 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoHeight-Bench: Towards Height-Aware Multimodal Reasoning in Remote Sensing
Mar 26, 2026Current Large Multimodal Models (LMMs) in Earth Observation typically neglect the critical "vertical" dimension, limiting their reasoning capabilities in complex remote sensing geometries and disaster scenarios where physical spatial structures often outweigh planar visual textures. To bridge this gap, we introduce a comprehensive evaluation framework dedicated to height-aware remote sensing understanding. First, to overcome the severe scarcity of annotated data, we develop a scalable, VLM-driven data generation pipeline utilizing systematic prompt engineering and metadata extraction. This pipeline constructs two complementary benchmarks: GeoHeight-Bench for relative height analysis, and a more challenging GeoHeight-Bench+ for holistic, terrain-aware reasoning. Furthermore, to validate the necessity of height perception, we propose GeoHeightChat, the first height-aware remote sensing LMM baseline. Serving as a strong proof of concept, our baseline demonstrates that synergizing visual semantics with implicitly injected height geometric features effectively mitigates the "vertical blind spot", successfully unlocking a new paradigm of interactive height reasoning in existing optical models.
TerraScope: Pixel-Grounded Visual Reasoning for Earth Observation
Mar 19, 2026Vision-language models (VLMs) have shown promise in earth observation (EO), yet they struggle with tasks that require grounding complex spatial reasoning in precise pixel-level visual representations. To address this problem, we introduce TerraScope, a unified VLM that delivers pixel-grounded geospatial reasoning with two key capabilities: (1) modality-flexible reasoning: it handles single-modality inputs (optical or SAR) and adaptively fuses different modalities into the reasoning process when both are available; (2) multi-temporal reasoning: it integrates temporal sequences for change analysis across multiple time points. In addition, we curate Terra-CoT, a large-scale dataset containing 1 million samples with pixel-level masks embedded in reasoning chains across multiple sources. We also propose TerraScope-Bench, the first benchmark for pixel-grounded geospatial reasoning with six sub-tasks that evaluates both answer accuracy and mask quality to ensure authentic pixel-grounded reasoning. Experiments show that TerraScope significantly outperforms existing VLMs on pixel-grounded geospatial reasoning while providing interpretable visual evidence.
EO-VAE: Towards A Multi-sensor Tokenizer for Earth Observation Data
Feb 12, 2026State-of-the-art generative image and video models rely heavily on tokenizers that compress high-dimensional inputs into more efficient latent representations. While this paradigm has revolutionized RGB generation, Earth observation (EO) data presents unique challenges due to diverse sensor specifications and variable spectral channels. We propose EO-VAE, a multi-sensor variational autoencoder designed to serve as a foundational tokenizer for the EO domain. Unlike prior approaches that train separate tokenizers for each modality, EO-VAE utilizes a single model to encode and reconstruct flexible channel combinations via dynamic hypernetworks. Our experiments on the TerraMesh dataset demonstrate that EO-VAE achieves superior reconstruction fidelity compared to the TerraMind tokenizers, establishing a robust baseline for latent generative modeling in remote sensing.
REOBench: Benchmarking Robustness of Earth Observation Foundation Models
May 22, 2025Earth observation foundation models have shown strong generalization across multiple Earth observation tasks, but their robustness under real-world perturbations remains underexplored. To bridge this gap, we introduce REOBench, the first comprehensive benchmark for evaluating the robustness of Earth observation foundation models across six tasks and twelve types of image corruptions, including both appearance-based and geometric perturbations. To ensure realistic and fine-grained evaluation, our benchmark focuses on high-resolution optical remote sensing images, which are widely used in critical applications such as urban planning and disaster response. We conduct a systematic evaluation of a broad range of models trained using masked image modeling, contrastive learning, and vision-language pre-training paradigms. Our results reveal that (1) existing Earth observation foundation models experience significant performance degradation when exposed to input corruptions. (2) The severity of degradation varies across tasks, model architectures, backbone sizes, and types of corruption, with performance drop varying from less than 1% to over 20%. (3) Vision-language models show enhanced robustness, particularly in multimodal tasks. REOBench underscores the vulnerability of current Earth observation foundation models to real-world corruptions and provides actionable insights for developing more robust and reliable models.
