pre-trained representations, where very large models lead to impressive results. However, the inference time, disk and memory requirements of such models do not allow for wide usage in the real world. Models trained on distilled pre-trained representations remain prohibitively large for many usage scenarios. We instead propose to directly transfer knowledge from a strong QE teacher model to a much smaller model with a different, shallower architecture. We show that this approach, in combination with data augmentation, leads to light-weight QE models that perform competitively with distilled pre-trained representations with 8x fewer parameters.
Backtranslation Feedback Improves User Confidence in MT, Not Quality
Apr 12, 2021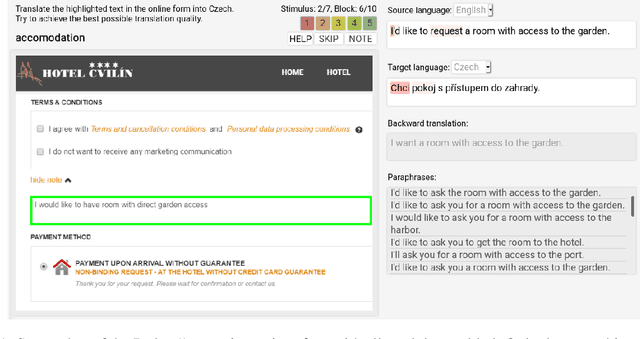
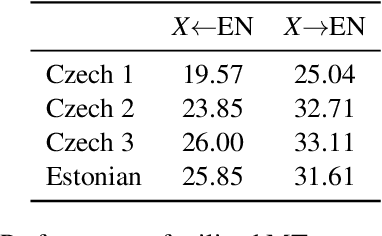
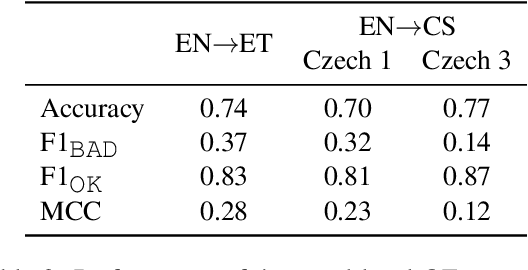
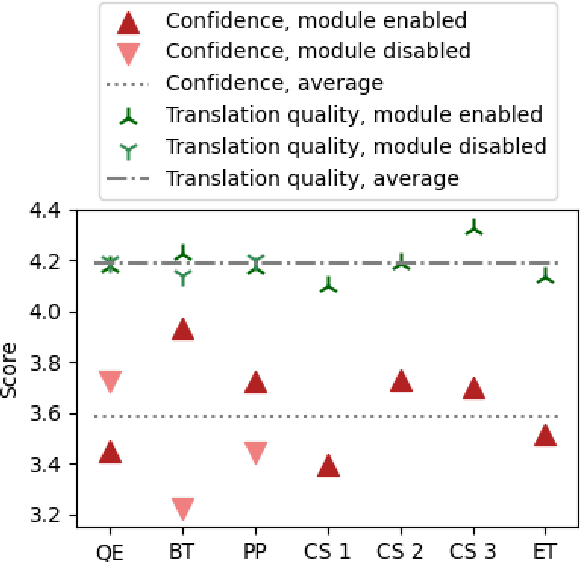
Translating text into a language unknown to the text's author, dubbed outbound translation, is a modern need for which the user experience has significant room for improvement, beyond the basic machine translation facility. We demonstrate this by showing three ways in which user confidence in the outbound translation, as well as its overall final quality, can be affected: backward translation, quality estimation (with alignment) and source paraphrasing. In this paper, we describe an experiment on outbound translation from English to Czech and Estonian. We examine the effects of each proposed feedback module and further focus on how the quality of machine translation systems influence these findings and the user perception of success. We show that backward translation feedback has a mixed effect on the whole process: it increases user confidence in the produced translation, but not the objective quality.
Exploring Supervised and Unsupervised Rewards in Machine Translation
Feb 22, 2021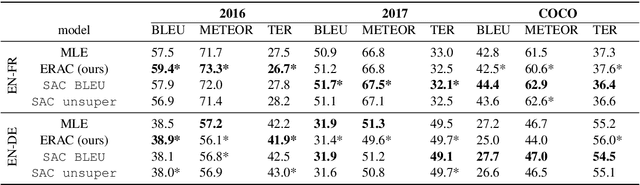
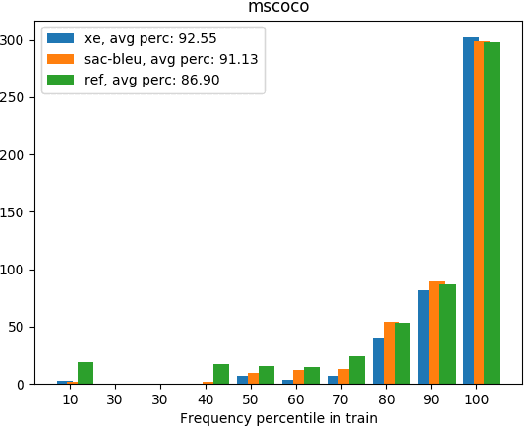

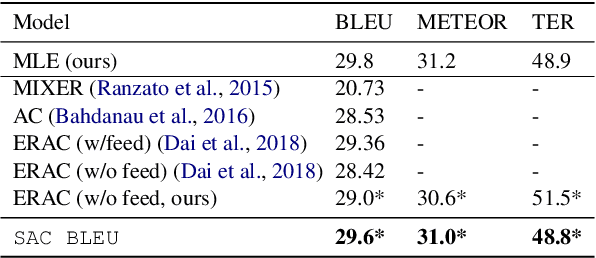
Reinforcement Learning (RL) is a powerful framework to address the discrepancy between loss functions used during training and the final evaluation metrics to be used at test time. When applied to neural Machine Translation (MT), it minimises the mismatch between the cross-entropy loss and non-differentiable evaluation metrics like BLEU. However, the suitability of these metrics as reward function at training time is questionable: they tend to be sparse and biased towards the specific words used in the reference texts. We propose to address this problem by making models less reliant on such metrics in two ways: (a) with an entropy-regularised RL method that does not only maximise a reward function but also explore the action space to avoid peaky distributions; (b) with a novel RL method that explores a dynamic unsupervised reward function to balance between exploration and exploitation. We base our proposals on the Soft Actor-Critic (SAC) framework, adapting the off-policy maximum entropy model for language generation applications such as MT. We demonstrate that SAC with BLEU reward tends to overfit less to the training data and performs better on out-of-domain data. We also show that our dynamic unsupervised reward can lead to better translation of ambiguous words.
MLQE-PE: A Multilingual Quality Estimation and Post-Editing Dataset
Oct 09, 2020



We present MLQE-PE, a new dataset for Machine Translation (MT) Quality Estimation (QE) and Automatic Post-Editing (APE). The dataset contains seven language pairs, with human labels for 9,000 translations per language pair in the following formats: sentence-level direct assessments and post-editing effort, and word-level good/bad labels. It also contains the post-edited sentences, as well as titles of the articles where the sentences were extracted from, and the neural MT models used to translate the text.