 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison Study: Glacier Calving Front Delineation in Synthetic Aperture Radar Images With Deep Learning
Jan 09, 2025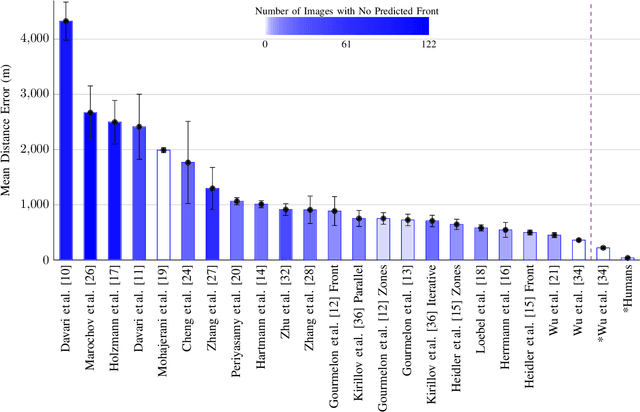
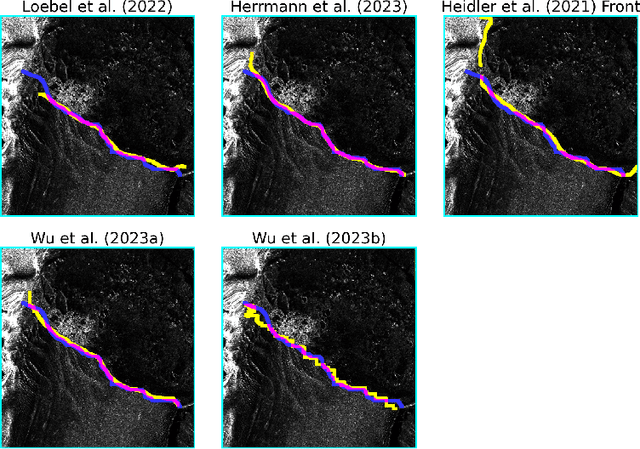


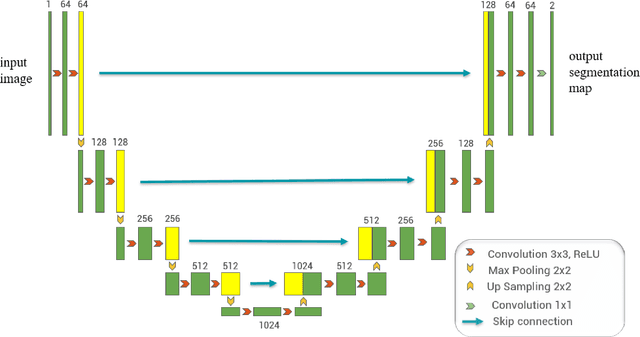
Calving front position variation of marine-terminating glaciers is an indicator of ice mass loss and a crucial parameter in numerical glacier models. Deep Learning (DL) systems can automatically extract this position from Synthetic Aperture Radar (SAR) imagery, enabling continuous, weather- and illumination-independent, large-scale monitoring. This study presents the first comparison of DL systems on a common calving front benchmark dataset. A multi-annotator study with ten annotators is performed to contrast the best-performing DL system against human performance. The best DL model's outputs deviate 221 m on average, while the average deviation of the human annotators is 38 m. This significant difference shows that current DL systems do not yet match human performance and that further research is needed to enable fully automated monitoring of glacier calving fronts. The study of Vision Transformers, foundation models, and the inclusion and processing strategy of more information are identified as avenues for future research.
