 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Amino Acids: Does the Curse of Depth Persist?
Feb 25, 2026Protein language models (PLMs) have become widely adopted as general-purpose models, demonstrating strong performance in protein engineering and de novo design. Like large language models (LLMs), they are typically trained as deep transformers with next-token or masked-token prediction objectives on massive sequence corpora and are scaled by increasing model depth. Recent work on autoregressive LLMs has identified the Curse of Depth: later layers contribute little to the final output predictions. These findings naturally raise the question of whether a similar depth inefficiency also appears in PLMs, where many widely used models are not autoregressive, and some are multimodal, accepting both protein sequence and structure as input. In this work, we present a depth analysis of six popular PLMs across model families and scales, spanning three training objectives, namely autoregressive, masked, and diffusion, and quantify how layer contributions evolve with depth using a unified set of probing- and perturbation-based measurements. Across all models, we observe consistent depth-dependent patterns that extend prior findings on LLMs: later layers depend less on earlier computations and mainly refine the final output distribution, and these effects are increasingly pronounced in deeper models. Taken together, our results suggest that PLMs exhibit a form of depth inefficiency, motivating future work on more depth-efficient architectures and training methods.
Are Object-Centric Representations Better At Compositional Generalization?
Feb 18, 2026Compositional generalization, the ability to reason about novel combinations of familiar concepts, is fundamental to human cognition and a critical challenge for machine learning. Object-centric (OC) representations, which encode a scene as a set of objects, are often argued to support such generalization, but systematic evidence in visually rich settings is limited. We introduce a Visual Question Answering benchmark across three controlled visual worlds (CLEVRTex, Super-CLEVR, and MOVi-C) to measure how well vision encoders, with and without object-centric biases, generalize to unseen combinations of object properties. To ensure a fair and comprehensive comparison, we carefully account for training data diversity, sample size, representation size, downstream model capacity, and compute. We use DINOv2 and SigLIP2, two widely used vision encoders, as the foundation models and their OC counterparts. Our key findings reveal that (1) OC approaches are superior in harder compositional generalization settings; (2) original dense representations surpass OC only on easier settings and typically require substantially more downstream compute; and (3) OC models are more sample efficient, achieving stronger generalization with fewer images, whereas dense encoders catch up or surpass them only with sufficient data and diversity. Overall, object-centric representations offer stronger compositional generalization when any one of dataset size, training data diversity, or downstream compute is constrained.
From Growing to Looping: A Unified View of Iterative Computation in LLMs
Feb 18, 2026Looping, reusing a block of layers across depth, and depth growing, training shallow-to-deep models by duplicating middle layers, have both been linked to stronger reasoning, but their relationship remains unclear. We provide a mechanistic unification: looped and depth-grown models exhibit convergent depth-wise signatures, including increased reliance on late layers and recurring patterns aligned with the looped or grown block. These shared signatures support the view that their gains stem from a common form of iterative computation. Building on this connection, we show that the two techniques are adaptable and composable: applying inference-time looping to the middle blocks of a depth-grown model improves accuracy on some reasoning primitives by up to $2\times$, despite the model never being trained to loop. Both approaches also adapt better than the baseline when given more in-context examples or additional supervised fine-tuning data. Additionally, depth-grown models achieve the largest reasoning gains when using higher-quality, math-heavy cooldown mixtures, which can be further boosted by adapting a middle block to loop. Overall, our results position depth growth and looping as complementary, practical methods for inducing and scaling iterative computation to improve reasoning.
Do Depth-Grown Models Overcome the Curse of Depth? An In-Depth Analysis
Dec 09, 2025Gradually growing the depth of Transformers during training can not only reduce training cost but also lead to improved reasoning performance, as shown by MIDAS (Saunshi et al., 2024). Thus far, however, a mechanistic understanding of these gains has been missing. In this work, we establish a connection to recent work showing that layers in the second half of non-grown, pre-layernorm Transformers contribute much less to the final output distribution than those in the first half - also known as the Curse of Depth (Sun et al., 2025, Csordás et al., 2025). Using depth-wise analyses, we demonstrate that growth via gradual middle stacking yields more effective utilization of model depth, alters the residual stream structure, and facilitates the formation of permutable computational blocks. In addition, we propose a lightweight modification of MIDAS that yields further improvements in downstream reasoning benchmarks. Overall, this work highlights how the gradual growth of model depth can lead to the formation of distinct computational circuits and overcome the limited depth utilization seen in standard non-grown models.
