 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge language model as user daily behavior data generator: balancing population diversity and individual personality
May 23, 2025Predicting human daily behavior is challenging due to the complexity of routine patterns and short-term fluctuations. While data-driven models have improved behavior prediction by leveraging empirical data from various platforms and devices, the reliance on sensitive, large-scale user data raises privacy concerns and limits data availability. Synthetic data generation has emerged as a promising solution, though existing methods are often limited to specific applications. In this work, we introduce BehaviorGen, a framework that uses large language models (LLMs) to generate high-quality synthetic behavior data. By simulating user behavior based on profiles and real events, BehaviorGen supports data augmentation and replacement in behavior prediction models. We evaluate its performance in scenarios such as pertaining augmentation, fine-tuning replacement, and fine-tuning augmentation, achieving significant improvements in human mobility and smartphone usage predictions, with gains of up to 18.9%. Our results demonstrate the potential of BehaviorGen to enhance user behavior modeling through flexible and privacy-preserving synthetic data generation.
Enhancing Vision-Language Compositional Understanding with Multimodal Synthetic Data
Mar 03, 2025Despite impressive advancements in various multimodal tasks, vision-language models (VLMs) still struggle with compositional understanding due to limited exposure to training samples that contain subtle variations within paired examples. With advances in multimodal generative models, a natural solution is to generate synthetic samples with subtle variations for training VLMs. However, generating and training on synthetic samples with subtle variations presents two challenges: difficulty in accurately creating precise variations and inconsistency in cross-modal alignment quality. To address these challenges, we propose SVD-GT (Subtle Variation Data Generation and Training), which integrates image feature injection into a text-to-image generative model to enhance the quality of synthetic variations and employs an adaptive margin loss to differentiate samples using adaptive margins, which help filter out potentially incorrect synthetic samples and focus the learning on informative hard samples. Evaluations on four compositional understanding benchmarks demonstrate that SVD-GT significantly improves the compositionality of VLMs, boosting the average accuracy of CLIP by over 8% across all benchmarks and outperforming state-of-the-art methods by 2% on three benchmarks.
Paint Outside the Box: Synthesizing and Selecting Training Data for Visual Grounding
Dec 01, 2024Visual grounding aims to localize the image regions based on a textual query. Given the difficulty of large-scale data curation, we investigate how to effectively learn visual grounding under data-scarce settings in this paper. To address data scarcity, we propose a novel framework, POBF (Paint Outside the Box, then Filter). POBF synthesizes images by inpainting outside the box, tackling a label misalignment issue encountered in previous works. Furthermore, POBF leverages an innovative filtering scheme to identify the most effective training data. This scheme combines a hardness score and an overfitting score, balanced by a penalty term. Experimental results show that POBF achieves superior performance across four datasets, delivering an average improvement of 5.83% and outperforming leading baselines by 2.29% to 3.85% in accuracy. Additionally, we validate the robustness and generalizability of POBF across various generative models, data ratios, and model architectures.
Rationale-based Ensemble of Multiple QA Strategies for Zero-shot Knowledge-based VQA
Jun 18, 2024Knowledge-based Visual Qustion-answering (K-VQA) necessitates the use of background knowledge beyond what is depicted in the image. Current zero-shot K-VQA methods usually translate an image to a single type of textual decision context and use a text-based model to answer the question based on it, which conflicts with the fact that K-VQA questions often require the combination of multiple question-answering strategies. In light of this, we propose Rationale-based Ensemble of Answer Context Tactics (REACT) to achieve a dynamic ensemble of multiple question-answering tactics, comprising Answer Candidate Generation (ACG) and Rationale-based Strategy Fusion (RSF). In ACG, we generate three distinctive decision contexts to provide different strategies for each question, resulting in the generation of three answer candidates. RSF generates automatic and mechanistic rationales from decision contexts for each candidate, allowing the model to select the correct answer from all candidates. We conduct comprehensive experiments on the OK-VQA and A-OKVQA datasets, and our method significantly outperforms state-of-the-art LLM-based baselines on all datasets.
UltraMedical: Building Specialized Generalists in Biomedicine
Jun 06, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains and are moving towards more specialized areas. Recent advanced proprietary models such as GPT-4 and Gemini have achieved significant advancements in biomedicine, which have also raised privacy and security challenges. The construction of specialized generalists hinges largely on high-quality datasets, enhanced by techniques like supervised fine-tuning and reinforcement learning from human or AI feedback, and direct preference optimization. However, these leading technologies (e.g., preference learning) are still significantly limited in the open source community due to the scarcity of specialized data. In this paper, we present the UltraMedical collections, which consist of high-quality manual and synthetic datasets in the biomedicine domain, featuring preference annotations across multiple advanced LLMs. By utilizing these datasets, we fine-tune a suite of specialized medical models based on Llama-3 series, demonstrating breathtaking capabilities across various medical benchmarks. Moreover, we develop powerful reward models skilled in biomedical and general reward benchmark, enhancing further online preference learning within the biomedical LLM community.
Training on Synthetic Data Beats Real Data in Multimodal Relation Extraction
Dec 05, 2023