Multi-Sensor Deep Learning for Glacier Mapping
Sep 18, 2024



The more than 200,000 glaciers outside the ice sheets play a crucial role in our society by influencing sea-level rise, water resource management, natural hazards, biodiversity, and tourism. However, only a fraction of these glaciers benefit from consistent and detailed in-situ observations that allow for assessing their status and changes over time. This limitation can, in part, be overcome by relying on satellite-based Earth Observation techniques. Satellite-based glacier mapping applications have historically mainly relied on manual and semi-automatic detection methods, while recently, a fast and notable transition to deep learning techniques has started. This chapter reviews how combining multi-sensor remote sensing data and deep learning allows us to better delineate (i.e. map) glaciers and detect their temporal changes. We explain how relying on deep learning multi-sensor frameworks to map glaciers benefits from the extensive availability of regional and global glacier inventories. We also analyse the rationale behind glacier mapping, the benefits of deep learning methodologies, and the inherent challenges in integrating multi-sensor earth observation data with deep learning algorithms. While our review aims to provide a broad overview of glacier mapping efforts, we highlight a few setups where deep learning multi-sensor remote sensing applications have a considerable potential added value. This includes applications for debris-covered and rock glaciers that are visually difficult to distinguish from surroundings and for calving glaciers that are in contact with the ocean. These specific cases are illustrated through a series of visual imageries, highlighting some significant advantages and challenges when detecting glacier changes, including dealing with seasonal snow cover, changing debris coverage, and distinguishing glacier fronts from the surrounding sea ice.
Machine Learning for Methane Detection and Quantification from Space - A survey
Aug 27, 2024


Methane ($CH_4$) is a potent anthropogenic greenhouse gas, contributing 86 times more to global warming than Carbon Dioxide ($CO_2$) over 20 years, and it also acts as an air pollutant. Given its high radiative forcing potential and relatively short atmospheric lifetime (9$\pm$1 years), methane has important implications for climate change, therefore, cutting methane emissions is crucial for effective climate change mitigation. This work expands existing information on operational methane point source detection sensors in the Short-Wave Infrared (SWIR) bands. It reviews the state-of-the-art for traditional as well as Machine Learning (ML) approaches. The architecture and data used in such ML models will be discussed separately for methane plume segmentation and emission rate estimation. Traditionally, experts rely on labor-intensive manually adjusted methods for methane detection. However, ML approaches offer greater scalability. Our analysis reveals that ML models outperform traditional methods, particularly those based on convolutional neural networks (CNN), which are based on the U-net and transformer architectures. These ML models extract valuable information from methane-sensitive spectral data, enabling a more accurate detection. Challenges arise when comparing these methods due to variations in data, sensor specifications, and evaluation metrics. To address this, we discuss existing datasets and metrics, providing an overview of available resources and identifying open research problems. Finally, we explore potential future advances in ML, emphasizing approaches for model comparability, large dataset creation, and the European Union's forthcoming methane strategy.
On the Foundations of Earth and Climate Foundation Models