GlobalGeoTree: A Multi-Granular Vision-Language Dataset for Global Tree Species Classification
May 18, 2025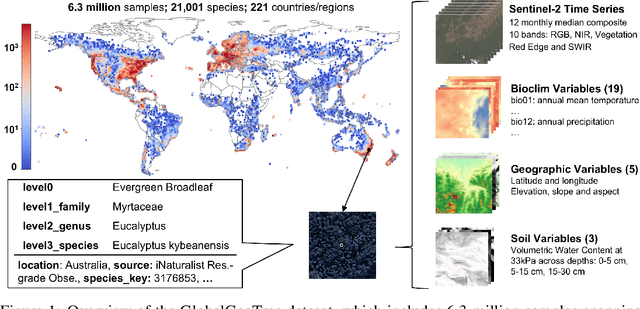
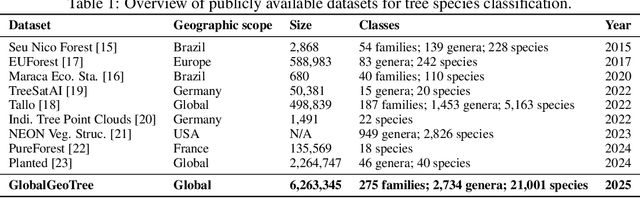
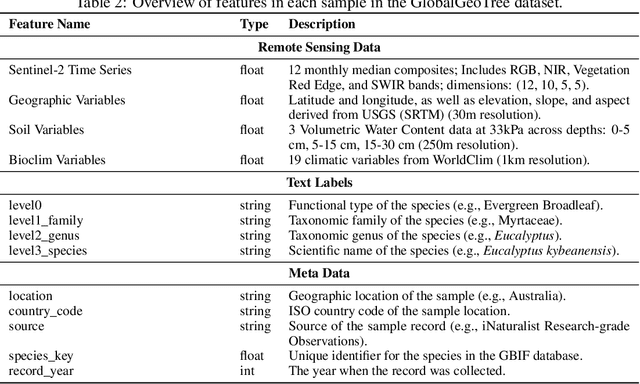
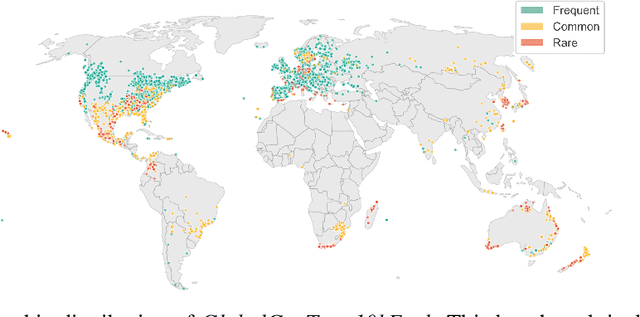
Global tree species mapping using remote sensing data is vital for biodiversity monitoring, forest management, and ecological research. However, progress in this field has been constrained by the scarcity of large-scale, labeled datasets. To address this, we introduce GlobalGeoTree, a comprehensive global dataset for tree species classification. GlobalGeoTree comprises 6.3 million geolocated tree occurrences, spanning 275 families, 2,734 genera, and 21,001 species across the hierarchical taxonomic levels. Each sample is paired with Sentinel-2 image time series and 27 auxiliary environmental variables, encompassing bioclimatic, geographic, and soil data. The dataset is partitioned into GlobalGeoTree-6M for model pretraining and curated evaluation subsets, primarily GlobalGeoTree-10kEval for zero-shot and few-shot benchmarking. To demonstrate the utility of the dataset, we introduce a baseline model, GeoTreeCLIP, which leverages paired remote sensing data and taxonomic text labels within a vision-language framework pretrained on GlobalGeoTree-6M. Experimental results show that GeoTreeCLIP achieves substantial improvements in zero- and few-shot classification on GlobalGeoTree-10kEval over existing advanced models. By making the dataset, models, and code publicly available, we aim to establish a benchmark to advance tree species classification and foster innovation in biodiversity research and ecological applications.
