 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Expressive Appropriateness of Speech in Rich Contexts
May 10, 2026Evaluating expressive speech remains challenging, as existing methods mainly assess emotional intensity and overlook whether a speech sample is expressively appropriate for its contextual setting. This limitation hinders reliable evaluation of speech systems used in narrative-driven and interactive applications, such as audiobooks and conversational agents. We introduce CEAEval, a Context-rich framework for Evaluating Expressive Appropriateness in speech, which assesses whether a speech sample expressively aligns with the underlying communicative intent implied by its discourse-level narrative context. To support this task, we construct CEAEval-D, the first context-rich speech dataset with real human performances in Mandarin conversational speech, providing narrative descriptions together with fifteen dimensions of human annotations covering expressive attributes and expressive appropriateness. We further develop CEAEval-M, a model that integrates knowledge distillation, planner-based multi-model collaboration, adaptive audio attention bias, and reinforcement learning to perform context-rich expressive appropriateness evaluation. Experiments on a human-annotated test set demonstrate that CEAEval-M substantially outperforms existing speech evaluation and analysis systems.
Addressing Missing and Noisy Modalities in One Solution: Unified Modality-Quality Framework for Low-quality Multimodal Data
Mar 03, 2026Multimodal data encountered in real-world scenarios are typically of low quality, with noisy modalities and missing modalities being typical forms that severely hinder model performance and robustness. However, prior works often handle noisy and missing modalities separately. In contrast, we jointly address missing and noisy modalities to enhance model robustness in low-quality data scenarios. We regard both noisy and missing modalities as a unified low-quality modality problem, and propose a unified modality-quality (UMQ) framework to enhance low-quality representations for multimodal affective computing. Firstly, we train a quality estimator with explicit supervised signals via a rank-guided training strategy that compares the relative quality of different representations by adding a ranking constraint, avoiding training noise caused by inaccurate absolute quality labels. Then, a quality enhancer for each modality is constructed, which uses the sample-specific information provided by other modalities and the modality-specific information provided by the defined modality baseline representation to enhance the quality of unimodal representations. Finally, we propose a quality-aware mixture-of-experts module with particular routing mechanism to enable multiple modality-quality problems to be addressed more specifically. UMQ consistently outperforms state-of-the-art baselines on multiple datasets under the settings of complete, missing, and noisy modalities.
CyIN: Cyclic Informative Latent Space for Bridging Complete and Incomplete Multimodal Learning
Feb 04, 2026Multimodal machine learning, mimicking the human brain's ability to integrate various modalities has seen rapid growth. Most previous multimodal models are trained on perfectly paired multimodal input to reach optimal performance. In real-world deployments, however, the presence of modality is highly variable and unpredictable, causing the pre-trained models in suffering significant performance drops and fail to remain robust with dynamic missing modalities circumstances. In this paper, we present a novel Cyclic INformative Learning framework (CyIN) to bridge the gap between complete and incomplete multimodal learning. Specifically, we firstly build an informative latent space by adopting token- and label-level Information Bottleneck (IB) cyclically among various modalities. Capturing task-related features with variational approximation, the informative bottleneck latents are purified for more efficient cross-modal interaction and multimodal fusion. Moreover, to supplement the missing information caused by incomplete multimodal input, we propose cross-modal cyclic translation by reconstruct the missing modalities with the remained ones through forward and reverse propagation process. With the help of the extracted and reconstructed informative latents, CyIN succeeds in jointly optimizing complete and incomplete multimodal learning in one unified model. Extensive experiments on 4 multimodal datasets demonstrate the superior performance of our method in both complete and diverse incomplete scenarios.