May 07, 2024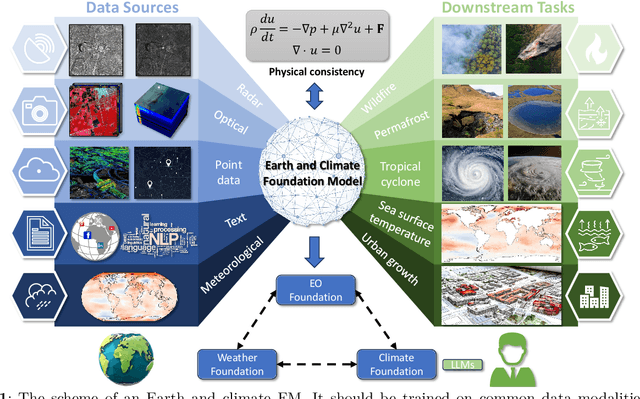

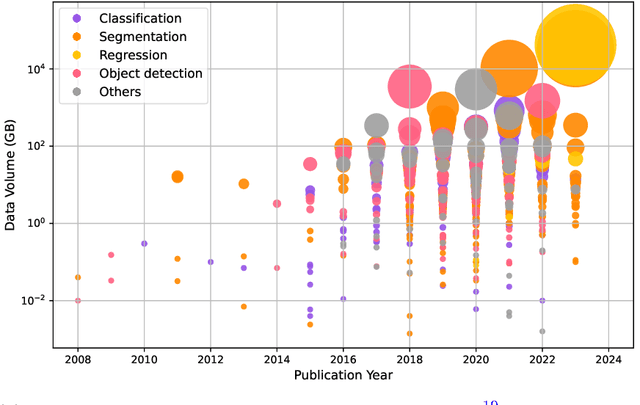
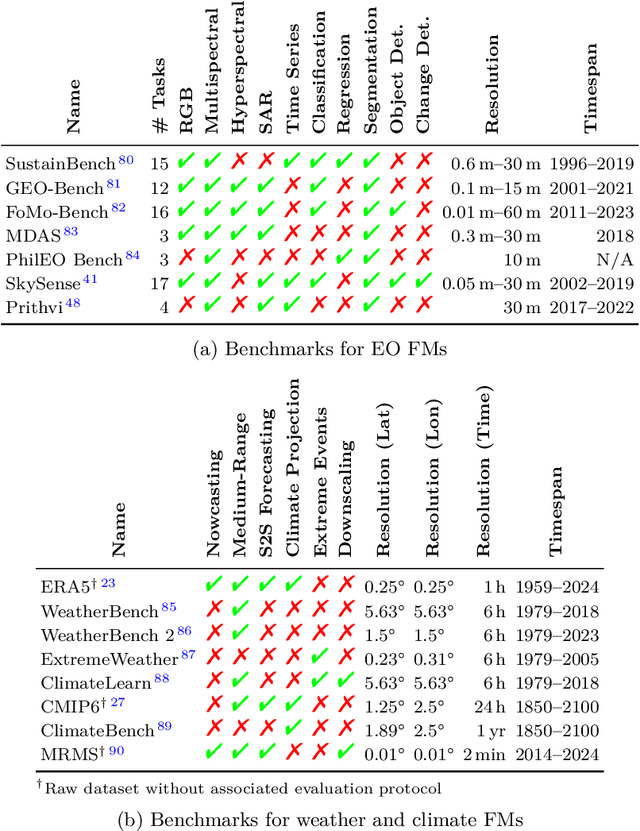
Foundation models have enormous potential in advancing Earth and climate sciences, however, current approaches may not be optimal as they focus on a few basic features of a desirable Earth and climate foundation model. Crafting the ideal Earth foundation model, we define eleven features which would allow such a foundation model to be beneficial for any geoscientific downstream application in an environmental- and human-centric manner.We further shed light on the way forward to achieve the ideal model and to evaluate Earth foundation models. What comes after foundation models? Energy efficient adaptation, adversarial defenses, and interpretability are among the emerging directions.
PixelDINO: Semi-Supervised Semantic Segmentation for Detecting Permafrost Disturbances
Jan 17, 2024



Arctic Permafrost is facing significant changes due to global climate change. As these regions are largely inaccessible, remote sensing plays a crucial rule in better understanding the underlying processes not just on a local scale, but across the Arctic. In this study, we focus on the remote detection of retrogressive thaw slumps (RTS), a permafrost disturbance comparable to landslides induced by thawing. For such analyses from space, deep learning has become an indispensable tool, but limited labelled training data remains a challenge for training accurate models. To improve model generalization across the Arctic without the need for additional labelled data, we present a semi-supervised learning approach to train semantic segmentation models to detect RTS. Our framework called PixelDINO is trained in parallel on labelled data as well as unlabelled data. For the unlabelled data, the model segments the imagery into self-taught pseudo-classes and the training procedure ensures consistency of these pseudo-classes across strong augmentations of the input data. Our experimental results demonstrate that PixelDINO can improve model performance both over supervised baseline methods as well as existing semi-supervised semantic segmentation approaches, highlighting its potential for training robust models that generalize well to regions that were not included in the training data. The project page containing code and other materials for this study can be found at \url{https://khdlr.github.io/PixelDINO/}.
A Deep Active Contour Model for Delineating Glacier Calving Fronts
Jul 07, 2023



Choosing how to encode a real-world problem as a machine learning task is an important design decision in machine learning. The task of glacier calving front modeling has often been approached as a semantic segmentation task. Recent studies have shown that combining segmentation with edge detection can improve the accuracy of calving front detectors. Building on this observation, we completely rephrase the task as a contour tracing problem and propose a model for explicit contour detection that does not incorporate any dense predictions as intermediate steps. The proposed approach, called ``Charting Outlines by Recurrent Adaptation'' (COBRA), combines Convolutional Neural Networks (CNNs) for feature extraction and active contour models for the delineation. By training and evaluating on several large-scale datasets of Greenland's outlet glaciers, we show that this approach indeed outperforms the aforementioned methods based on segmentation and edge-detection. Finally, we demonstrate that explicit contour detection has benefits over pixel-wise methods when quantifying the models' prediction uncertainties. The project page containing the code and animated model predictions can be found at \url{https://khdlr.github.io/COBRA/}.