Jasmine: A Simple, Performant and Scalable JAX-based World Modeling Codebase
Oct 30, 2025While world models are increasingly positioned as a pathway to overcoming data scarcity in domains such as robotics, open training infrastructure for world modeling remains nascent. We introduce Jasmine, a performant JAX-based world modeling codebase that scales from single hosts to hundreds of accelerators with minimal code changes. Jasmine achieves an order-of-magnitude faster reproduction of the CoinRun case study compared to prior open implementations, enabled by performance optimizations across data loading, training and checkpointing. The codebase guarantees fully reproducible training and supports diverse sharding configurations. By pairing Jasmine with curated large-scale datasets, we establish infrastructure for rigorous benchmarking pipelines across model families and architectural ablations.
Minimum-Excess-Work Guidance
May 19, 2025We propose a regularization framework inspired by thermodynamic work for guiding pre-trained probability flow generative models (e.g., continuous normalizing flows or diffusion models) by minimizing excess work, a concept rooted in statistical mechanics and with strong conceptual connections to optimal transport. Our approach enables efficient guidance in sparse-data regimes common to scientific applications, where only limited target samples or partial density constraints are available. We introduce two strategies: Path Guidance for sampling rare transition states by concentrating probability mass on user-defined subsets, and Observable Guidance for aligning generated distributions with experimental observables while preserving entropy. We demonstrate the framework's versatility on a coarse-grained protein model, guiding it to sample transition configurations between folded/unfolded states and correct systematic biases using experimental data. The method bridges thermodynamic principles with modern generative architectures, offering a principled, efficient, and physics-inspired alternative to standard fine-tuning in data-scarce domains. Empirical results highlight improved sample efficiency and bias reduction, underscoring its applicability to molecular simulations and beyond.
AI Alignment in Medical Imaging: Unveiling Hidden Biases Through Counterfactual Analysis
Apr 28, 2025Machine learning (ML) systems for medical imaging have demonstrated remarkable diagnostic capabilities, but their susceptibility to biases poses significant risks, since biases may negatively impact generalization performance. In this paper, we introduce a novel statistical framework to evaluate the dependency of medical imaging ML models on sensitive attributes, such as demographics. Our method leverages the concept of counterfactual invariance, measuring the extent to which a model's predictions remain unchanged under hypothetical changes to sensitive attributes. We present a practical algorithm that combines conditional latent diffusion models with statistical hypothesis testing to identify and quantify such biases without requiring direct access to counterfactual data. Through experiments on synthetic datasets and large-scale real-world medical imaging datasets, including \textsc{cheXpert} and MIMIC-CXR, we demonstrate that our approach aligns closely with counterfactual fairness principles and outperforms standard baselines. This work provides a robust tool to ensure that ML diagnostic systems generalize well, e.g., across demographic groups, offering a critical step towards AI safety in healthcare. Code: https://github.com/Neferpitou3871/AI-Alignment-Medical-Imaging.
A scalable gene network model of regulatory dynamics in single cells
Mar 25, 2025Single-cell data provide high-dimensional measurements of the transcriptional states of cells, but extracting insights into the regulatory functions of genes, particularly identifying transcriptional mechanisms affected by biological perturbations, remains a challenge. Many perturbations induce compensatory cellular responses, making it difficult to distinguish direct from indirect effects on gene regulation. Modeling how gene regulatory functions shape the temporal dynamics of these responses is key to improving our understanding of biological perturbations. Dynamical models based on differential equations offer a principled way to capture transcriptional dynamics, but their application to single-cell data has been hindered by computational constraints, stochasticity, sparsity, and noise. Existing methods either rely on low-dimensional representations or make strong simplifying assumptions, limiting their ability to model transcriptional dynamics at scale. We introduce a Functional and Learnable model of Cell dynamicS, FLeCS, that incorporates gene network structure into coupled differential equations to model gene regulatory functions. Given (pseudo)time-series single-cell data, FLeCS accurately infers cell dynamics at scale, provides improved functional insights into transcriptional mechanisms perturbed by gene knockouts, both in myeloid differentiation and K562 Perturb-seq experiments, and simulates single-cell trajectories of A549 cells following small-molecule perturbations.