MissMAC-Bench: Building Solid Benchmark for Missing Modality Issue in Robust Multimodal Affective Computing
Jan 31, 2026As a knowledge discovery task over heterogeneous data sources, current Multimodal Affective Computing (MAC) heavily rely on the completeness of multiple modalities to accurately understand human's affective state. However, in real-world scenarios, the availability of modality data is often dynamic and uncertain, leading to substantial performance fluctuations due to the distribution shifts and semantic deficiencies of the incomplete multimodal inputs. Known as the missing modality issue, this challenge poses a critical barrier to the robustness and practical deployment of MAC models. To systematically quantify this issue, we introduce MissMAC-Bench, a comprehensive benchmark designed to establish fair and unified evaluation standards from the perspective of cross-modal synergy. Two guiding principles are proposed, including no missing prior during training, and one single model capable of handling both complete and incomplete modality scenarios, thereby ensuring better generalization. Moreover, to bridge the gap between academic research and real-world applications, our benchmark integrates evaluation protocols with both fixed and random missing patterns at the dataset and instance levels. Extensive experiments conducted on 3 widely-used language models across 4 datasets validate the effectiveness of diverse MAC approaches in tackling the missing modality issue. Our benchmark provides a solid foundation for advancing robust multimodal affective computing and promotes the development of multimedia data mining.
GRCF: Two-Stage Groupwise Ranking and Calibration Framework for Multimodal Sentiment Analysis
Jan 14, 2026Most Multimodal Sentiment Analysis research has focused on point-wise regression. While straightforward, this approach is sensitive to label noise and neglects whether one sample is more positive than another, resulting in unstable predictions and poor correlation alignment. Pairwise ordinal learning frameworks emerged to address this gap, capturing relative order by learning from comparisons. Yet, they introduce two new trade-offs: First, they assign uniform importance to all comparisons, failing to adaptively focus on hard-to-rank samples. Second, they employ static ranking margins, which fail to reflect the varying semantic distances between sentiment groups. To address this, we propose a Two-Stage Group-wise Ranking and Calibration Framework (GRCF) that adapts the philosophy of Group Relative Policy Optimization (GRPO). Our framework resolves these trade-offs by simultaneously preserving relative ordinal structure, ensuring absolute score calibration, and adaptively focusing on difficult samples. Specifically, Stage 1 introduces a GRPO-inspired Advantage-Weighted Dynamic Margin Ranking Loss to build a fine-grained ordinal structure. Stage 2 then employs an MAE-driven objective to align prediction magnitudes. To validate its generalizability, we extend GRCF to classification tasks, including multimodal humor detection and sarcasm detection. GRCF achieves state-of-the-art performance on core regression benchmarks, while also showing strong generalizability in classification tasks.
MIDG: Mixture of Invariant Experts with knowledge injection for Domain Generalization in Multimodal Sentiment Analysis
Dec 08, 2025



Existing methods in domain generalization for Multimodal Sentiment Analysis (MSA) often overlook inter-modal synergies during invariant features extraction, which prevents the accurate capture of the rich semantic information within multimodal data. Additionally, while knowledge injection techniques have been explored in MSA, they often suffer from fragmented cross-modal knowledge, overlooking specific representations that exist beyond the confines of unimodal. To address these limitations, we propose a novel MSA framework designed for domain generalization. Firstly, the framework incorporates a Mixture of Invariant Experts model to extract domain-invariant features, thereby enhancing the model's capacity to learn synergistic relationships between modalities. Secondly, we design a Cross-Modal Adapter to augment the semantic richness of multimodal representations through cross-modal knowledge injection. Extensive domain experiments conducted on three datasets demonstrate that the proposed MIDG achieves superior performance.