Self-supervised Audiovisual Representation Learning for Remote Sensing Data
Aug 02, 2021
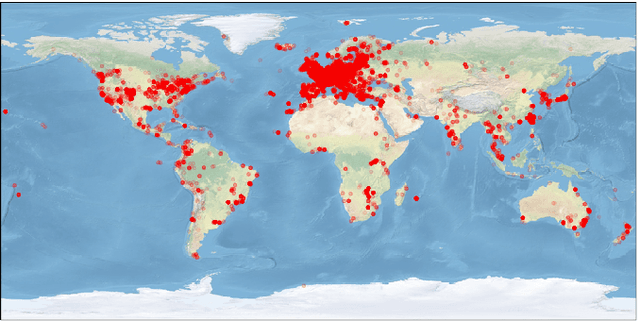
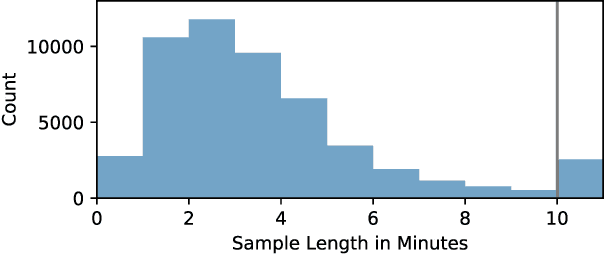
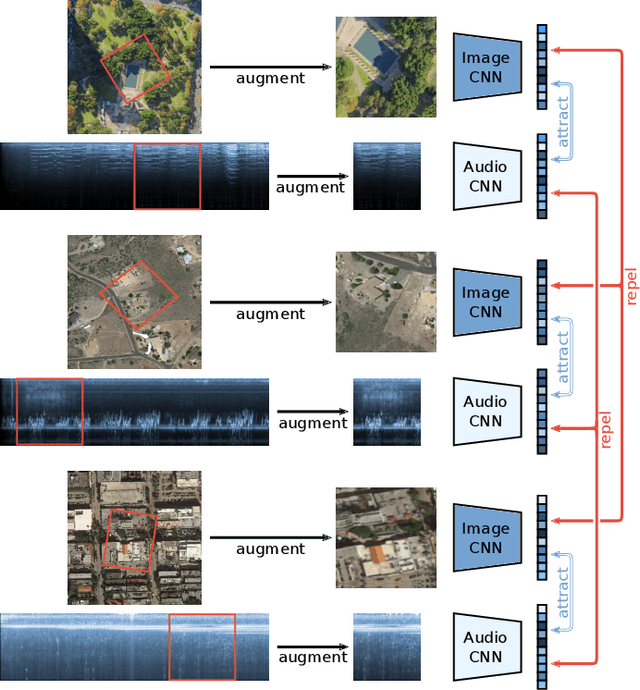
Many current deep learning approaches make extensive use of backbone networks pre-trained on large datasets like ImageNet, which are then fine-tuned to perform a certain task. In remote sensing, the lack of comparable large annotated datasets and the wide diversity of sensing platforms impedes similar developments. In order to contribute towards the availability of pre-trained backbone networks in remote sensing, we devise a self-supervised approach for pre-training deep neural networks. By exploiting the correspondence between geo-tagged audio recordings and remote sensing imagery, this is done in a completely label-free manner, eliminating the need for laborious manual annotation. For this purpose, we introduce the SoundingEarth dataset, which consists of co-located aerial imagery and audio samples all around the world. Using this dataset, we then pre-train ResNet models to map samples from both modalities into a common embedding space, which encourages the models to understand key properties of a scene that influence both visual and auditory appearance. To validate the usefulness of the proposed approach, we evaluate the transfer learning performance of pre-trained weights obtained against weights obtained through other means. By fine-tuning the models on a number of commonly used remote sensing datasets, we show that our approach outperforms existing pre-training strategies for remote sensing imagery. The dataset, code and pre-trained model weights will be available at https://github.com/khdlr/SoundingEarth.
