 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformative Prediction on Games and Mechanism Design
Aug 09, 2024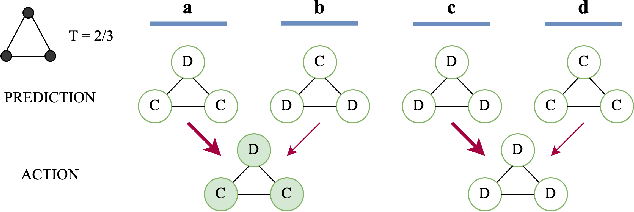
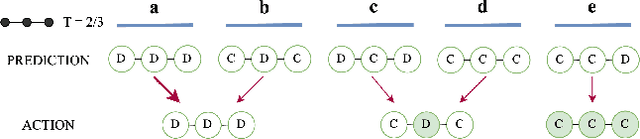
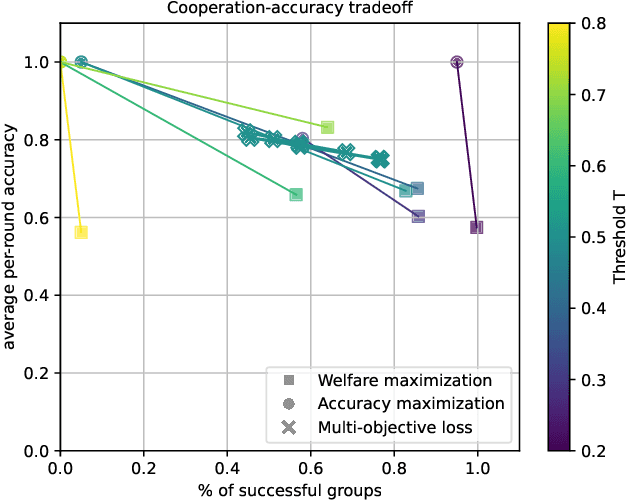
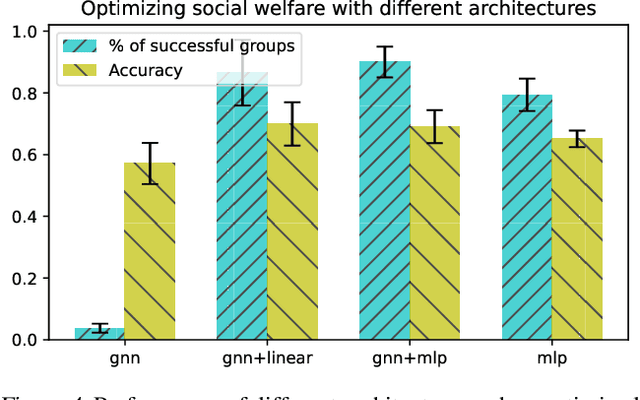
Predictions often influence the reality which they aim to predict, an effect known as performativity. Existing work focuses on accuracy maximization under this effect, but model deployment may have important unintended impacts, especially in multiagent scenarios. In this work, we investigate performative prediction in a concrete game-theoretic setting where social welfare is an alternative objective to accuracy maximization. We explore a collective risk dilemma scenario where maximising accuracy can negatively impact social welfare, when predicting collective behaviours. By assuming knowledge of a Bayesian agent behavior model, we then show how to achieve better trade-offs and use them for mechanism design.