ExEBench: Benchmarking Foundation Models on Extreme Earth Events
May 13, 2025Our planet is facing increasingly frequent extreme events, which pose major risks to human lives and ecosystems. Recent advances in machine learning (ML), especially with foundation models (FMs) trained on extensive datasets, excel in extracting features and show promise in disaster management. Nevertheless, these models often inherit biases from training data, challenging their performance over extreme values. To explore the reliability of FM in the context of extreme events, we introduce \textbf{ExE}Bench (\textbf{Ex}treme \textbf{E}arth Benchmark), a collection of seven extreme event categories across floods, wildfires, storms, tropical cyclones, extreme precipitation, heatwaves, and cold waves. The dataset features global coverage, varying data volumes, and diverse data sources with different spatial, temporal, and spectral characteristics. To broaden the real-world impact of FMs, we include multiple challenging ML tasks that are closely aligned with operational needs in extreme events detection, monitoring, and forecasting. ExEBench aims to (1) assess FM generalizability across diverse, high-impact tasks and domains, (2) promote the development of novel ML methods that benefit disaster management, and (3) offer a platform for analyzing the interactions and cascading effects of extreme events to advance our understanding of Earth system, especially under the climate change expected in the decades to come. The dataset and code are public https://github.com/zhaoshan2/EarthExtreme-Bench.
Towards a Unified Copernicus Foundation Model for Earth Vision
Mar 14, 2025Advances in Earth observation (EO) foundation models have unlocked the potential of big satellite data to learn generic representations from space, benefiting a wide range of downstream applications crucial to our planet. However, most existing efforts remain limited to fixed spectral sensors, focus solely on the Earth's surface, and overlook valuable metadata beyond imagery. In this work, we take a step towards next-generation EO foundation models with three key components: 1) Copernicus-Pretrain, a massive-scale pretraining dataset that integrates 18.7M aligned images from all major Copernicus Sentinel missions, spanning from the Earth's surface to its atmosphere; 2) Copernicus-FM, a unified foundation model capable of processing any spectral or non-spectral sensor modality using extended dynamic hypernetworks and flexible metadata encoding; and 3) Copernicus-Bench, a systematic evaluation benchmark with 15 hierarchical downstream tasks ranging from preprocessing to specialized applications for each Sentinel mission. Our dataset, model, and benchmark greatly improve the scalability, versatility, and multimodal adaptability of EO foundation models, while also creating new opportunities to connect EO, weather, and climate research. Codes, datasets and models are available at https://github.com/zhu-xlab/Copernicus-FM.
Panopticon: Advancing Any-Sensor Foundation Models for Earth Observation
Mar 13, 2025Earth observation (EO) data features diverse sensing platforms with varying spectral bands, spatial resolutions, and sensing modalities. While most prior work has constrained inputs to fixed sensors, a new class of any-sensor foundation models able to process arbitrary sensors has recently emerged. Contributing to this line of work, we propose Panopticon, an any-sensor foundation model built on the DINOv2 framework. We extend DINOv2 by (1) treating images of the same geolocation across sensors as natural augmentations, (2) subsampling channels to diversify spectral input, and (3) adding a cross attention over channels as a flexible patch embedding mechanism. By encoding the wavelength and modes of optical and synthetic aperture radar sensors, respectively, Panopticon can effectively process any combination of arbitrary channels. In extensive evaluations, we achieve state-of-the-art performance on GEO-Bench, especially on the widely-used Sentinel-1 and Sentinel-2 sensors, while out-competing other any-sensor models, as well as domain adapted fixed-sensor models on unique sensor configurations. Panopticon enables immediate generalization to both existing and future satellite platforms, advancing sensor-agnostic EO.