Disentangling Bias by Modeling Intra- and Inter-modal Causal Attention for Multimodal Sentiment Analysis
Aug 07, 2025
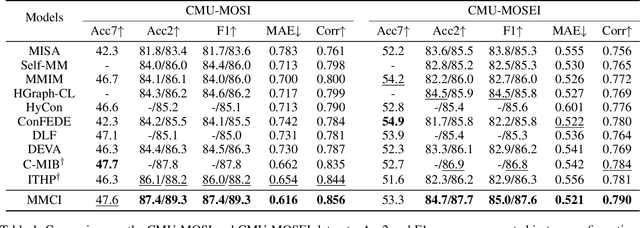
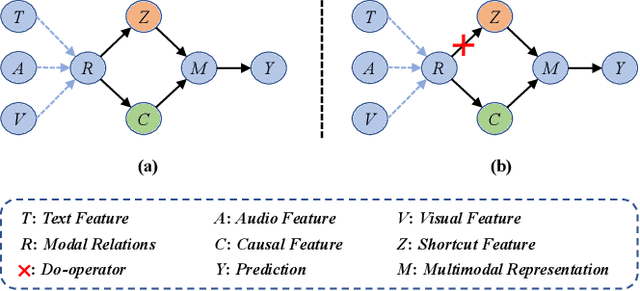
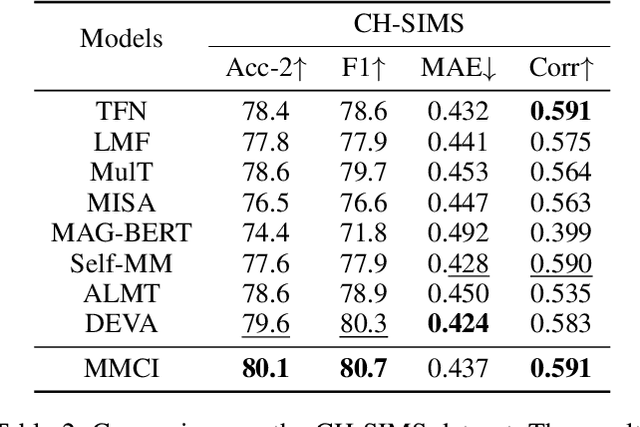
Multimodal sentiment analysis (MSA) aims to understand human emotions by integrating information from multiple modalities, such as text, audio, and visual data. However, existing methods often suffer from spurious correlations both within and across modalities, leading models to rely on statistical shortcuts rather than true causal relationships, thereby undermining generalization. To mitigate this issue, we propose a Multi-relational Multimodal Causal Intervention (MMCI) model, which leverages the backdoor adjustment from causal theory to address the confounding effects of such shortcuts. Specifically, we first model the multimodal inputs as a multi-relational graph to explicitly capture intra- and inter-modal dependencies. Then, we apply an attention mechanism to separately estimate and disentangle the causal features and shortcut features corresponding to these intra- and inter-modal relations. Finally, by applying the backdoor adjustment, we stratify the shortcut features and dynamically combine them with the causal features to encourage MMCI to produce stable predictions under distribution shifts. Extensive experiments on several standard MSA datasets and out-of-distribution (OOD) test sets demonstrate that our method effectively suppresses biases and improves performance.
Extended Cross-Modality United Learning for Unsupervised Visible-Infrared Person Re-identification
Dec 26, 2024Unsupervised learning visible-infrared person re-identification (USL-VI-ReID) aims to learn modality-invariant features from unlabeled cross-modality datasets and reduce the inter-modality gap. However, the existing methods lack cross-modality clustering or excessively pursue cluster-level association, which makes it difficult to perform reliable modality-invariant features learning. To deal with this issue, we propose a Extended Cross-Modality United Learning (ECUL) framework, incorporating Extended Modality-Camera Clustering (EMCC) and Two-Step Memory Updating Strategy (TSMem) modules. Specifically, we design ECUL to naturally integrates intra-modality clustering, inter-modality clustering and inter-modality instance selection, establishing compact and accurate cross-modality associations while reducing the introduction of noisy labels. Moreover, EMCC captures and filters the neighborhood relationships by extending the encoding vector, which further promotes the learning of modality-invariant and camera-invariant knowledge in terms of clustering algorithm. Finally, TSMem provides accurate and generalized proxy points for contrastive learning by updating the memory in stages. Extensive experiments results on SYSU-MM01 and RegDB datasets demonstrate that the proposed ECUL shows promising performance and even outperforms certain supervised methods.
