 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison Study: Glacier Calving Front Delineation in Synthetic Aperture Radar Images With Deep Learning
Jan 09, 2025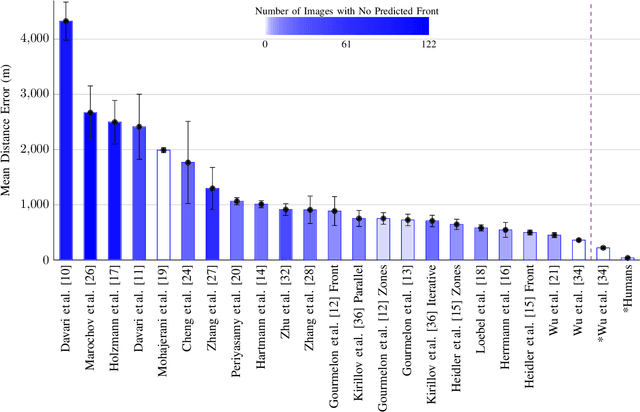
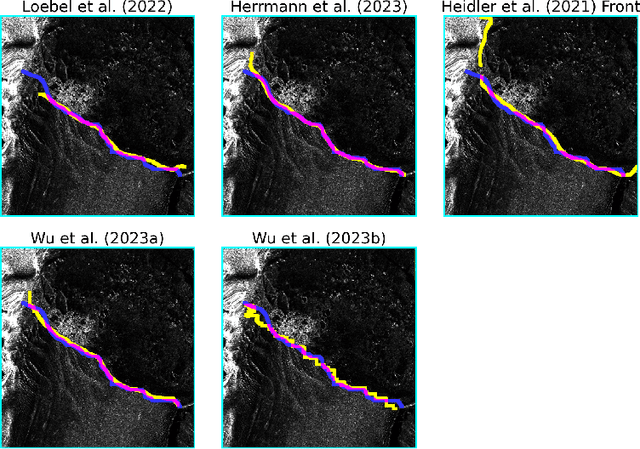


Calving front position variation of marine-terminating glaciers is an indicator of ice mass loss and a crucial parameter in numerical glacier models. Deep Learning (DL) systems can automatically extract this position from Synthetic Aperture Radar (SAR) imagery, enabling continuous, weather- and illumination-independent, large-scale monitoring. This study presents the first comparison of DL systems on a common calving front benchmark dataset. A multi-annotator study with ten annotators is performed to contrast the best-performing DL system against human performance. The best DL model's outputs deviate 221 m on average, while the average deviation of the human annotators is 38 m. This significant difference shows that current DL systems do not yet match human performance and that further research is needed to enable fully automated monitoring of glacier calving fronts. The study of Vision Transformers, foundation models, and the inclusion and processing strategy of more information are identified as avenues for future research.
Expectations Versus Reality: Evaluating Intrusion Detection Systems in Practice
Mar 28, 2024



Our paper provides empirical comparisons between recent IDSs to provide an objective comparison between them to help users choose the most appropriate solution based on their requirements. Our results show that no one solution is the best, but is dependent on external variables such as the types of attacks, complexity, and network environment in the dataset. For example, BoT_IoT and Stratosphere IoT datasets both capture IoT-related attacks, but the deep neural network performed the best when tested using the BoT_IoT dataset while HELAD performed the best when tested using the Stratosphere IoT dataset. So although we found that a deep neural network solution had the highest average F1 scores on tested datasets, it is not always the best-performing one. We further discuss difficulties in using IDS from literature and project repositories, which complicated drawing definitive conclusions regarding IDS selection.
Multi-line AI-assisted Code Authoring
Feb 06, 2024
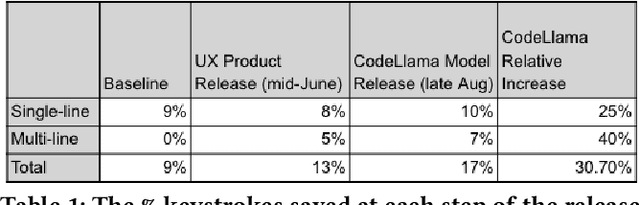
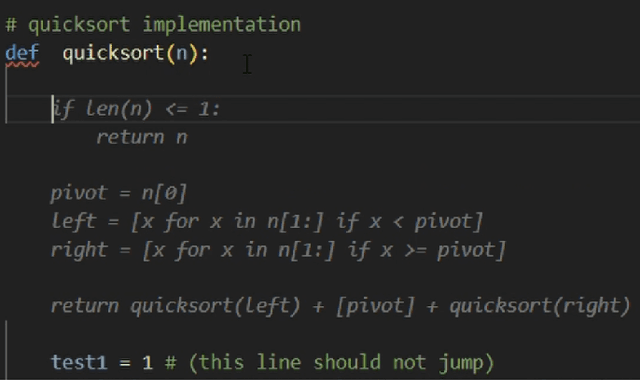

CodeCompose is an AI-assisted code authoring tool powered by large language models (LLMs) that provides inline suggestions to 10's of thousands of developers at Meta. In this paper, we present how we scaled the product from displaying single-line suggestions to multi-line suggestions. This evolution required us to overcome several unique challenges in improving the usability of these suggestions for developers. First, we discuss how multi-line suggestions can have a 'jarring' effect, as the LLM's suggestions constantly move around the developer's existing code, which would otherwise result in decreased productivity and satisfaction. Second, multi-line suggestions take significantly longer to generate; hence we present several innovative investments we made to reduce the perceived latency for users. These model-hosting optimizations sped up multi-line suggestion latency by 2.5x. Finally, we conduct experiments on 10's of thousands of engineers to understand how multi-line suggestions impact the user experience and contrast this with single-line suggestions. Our experiments reveal that (i) multi-line suggestions account for 42% of total characters accepted (despite only accounting for 16% for displayed suggestions) (ii) multi-line suggestions almost doubled the percentage of keystrokes saved for users from 9% to 17%. Multi-line CodeCompose has been rolled out to all engineers at Meta, and less than 1% of engineers have opted out of multi-line suggestions.
ACID: Abstractive, Content-Based IDs for Document Retrieval with Language Models
Nov 14, 2023