Aerial Scene Understanding in The Wild: Multi-Scene Recognition via Prototype-based Memory Networks
Apr 22, 2021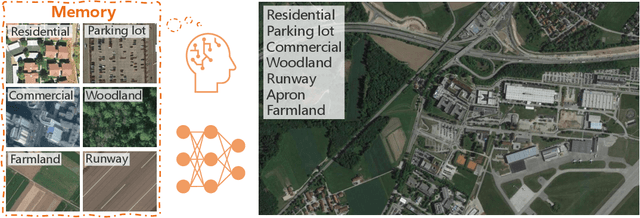
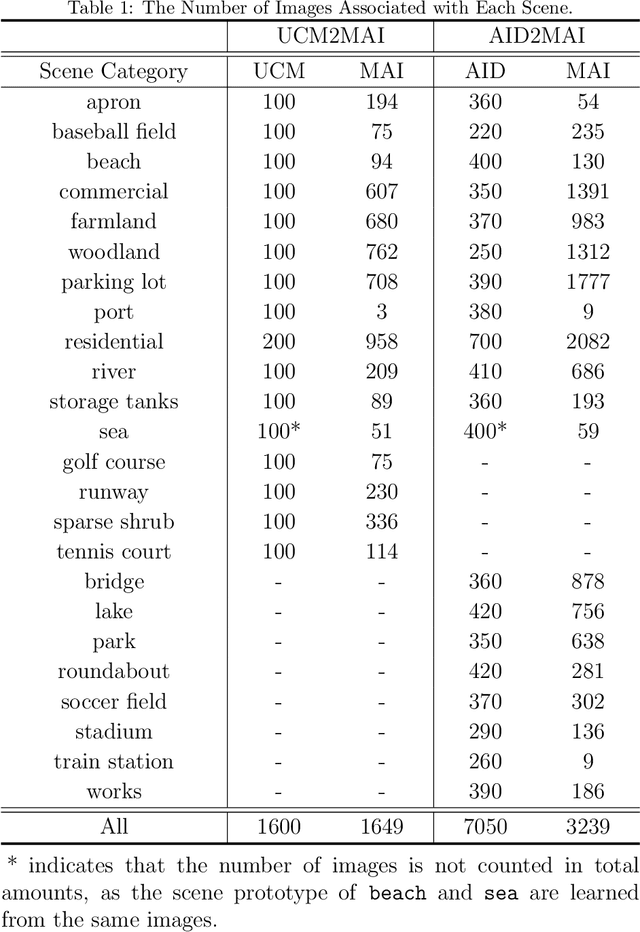
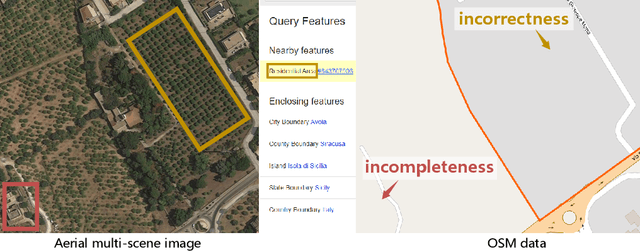

Aerial scene recognition is a fundamental visual task and has attracted an increasing research interest in the last few years. Most of current researches mainly deploy efforts to categorize an aerial image into one scene-level label, while in real-world scenarios, there often exist multiple scenes in a single image. Therefore, in this paper, we propose to take a step forward to a more practical and challenging task, namely multi-scene recognition in single images. Moreover, we note that manually yielding annotations for such a task is extraordinarily time- and labor-consuming. To address this, we propose a prototype-based memory network to recognize multiple scenes in a single image by leveraging massive well-annotated single-scene images. The proposed network consists of three key components: 1) a prototype learning module, 2) a prototype-inhabiting external memory, and 3) a multi-head attention-based memory retrieval module. To be more specific, we first learn the prototype representation of each aerial scene from single-scene aerial image datasets and store it in an external memory. Afterwards, a multi-head attention-based memory retrieval module is devised to retrieve scene prototypes relevant to query multi-scene images for final predictions. Notably, only a limited number of annotated multi-scene images are needed in the training phase. To facilitate the progress of aerial scene recognition, we produce a new multi-scene aerial image (MAI) dataset. Experimental results on variant dataset configurations demonstrate the effectiveness of our network. Our dataset and codes are publicly available.