Dynamic Modality-Camera Invariant Clustering for Unsupervised Visible-Infrared Person Re-identification
Dec 11, 2024Unsupervised learning visible-infrared person re-identification (USL-VI-ReID) offers a more flexible and cost-effective alternative compared to supervised methods. This field has gained increasing attention due to its promising potential. Existing methods simply cluster modality-specific samples and employ strong association techniques to achieve instance-to-cluster or cluster-to-cluster cross-modality associations. However, they ignore cross-camera differences, leading to noticeable issues with excessive splitting of identities. Consequently, this undermines the accuracy and reliability of cross-modal associations. To address these issues, we propose a novel Dynamic Modality-Camera Invariant Clustering (DMIC) framework for USL-VI-ReID. Specifically, our DMIC naturally integrates Modality-Camera Invariant Expansion (MIE), Dynamic Neighborhood Clustering (DNC) and Hybrid Modality Contrastive Learning (HMCL) into a unified framework, which eliminates both the cross-modality and cross-camera discrepancies in clustering. MIE fuses inter-modal and inter-camera distance coding to bridge the gaps between modalities and cameras at the clustering level. DNC employs two dynamic search strategies to refine the network's optimization objective, transitioning from improving discriminability to enhancing cross-modal and cross-camera generalizability. Moreover, HMCL is designed to optimize instance-level and cluster-level distributions. Memories for intra-modality and inter-modality training are updated using randomly selected samples, facilitating real-time exploration of modality-invariant representations. Extensive experiments have demonstrated that our DMIC addresses the limitations present in current clustering approaches and achieve competitive performance, which significantly reduces the performance gap with supervised methods.
Meta-Learn Unimodal Signals with Weak Supervision for Multimodal Sentiment Analysis
Aug 28, 2024
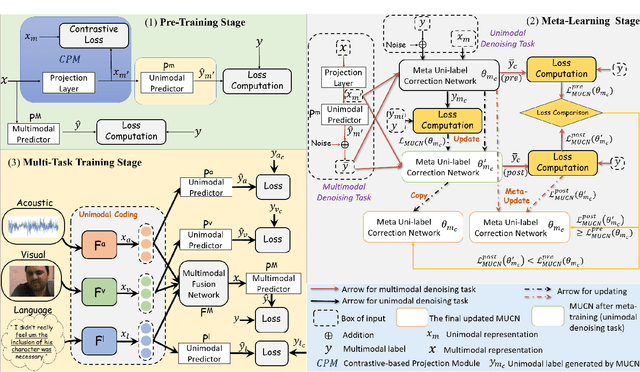
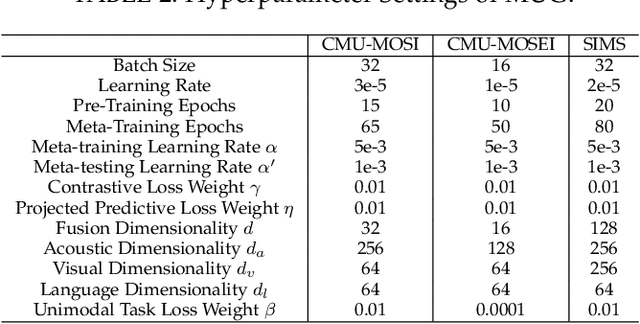
Multimodal sentiment analysis aims to effectively integrate information from various sources to infer sentiment, where in many cases there are no annotations for unimodal labels. Therefore, most works rely on multimodal labels for training. However, there exists the noisy label problem for the learning of unimodal signals as multimodal annotations are not always the ideal substitutes for the unimodal ones, failing to achieve finer optimization for individual modalities. In this paper, we explore the learning of unimodal labels under the weak supervision from the annotated multimodal labels. Specifically, we propose a novel meta uni-label generation (MUG) framework to address the above problem, which leverages the available multimodal labels to learn the corresponding unimodal labels by the meta uni-label correction network (MUCN). We first design a contrastive-based projection module to bridge the gap between unimodal and multimodal representations, so as to use multimodal annotations to guide the learning of MUCN. Afterwards, we propose unimodal and multimodal denoising tasks to train MUCN with explicit supervision via a bi-level optimization strategy. We then jointly train unimodal and multimodal learning tasks to extract discriminative unimodal features for multimodal inference. Experimental results suggest that MUG outperforms competitive baselines and can learn accurate unimodal labels.