Human-in-the-Loop Causal Discovery under Latent Confounding using Ancestral GFlowNets
Sep 21, 2023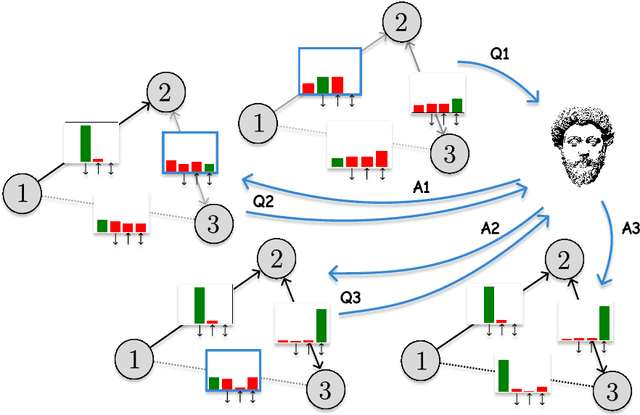

Structure learning is the crux of causal inference. Notably, causal discovery (CD) algorithms are brittle when data is scarce, possibly inferring imprecise causal relations that contradict expert knowledge -- especially when considering latent confounders. To aggravate the issue, most CD methods do not provide uncertainty estimates, making it hard for users to interpret results and improve the inference process. Surprisingly, while CD is a human-centered affair, no works have focused on building methods that both 1) output uncertainty estimates that can be verified by experts and 2) interact with those experts to iteratively refine CD. To solve these issues, we start by proposing to sample (causal) ancestral graphs proportionally to a belief distribution based on a score function, such as the Bayesian information criterion (BIC), using generative flow networks. Then, we leverage the diversity in candidate graphs and introduce an optimal experimental design to iteratively probe the expert about the relations among variables, effectively reducing the uncertainty of our belief over ancestral graphs. Finally, we update our samples to incorporate human feedback via importance sampling. Importantly, our method does not require causal sufficiency (i.e., unobserved confounders may exist). Experiments with synthetic observational data show that our method can accurately sample from distributions over ancestral graphs and that we can greatly improve inference quality with human aid.
Bayesian Structure Learning with Generative Flow Networks
Feb 28, 2022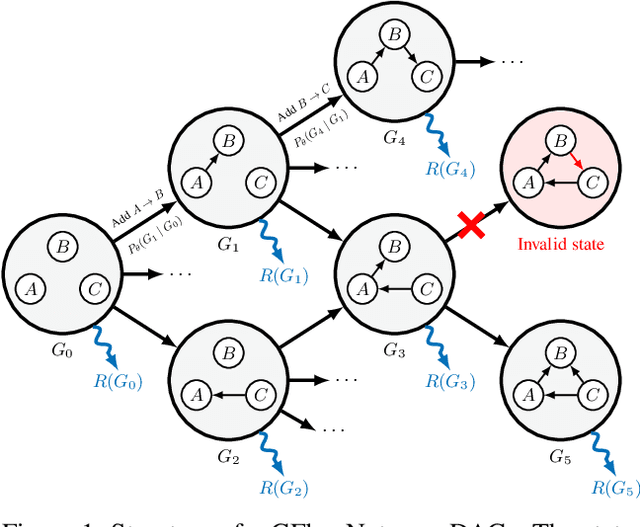
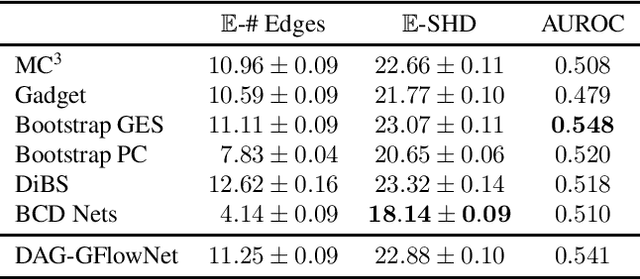
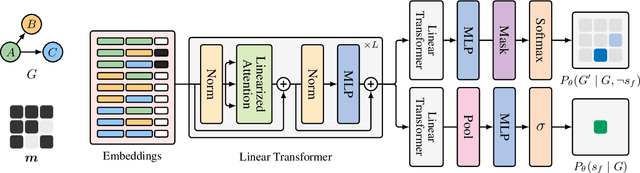
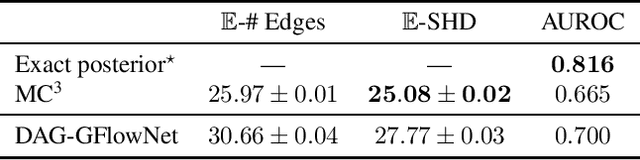
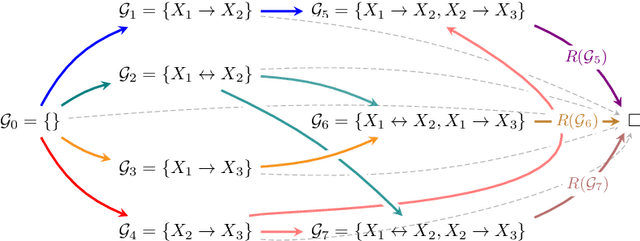