Causal Bayesian Optimization with Unknown Graphs
Mar 25, 2025Causal Bayesian Optimization (CBO) is a methodology designed to optimize an outcome variable by leveraging known causal relationships through targeted interventions. Traditional CBO methods require a fully and accurately specified causal graph, which is a limitation in many real-world scenarios where such graphs are unknown. To address this, we propose a new method for the CBO framework that operates without prior knowledge of the causal graph. Consistent with causal bandit theory, we demonstrate through theoretical analysis and that focusing on the direct causal parents of the target variable is sufficient for optimization, and provide empirical validation in the context of CBO. Furthermore we introduce a new method that learns a Bayesian posterior over the direct parents of the target variable. This allows us to optimize the outcome variable while simultaneously learning the causal structure. Our contributions include a derivation of the closed-form posterior distribution for the linear case. In the nonlinear case where the posterior is not tractable, we present a Gaussian Process (GP) approximation that still enables CBO by inferring the parents of the outcome variable. The proposed method performs competitively with existing benchmarks and scales well to larger graphs, making it a practical tool for real-world applications where causal information is incomplete.
Preference-Guided Diffusion for Multi-Objective Offline Optimization
Mar 21, 2025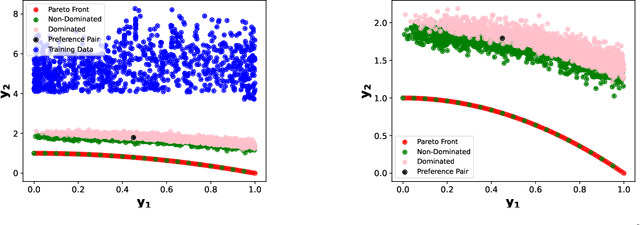
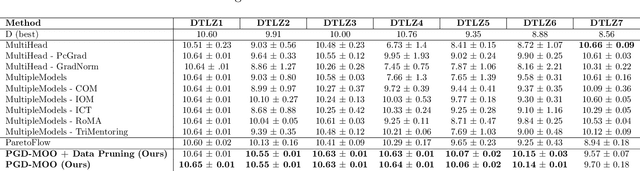
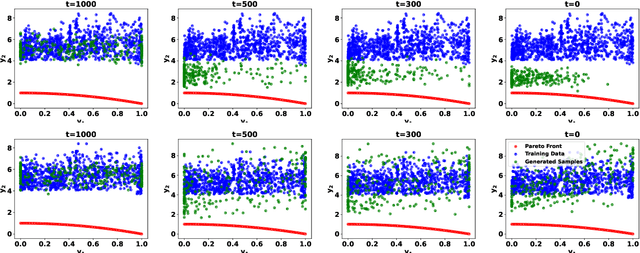
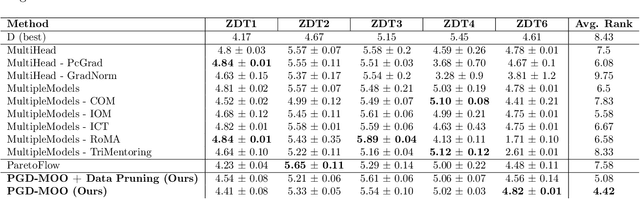
Offline multi-objective optimization aims to identify Pareto-optimal solutions given a dataset of designs and their objective values. In this work, we propose a preference-guided diffusion model that generates Pareto-optimal designs by leveraging a classifier-based guidance mechanism. Our guidance classifier is a preference model trained to predict the probability that one design dominates another, directing the diffusion model toward optimal regions of the design space. Crucially, this preference model generalizes beyond the training distribution, enabling the discovery of Pareto-optimal solutions outside the observed dataset. We introduce a novel diversity-aware preference guidance, augmenting Pareto dominance preference with diversity criteria. This ensures that generated solutions are optimal and well-distributed across the objective space, a capability absent in prior generative methods for offline multi-objective optimization. We evaluate our approach on various continuous offline multi-objective optimization tasks and find that it consistently outperforms other inverse/generative approaches while remaining competitive with forward/surrogate-based optimization methods. Our results highlight the effectiveness of classifier-guided diffusion models in generating diverse and high-quality solutions that approximate the Pareto front well.