The task of multimodal relation extraction has attracted significant research attention, but progress is constrained by the scarcity of available training data. One natural thought is to extend existing datasets with cross-modal generative models. In this paper, we consider a novel problem setting, where only unimodal data, either text or image, are available during training. We aim to train a multimodal classifier from synthetic data that perform well on real multimodal test data. However, training with synthetic data suffers from two obstacles: lack of data diversity and label information loss. To alleviate the issues, we propose Mutual Information-aware Multimodal Iterated Relational dAta GEneration (MI2RAGE), which applies Chained Cross-modal Generation (CCG) to promote diversity in the generated data and exploits a teacher network to select valuable training samples with high mutual information with the ground-truth labels. Comparing our method to direct training on synthetic data, we observed a significant improvement of 24.06% F1 with synthetic text and 26.42% F1 with synthetic images. Notably, our best model trained on completely synthetic images outperforms prior state-of-the-art models trained on real multimodal data by a margin of 3.76% in F1. Our codebase will be made available upon acceptance.
ACID: Abstractive, Content-Based IDs for Document Retrieval with Language Models
Nov 14, 2023



Generative retrieval (Wang et al., 2022; Tay et al., 2022) is a new approach for end-to-end document retrieval that directly generates document identifiers given an input query. Techniques for designing effective, high-quality document IDs remain largely unexplored. We introduce ACID, in which each document's ID is composed of abstractive keyphrases generated by a large language model, rather than an integer ID sequence as done in past work. We compare our method with the current state-of-the-art technique for ID generation, which produces IDs through hierarchical clustering of document embeddings. We also examine simpler methods to generate natural-language document IDs, including the naive approach of using the first k words of each document as its ID or words with high BM25 scores in that document. We show that using ACID improves top-10 and top-20 accuracy by 15.6% and 14.4% (relative) respectively versus the state-of-the-art baseline on the MSMARCO 100k retrieval task, and 4.4% and 4.0% respectively on the Natural Questions 100k retrieval task. Our results demonstrate the effectiveness of human-readable, natural-language IDs in generative retrieval with LMs. The code for reproducing our results and the keyword-augmented datasets will be released on formal publication.
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
Jan 11, 2023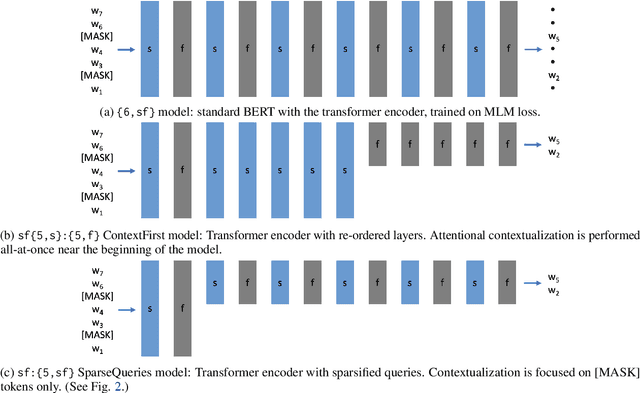