In Bayesian structure learning, we are interested in inferring a distribution over the directed acyclic graph (DAG) structure of Bayesian networks, from data. Defining such a distribution is very challenging, due to the combinatorially large sample space, and approximations based on MCMC are often required. Recently, a novel class of probabilistic models, called Generative Flow Networks (GFlowNets), have been introduced as a general framework for generative modeling of discrete and composite objects, such as graphs. In this work, we propose to use a GFlowNet as an alternative to MCMC for approximating the posterior distribution over the structure of Bayesian networks, given a dataset of observations. Generating a sample DAG from this approximate distribution is viewed as a sequential decision problem, where the graph is constructed one edge at a time, based on learned transition probabilities. Through evaluation on both simulated and real data, we show that our approach, called DAG-GFlowNet, provides an accurate approximation of the posterior over DAGs, and it compares favorably against other methods based on MCMC or variational inference.
Predicting Attention Sparsity in Transformers
Sep 24, 2021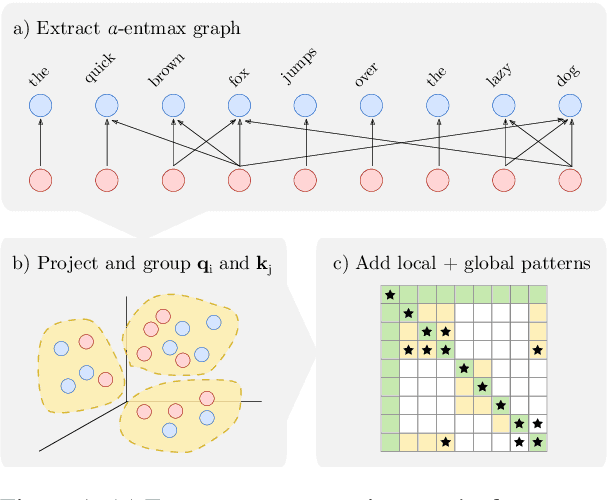

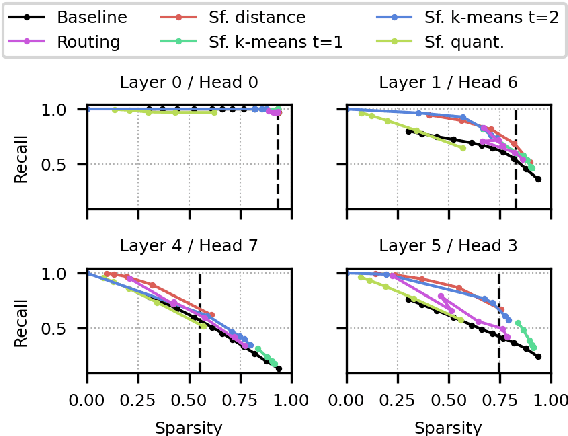

A bottleneck in transformer architectures is their quadratic complexity with respect to the input sequence, which has motivated a body of work on efficient sparse approximations to softmax. An alternative path, used by entmax transformers, consists of having built-in exact sparse attention; however this approach still requires quadratic computation. In this paper, we propose Sparsefinder, a simple model trained to identify the sparsity pattern of entmax attention before computing it. We experiment with three variants of our method, based on distances, quantization, and clustering, on two tasks: machine translation (attention in the decoder) and masked language modeling (encoder-only). Our work provides a new angle to study model efficiency by doing extensive analysis of the tradeoff between the sparsity and recall of the predicted attention graph. This allows for detailed comparison between different models, and may guide future benchmarks for sparse models.
