 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Attention Sparsity in Transformers
Sep 24, 2021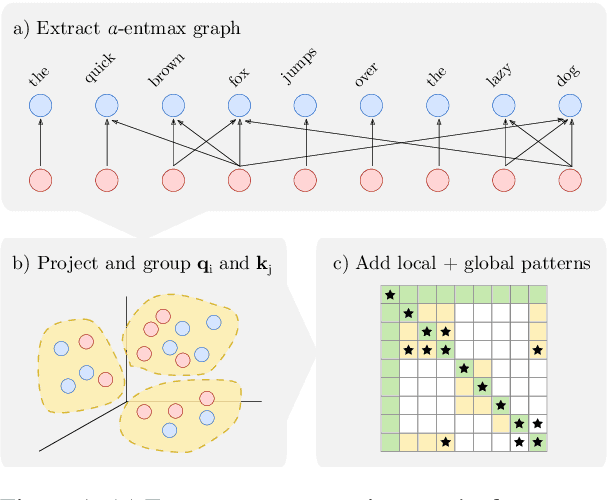

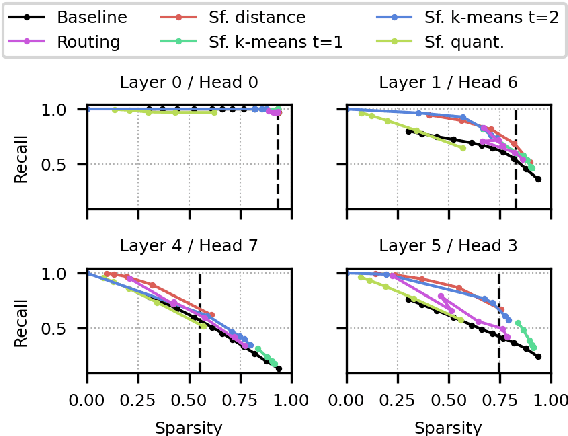

A bottleneck in transformer architectures is their quadratic complexity with respect to the input sequence, which has motivated a body of work on efficient sparse approximations to softmax. An alternative path, used by entmax transformers, consists of having built-in exact sparse attention; however this approach still requires quadratic computation. In this paper, we propose Sparsefinder, a simple model trained to identify the sparsity pattern of entmax attention before computing it. We experiment with three variants of our method, based on distances, quantization, and clustering, on two tasks: machine translation (attention in the decoder) and masked language modeling (encoder-only). Our work provides a new angle to study model efficiency by doing extensive analysis of the tradeoff between the sparsity and recall of the predicted attention graph. This allows for detailed comparison between different models, and may guide future benchmarks for sparse models.
MLQE-PE: A Multilingual Quality Estimation and Post-Editing Dataset
Oct 09, 2020



