 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Unified Copernicus Foundation Model for Earth Vision
Mar 14, 2025Advances in Earth observation (EO) foundation models have unlocked the potential of big satellite data to learn generic representations from space, benefiting a wide range of downstream applications crucial to our planet. However, most existing efforts remain limited to fixed spectral sensors, focus solely on the Earth's surface, and overlook valuable metadata beyond imagery. In this work, we take a step towards next-generation EO foundation models with three key components: 1) Copernicus-Pretrain, a massive-scale pretraining dataset that integrates 18.7M aligned images from all major Copernicus Sentinel missions, spanning from the Earth's surface to its atmosphere; 2) Copernicus-FM, a unified foundation model capable of processing any spectral or non-spectral sensor modality using extended dynamic hypernetworks and flexible metadata encoding; and 3) Copernicus-Bench, a systematic evaluation benchmark with 15 hierarchical downstream tasks ranging from preprocessing to specialized applications for each Sentinel mission. Our dataset, model, and benchmark greatly improve the scalability, versatility, and multimodal adaptability of EO foundation models, while also creating new opportunities to connect EO, weather, and climate research. Codes, datasets and models are available at https://github.com/zhu-xlab/Copernicus-FM.
GeoLangBind: Unifying Earth Observation with Agglomerative Vision-Language Foundation Models
Mar 08, 2025Earth observation (EO) data, collected from diverse sensors with varying imaging principles, present significant challenges in creating unified analytical frameworks. We present GeoLangBind, a novel agglomerative vision--language foundation model that bridges the gap between heterogeneous EO data modalities using language as a unifying medium. Our approach aligns different EO data types into a shared language embedding space, enabling seamless integration and complementary feature learning from diverse sensor data. To achieve this, we construct a large-scale multimodal image--text dataset, GeoLangBind-2M, encompassing six data modalities. GeoLangBind leverages this dataset to develop a zero-shot foundation model capable of processing arbitrary numbers of EO data channels as input. Through our designed Modality-aware Knowledge Agglomeration (MaKA) module and progressive multimodal weight merging strategy, we create a powerful agglomerative foundation model that excels in both zero-shot vision--language comprehension and fine-grained visual understanding. Extensive evaluation across 23 datasets covering multiple tasks demonstrates GeoLangBind's superior performance and versatility in EO applications, offering a robust framework for various environmental monitoring and analysis tasks. The dataset and pretrained models will be publicly available.
On the Foundations of Earth and Climate Foundation Models
May 07, 2024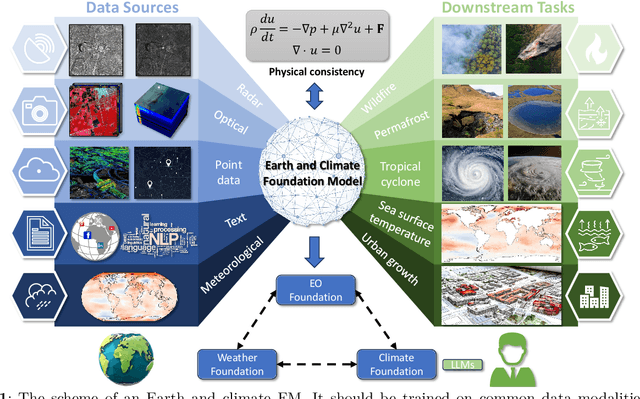

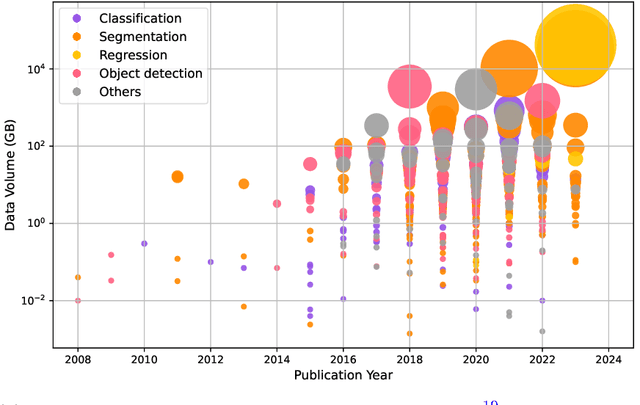
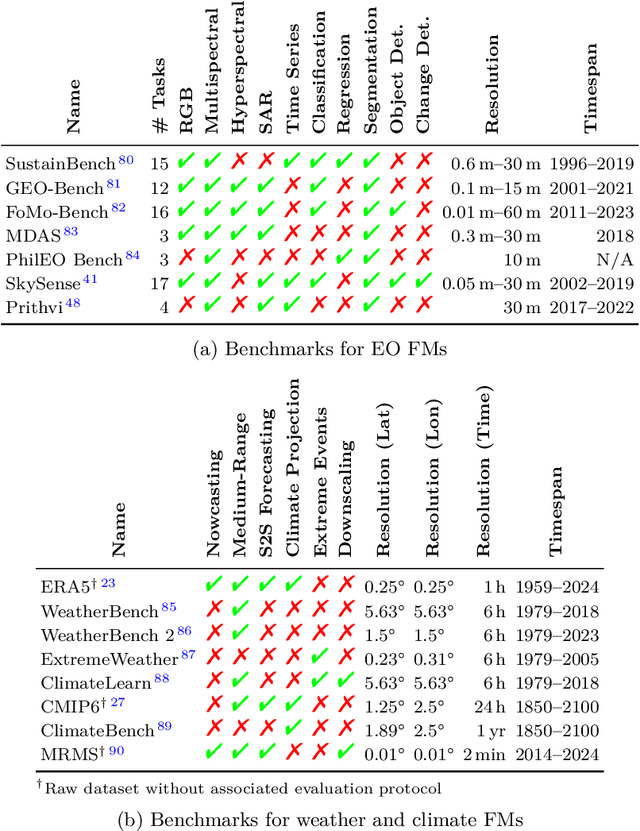
Foundation models have enormous potential in advancing Earth and climate sciences, however, current approaches may not be optimal as they focus on a few basic features of a desirable Earth and climate foundation model. Crafting the ideal Earth foundation model, we define eleven features which would allow such a foundation model to be beneficial for any geoscientific downstream application in an environmental- and human-centric manner.We further shed light on the way forward to achieve the ideal model and to evaluate Earth foundation models. What comes after foundation models? Energy efficient adaptation, adversarial defenses, and interpretability are among the emerging directions.