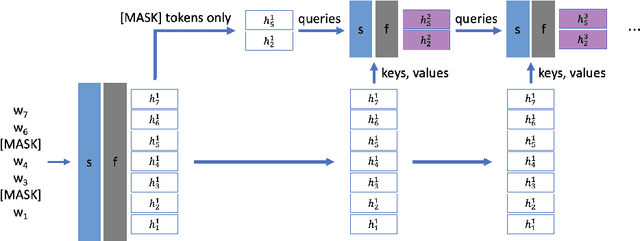
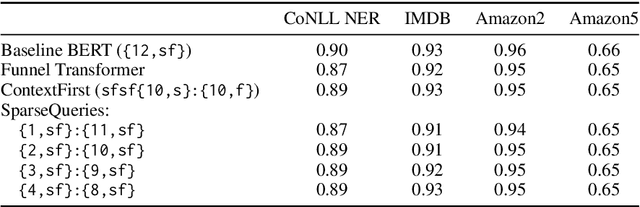
Large-scale language model pretraining is a very successful form of self-supervised learning in natural language processing, but it is increasingly expensive to perform as the models and pretraining corpora have become larger over time. We propose NarrowBERT, a modified transformer encoder that increases the throughput for masked language model pretraining by more than $2\times$. NarrowBERT sparsifies the transformer model such that the self-attention queries and feedforward layers only operate on the masked tokens of each sentence during pretraining, rather than all of the tokens as with the usual transformer encoder. We also show that NarrowBERT increases the throughput at inference time by as much as $3.5\times$ with minimal (or no) performance degradation on sentence encoding tasks like MNLI. Finally, we examine the performance of NarrowBERT on the IMDB and Amazon reviews classification and CoNLL NER tasks and show that it is also comparable to standard BERT performance.
Evaluating and Mitigating Static Bias of Action Representations in the Background and the Foreground
Nov 23, 2022



Deep neural networks for video action recognition easily learn to utilize shortcut static features, such as background and objects instead of motion features. This results in poor generalization to atypical videos such as soccer playing on concrete surfaces (instead of soccer fields). However, due to the rarity of out-of-distribution (OOD) data, quantitative evaluation of static bias remains a difficult task. In this paper, we synthesize new sets of benchmarks to evaluate static bias of action representations, including SCUB for static cues in the background, and SCUF for static cues in the foreground. Further, we propose a simple yet effective video data augmentation technique, StillMix, that automatically identifies bias-inducing video frames; unlike similar augmentation techniques, StillMix does not need to enumerate or precisely segment biased content. With extensive experiments, we quantitatively compare and analyze existing action recognition models on the created benchmarks to reveal their characteristics. We validate the effectiveness of StillMix and show that it improves TSM (Lin, Gan, and Han 2021) and Video Swin Transformer (Liu et al. 2021) by more than 10% of accuracy on SCUB for OOD action recognition.
Adaptive Interaction Modeling via Graph Operations Search
May 05, 2020
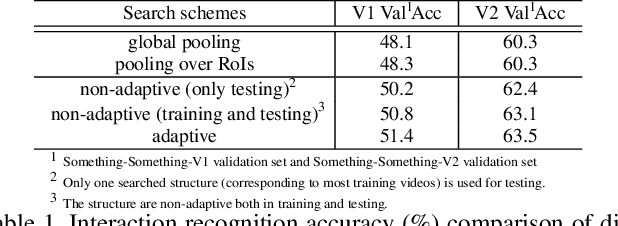


Interaction modeling is important for video action analysis. Recently, several works design specific structures to model interactions in videos. However, their structures are manually designed and non-adaptive, which require structures design efforts and more importantly could not model interactions adaptively. In this paper, we automate the process of structures design to learn adaptive structures for interaction modeling. We propose to search the network structures with differentiable architecture search mechanism, which learns to construct adaptive structures for different videos to facilitate adaptive interaction modeling. To this end, we first design the search space with several basic graph operations that explicitly capture different relations in videos. We experimentally demonstrate that our architecture search framework learns to construct adaptive interaction modeling structures, which provides more understanding about the relations between the structures and some interaction characteristics, and also releases the requirement of structures design efforts. Additionally, we show that the designed basic graph operations in the search space are able to model different interactions in videos. The experiments on two interaction datasets show that our method achieves competitive performance with state-of-the-arts.