Generative retrieval (Wang et al., 2022; Tay et al., 2022) is a new approach for end-to-end document retrieval that directly generates document identifiers given an input query. Techniques for designing effective, high-quality document IDs remain largely unexplored. We introduce ACID, in which each document's ID is composed of abstractive keyphrases generated by a large language model, rather than an integer ID sequence as done in past work. We compare our method with the current state-of-the-art technique for ID generation, which produces IDs through hierarchical clustering of document embeddings. We also examine simpler methods to generate natural-language document IDs, including the naive approach of using the first k words of each document as its ID or words with high BM25 scores in that document. We show that using ACID improves top-10 and top-20 accuracy by 15.6% and 14.4% (relative) respectively versus the state-of-the-art baseline on the MSMARCO 100k retrieval task, and 4.4% and 4.0% respectively on the Natural Questions 100k retrieval task. Our results demonstrate the effectiveness of human-readable, natural-language IDs in generative retrieval with LMs. The code for reproducing our results and the keyword-augmented datasets will be released on formal publication.
CodeCompose: A Large-Scale Industrial Deployment of AI-assisted Code Authoring
May 20, 2023



The rise of large language models (LLMs) has unlocked various applications of this technology in software development. In particular, generative LLMs have been shown to effectively power AI-based code authoring tools that can suggest entire statements or blocks of code during code authoring. In this paper we present CodeCompose, an AI-assisted code authoring tool developed and deployed at Meta internally. CodeCompose is based on the InCoder LLM that merges generative capabilities with bi-directionality. We have scaled up CodeCompose to serve tens of thousands of developers at Meta, across 10+ programming languages and several coding surfaces. We discuss unique challenges in terms of user experience and metrics that arise when deploying such tools in large-scale industrial settings. We present our experience in making design decisions about the model and system architecture for CodeCompose that addresses these challenges. Finally, we present metrics from our large-scale deployment of CodeCompose that shows its impact on Meta's internal code authoring experience over a 15-day time window, where 4.5 million suggestions were made by CodeCompose. Quantitative metrics reveal that (i) CodeCompose has an acceptance rate of 22% across several languages, and (ii) 8% of the code typed by users of CodeCompose is through accepting code suggestions from CodeCompose. Qualitative feedback indicates an overwhelming 91.5% positive reception for CodeCompose. In addition to assisting with code authoring, CodeCompose is also introducing other positive side effects such as encouraging developers to generate more in-code documentation, helping them with the discovery of new APIs, etc.
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
Jan 11, 2023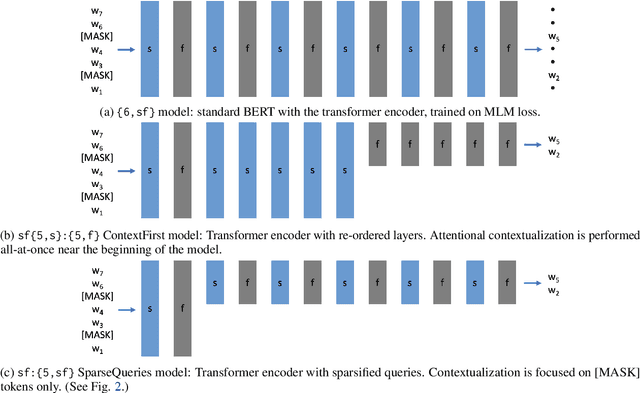

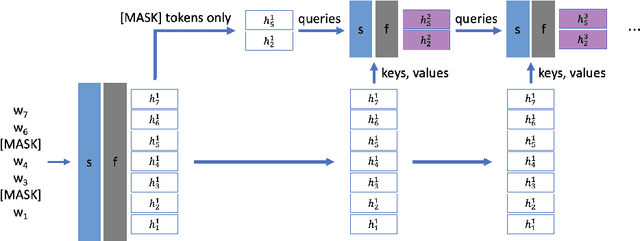
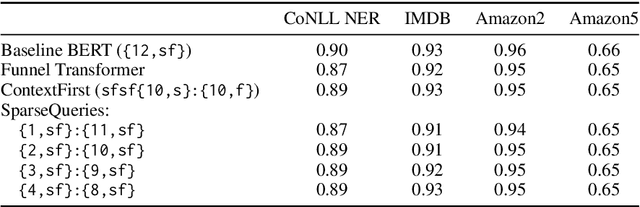
Large-scale language model pretraining is a very successful form of self-supervised learning in natural language processing, but it is increasingly expensive to perform as the models and pretraining corpora have become larger over time. We propose NarrowBERT, a modified transformer encoder that increases the throughput for masked language model pretraining by more than $2\times$. NarrowBERT sparsifies the transformer model such that the self-attention queries and feedforward layers only operate on the masked tokens of each sentence during pretraining, rather than all of the tokens as with the usual transformer encoder. We also show that NarrowBERT increases the throughput at inference time by as much as $3.5\times$ with minimal (or no) performance degradation on sentence encoding tasks like MNLI. Finally, we examine the performance of NarrowBERT on the IMDB and Amazon reviews classification and CoNLL NER tasks and show that it is also comparable to standard BERT performance.