Learning Non-Monotonic Automatic Post-Editing of Translations from Human Orderings
Apr 29, 2020
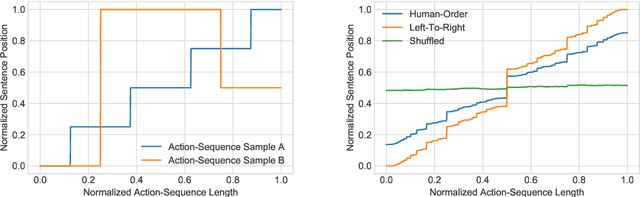
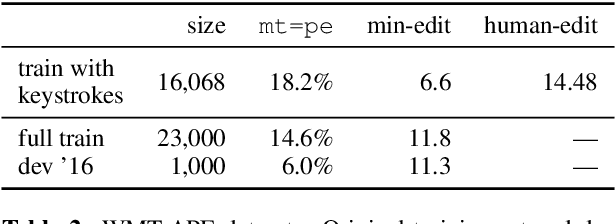
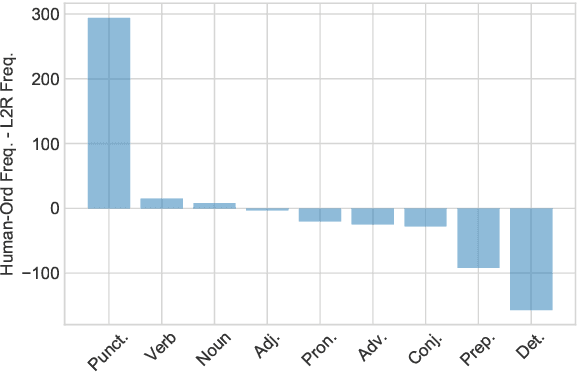
Recent research in neural machine translation has explored flexible generation orders, as an alternative to left-to-right generation. However, training non-monotonic models brings a new complication: how to search for a good ordering when there is a combinatorial explosion of orderings arriving at the same final result? Also, how do these automatic orderings compare with the actual behaviour of human translators? Current models rely on manually built biases or are left to explore all possibilities on their own. In this paper, we analyze the orderings produced by human post-editors and use them to train an automatic post-editing system. We compare the resulting system with those trained with left-to-right and random post-editing orderings. We observe that humans tend to follow a nearly left-to-right order, but with interesting deviations, such as preferring to start by correcting punctuation or verbs.
Translator2Vec: Understanding and Representing Human Post-Editors
Jul 24, 2019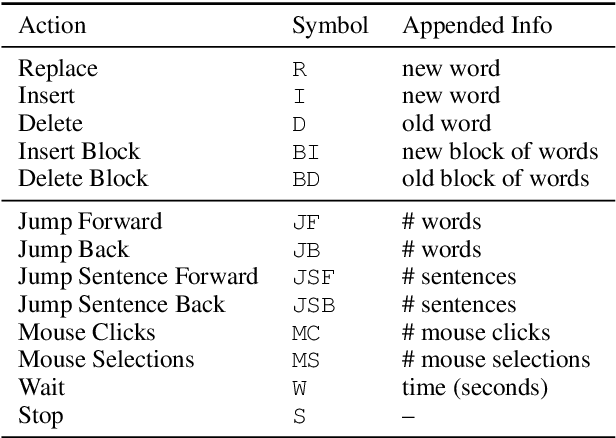
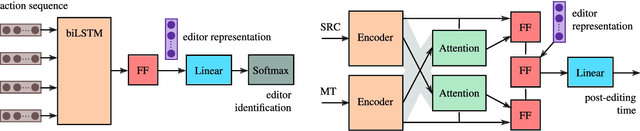

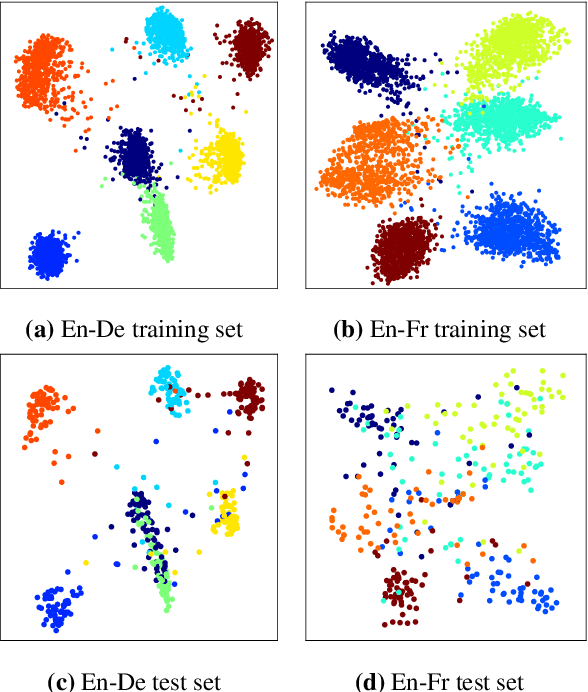
The combination of machines and humans for translation is effective, with many studies showing productivity gains when humans post-edit machine-translated output instead of translating from scratch. To take full advantage of this combination, we need a fine-grained understanding of how human translators work, and which post-editing