We present MLQE-PE, a new dataset for Machine Translation (MT) Quality Estimation (QE) and Automatic Post-Editing (APE). The dataset contains seven language pairs, with human labels for 9,000 translations per language pair in the following formats: sentence-level direct assessments and post-editing effort, and word-level good/bad labels. It also contains the post-edited sentences, as well as titles of the articles where the sentences were extracted from, and the neural MT models used to translate the text.
Portuguese Word Embeddings: Evaluating on Word Analogies and Natural Language Tasks
Aug 20, 2017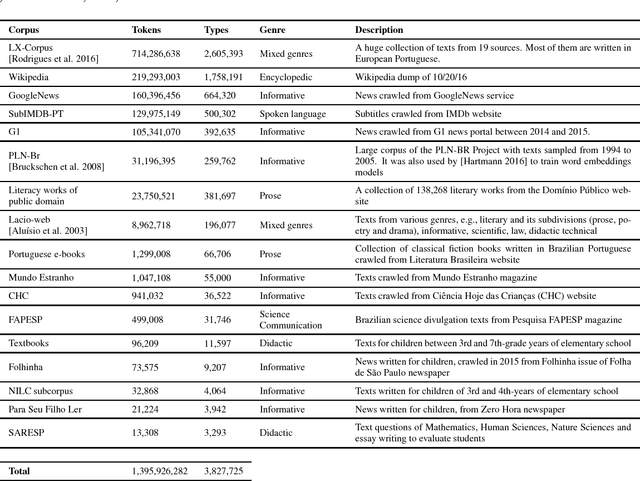
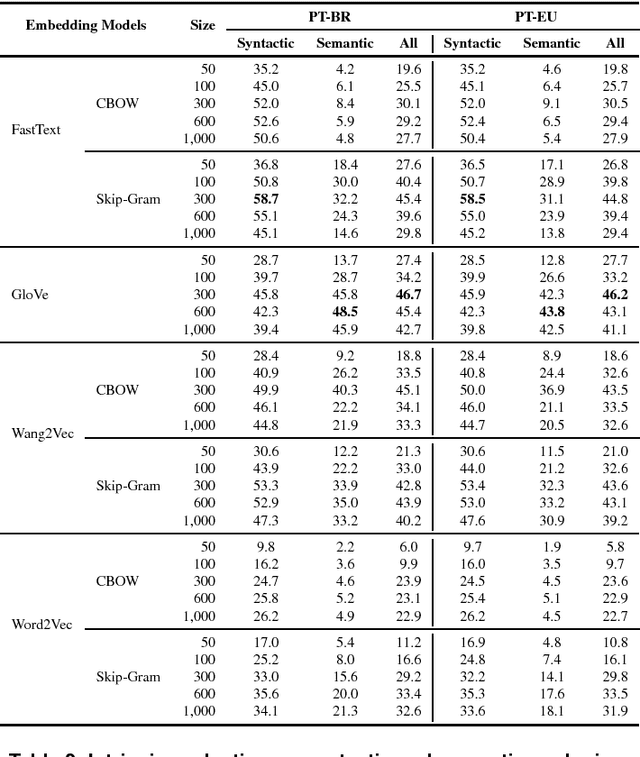
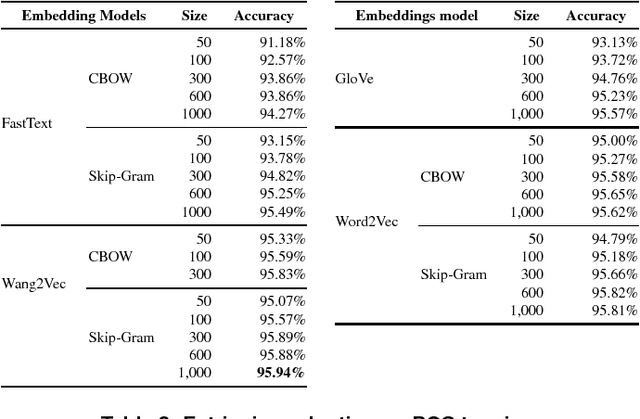
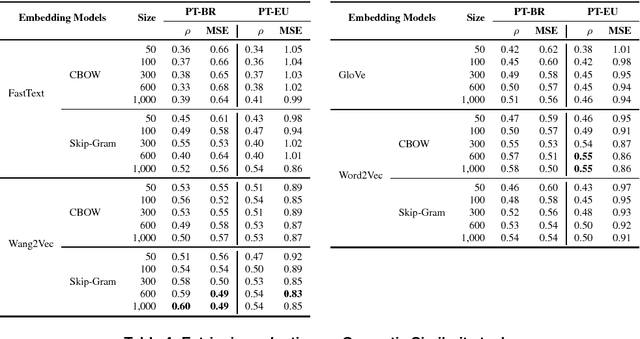
Word embeddings have been found to provide meaningful representations for words in an efficient way; therefore, they have become common in Natural Language Processing sys- tems. In this paper, we evaluated different word embedding models trained on a large Portuguese corpus, including both Brazilian and European variants. We trained 31 word embedding models using FastText, GloVe, Wang2Vec and Word2Vec. We evaluated them intrinsically on syntactic and semantic analogies and extrinsically on POS tagging and sentence semantic similarity tasks. The obtained results suggest that word analogies are not appropriate for word embedding evaluation; task-specific evaluations appear to be a better option.