HED-UNet: Combined Segmentation and Edge Detection for Monitoring the Antarctic Coastline
Mar 02, 2021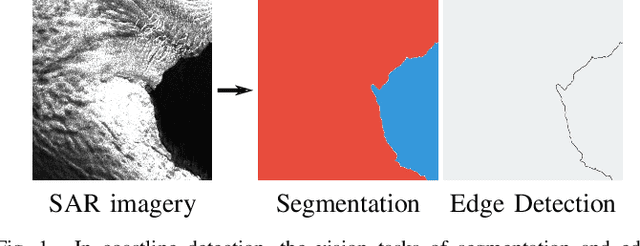
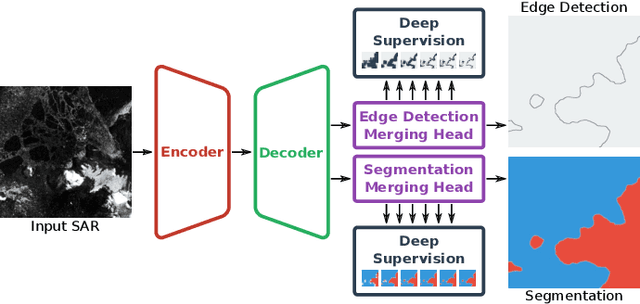
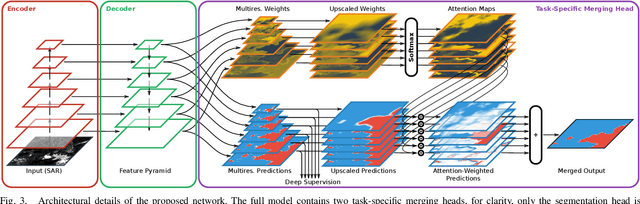
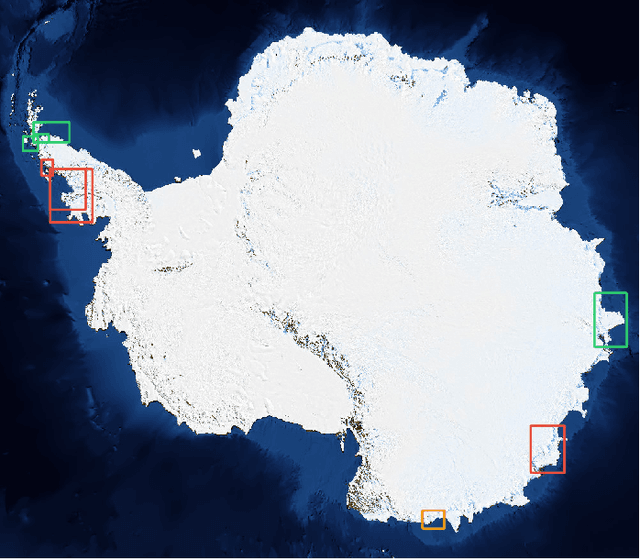
Deep learning-based coastline detection algorithms have begun to outshine traditional statistical methods in recent years. However, they are usually trained only as single-purpose models to either segment land and water or delineate the coastline. In contrast to this, a human annotator will usually keep a mental map of both segmentation and delineation when performing manual coastline detection. To take into account this task duality, we therefore devise a new model to unite these two approaches in a deep learning model. By taking inspiration from the main building blocks of a semantic segmentation framework (UNet) and an edge detection framework (HED), both tasks are combined in a natural way. Training is made efficient by employing deep supervision on side predictions at multiple resolutions. Finally, a hierarchical attention mechanism is introduced to adaptively merge these multiscale predictions into the final model output. The advantages of this approach over other traditional and deep learning-based methods for coastline detection are demonstrated on a dataset of Sentinel-1 imagery covering parts of the Antarctic coast, where coastline detection is notoriously difficult. An implementation of our method is available at \url{https://github.com/khdlr/HED-UNet}.