styles are more effective than others. In this paper, we release and analyze a new dataset with document-level post-editing action sequences, including edit operations from keystrokes, mouse actions, and waiting times. Our dataset comprises 66,268 full document sessions post-edited by 332 humans, the largest of the kind released to date. We show that action sequences are informative enough to identify post-editors accurately, compared to baselines that only look at the initial and final text. We build on this to learn and visualize continuous representations of post-editors, and we show that these representations improve the downstream task of predicting post-editing time.
Unbabel's Participation in the WMT19 Translation Quality Estimation Shared Task
Jul 24, 2019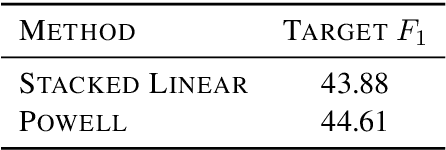
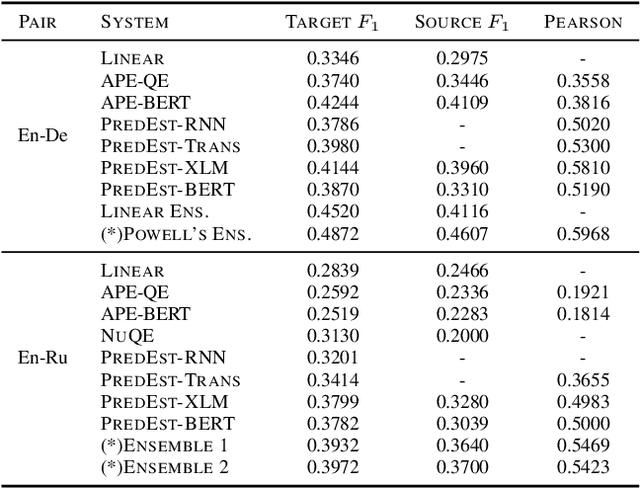
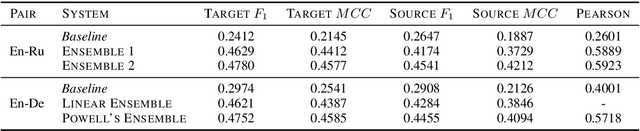

We present the contribution of the Unbabel team to the WMT 2019 Shared Task on Quality Estimation. We participated on the word, sentence, and document-level tracks, encompassing 3 language pairs: nglish-German, English-Russian, and English-French. Our submissions build upon the recent OpenKiwi framework: we combine linear, neural, and predictor-estimator systems with new transfer learning approaches using BERT and XLM pre-trained models. We compare systems individually and propose new ensemble techniques for word and sentence-level predictions. We also propose a simple technique for converting word labels into document-level predictions. Overall, our submitted systems achieve the best results on all tracks and language pairs by a considerable margin.