GeoLangBind: Unifying Earth Observation with Agglomerative Vision-Language Foundation Models
Mar 08, 2025Earth observation (EO) data, collected from diverse sensors with varying imaging principles, present significant challenges in creating unified analytical frameworks. We present GeoLangBind, a novel agglomerative vision--language foundation model that bridges the gap between heterogeneous EO data modalities using language as a unifying medium. Our approach aligns different EO data types into a shared language embedding space, enabling seamless integration and complementary feature learning from diverse sensor data. To achieve this, we construct a large-scale multimodal image--text dataset, GeoLangBind-2M, encompassing six data modalities. GeoLangBind leverages this dataset to develop a zero-shot foundation model capable of processing arbitrary numbers of EO data channels as input. Through our designed Modality-aware Knowledge Agglomeration (MaKA) module and progressive multimodal weight merging strategy, we create a powerful agglomerative foundation model that excels in both zero-shot vision--language comprehension and fine-grained visual understanding. Extensive evaluation across 23 datasets covering multiple tasks demonstrates GeoLangBind's superior performance and versatility in EO applications, offering a robust framework for various environmental monitoring and analysis tasks. The dataset and pretrained models will be publicly available.
Beyond Grid Data: Exploring Graph Neural Networks for Earth Observation
Nov 05, 2024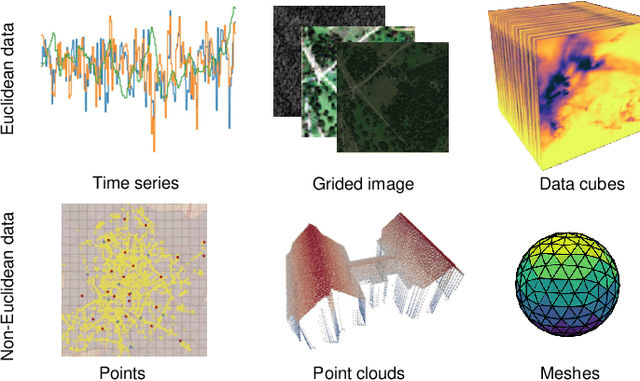
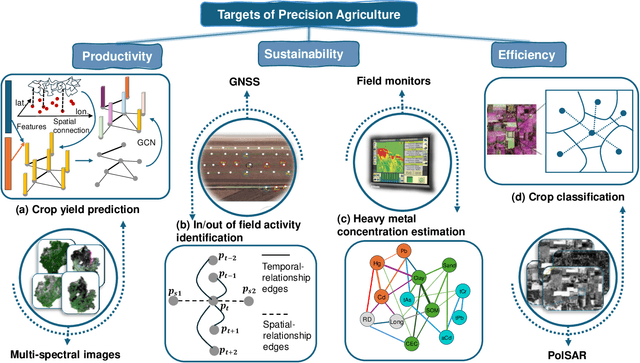

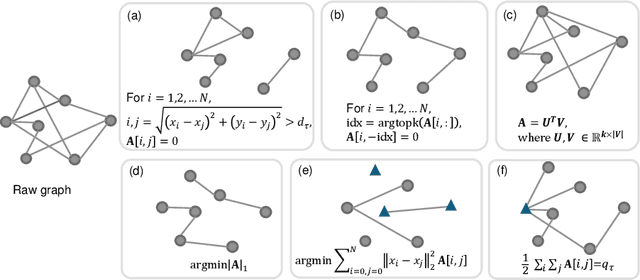
Earth Observation (EO) data analysis has been significantly revolutionized by deep learning (DL), with applications typically limited to grid-like data structures. Graph Neural Networks (GNNs) emerge as an important innovation, propelling DL into the non-Euclidean domain. Naturally, GNNs can effectively tackle the challenges posed by diverse modalities, multiple sensors, and the heterogeneous nature of EO data. To introduce GNNs in the related domains, our review begins by offering fundamental knowledge on GNNs. Then, we summarize the generic problems in EO, to which GNNs can offer potential solutions. Following this, we explore a broad spectrum of GNNs' applications to scientific problems in Earth systems, covering areas such as weather and climate analysis, disaster management, air quality monitoring, agriculture, land cover classification, hydrological process modeling, and urban modeling. The rationale behind adopting GNNs in these fields is explained, alongside methodologies for organizing graphs and designing favorable architectures for various tasks. Furthermore, we highlight methodological challenges of implementing GNNs in these domains and possible solutions that could guide future research. While acknowledging that GNNs are not a universal solution, we conclude the paper by comparing them with other popular architectures like transformers and analyzing their potential synergies.