 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemtslearn: Machine Learning in Python for Medical Time Series
Mar 31, 2026Medical time-series data captures the dynamic progression of patient conditions, playing a vital role in modern clinical decision support systems. However, real-world clinical data is highly heterogeneous and inconsistently formatted. Furthermore, existing machine learning tools often have steep learning curves and fragmented workflows. Consequently, a significant gap remains between cutting-edge AI technologies and clinical application. To address this, we introduce mtslearn, an end-to-end integrated toolkit specifically designed for medical time-series data. First, the framework provides a unified data interface that automates the parsing and alignment of wide, long, and flat data formats. This design significantly reduces data cleaning overhead. Building on this, mtslearn provides a complete pipeline from data reading and feature engineering to model training and result visualization. Furthermore, it offers flexible interfaces for custom algorithms. Through a modular design, mtslearn simplifies complex data engineering tasks into a few lines of code. This significantly lowers the barrier to entry for clinicians with limited programming experience, empowering them to focus more on exploring medical hypotheses and accelerating the translation of advanced algorithms into real-world clinical practice. mtslearn is publicly available at https://github.com/PKUDigitalHealth/mtslearn.
WebTestBench: Evaluating Computer-Use Agents towards End-to-End Automated Web Testing
Mar 26, 2026The emergence of Large Language Models (LLMs) has catalyzed a paradigm shift in programming, giving rise to "vibe coding", where users can build complete projects and even control computers using natural language instructions. This paradigm has driven automated webpage development, but it introduces a new requirement about how to automatically verify whether the web functionalities are reliably implemented. Existing works struggle to adapt, relying on static visual similarity or predefined checklists that constrain their utility in open-ended environments. Furthermore, they overlook a vital aspect of software quality, namely latent logical constraints. To address these gaps, we introduce WebTestBench, a benchmark for evaluating end-to-end automated web testing. WebTestBench encompasses comprehensive dimensions across diverse web application categories. We decompose the testing process into two cascaded sub-tasks, checklist generation and defect detection, and propose WebTester, a baseline framework for this task. Evaluating popular LLMs with WebTester reveals severe challenges, including insufficient test completeness, detection bottlenecks, and long-horizon interaction unreliability. These findings expose a substantial gap between current computer-use agent capabilities and industrial-grade deployment demands. We hope that WebTestBench provides valuable insights and guidance for advancing end-to-end automated web testing. Our dataset and code are available at https://github.com/friedrichor/WebTestBench.
Structurally Aligned Subtask-Level Memory for Software Engineering Agents
Feb 25, 2026Large Language Models (LLMs) have demonstrated significant potential as autonomous software engineering (SWE) agents. Recent work has further explored augmenting these agents with memory mechanisms to support long-horizon reasoning. However, these approaches typically operate at a coarse instance granularity, treating the entire problem-solving episode as the atomic unit of storage and retrieval. We empirically demonstrate that instance-level memory suffers from a fundamental granularity mismatch, resulting in misguided retrieval when tasks with similar surface descriptions require distinct reasoning logic at specific stages. To address this, we propose Structurally Aligned Subtask-Level Memory, a method that aligns memory storage, retrieval, and updating with the agent's functional decomposition. Extensive experiments on SWE-bench Verified demonstrate that our method consistently outperforms both vanilla agents and strong instance-level memory baselines across diverse backbones, improving mean Pass@1 over the vanilla agent by +4.7 pp on average (e.g., +6.8 pp on Gemini 2.5 Pro). Performance gains grow with more interaction steps, showing that leveraging past experience benefits long-horizon reasoning in complex software engineering tasks.
SOUP: Token-level Single-sample Mix-policy Reinforcement Learning for Large Language Models
Jan 29, 2026On-policy reinforcement learning (RL) methods widely used for language model post-training, like Group Relative Policy Optimization (GRPO), often suffer from limited exploration and early saturation due to low sampling diversity. While off-policy data can help, current approaches that mix entire trajectories cause significant policy mismatch and instability. In this work, we propose the $\textbf{S}$ingle-sample Mix-p$\textbf{O}$licy $\textbf{U}$nified $\textbf{P}$aradigm (SOUP), a framework that unifies off- and on-policy learning within individual samples at the token level. It confines off-policy influence to the prefix of a generated sequence sampled from historical policies, while the continuation is generated on-policy. Through token-level importance ratios, SOUP effectively leverages off-policy information while preserving training stability. Extensive experiments demonstrate that SOUP consistently outperforms standard on-policy training and existing off-policy extensions. Our further analysis clarifies how our fine-grained, single-sample mix-policy training can improve both exploration and final performance in LLM RL.
Klear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025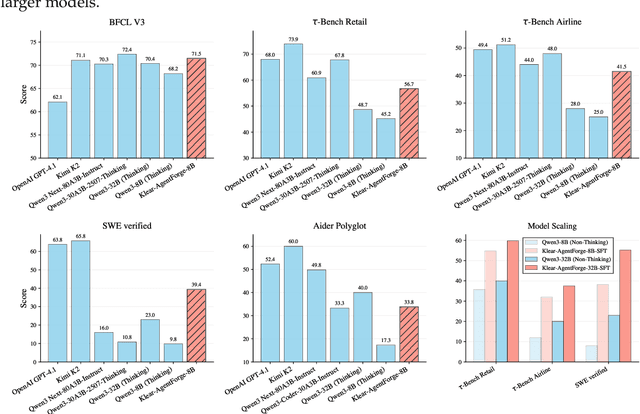
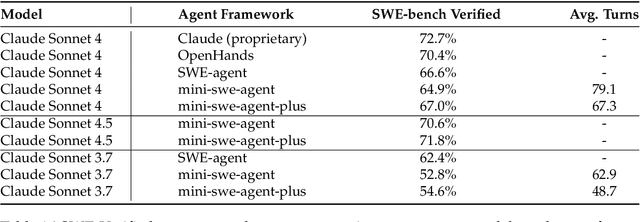
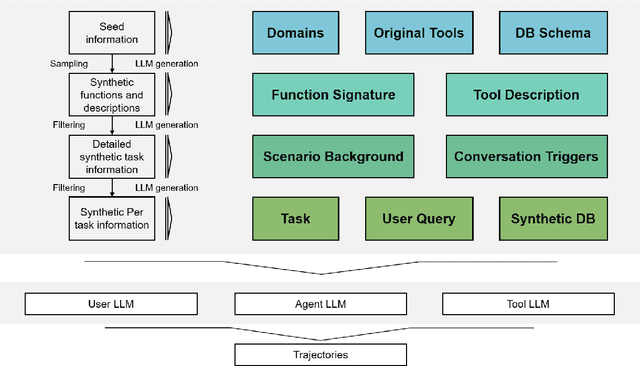
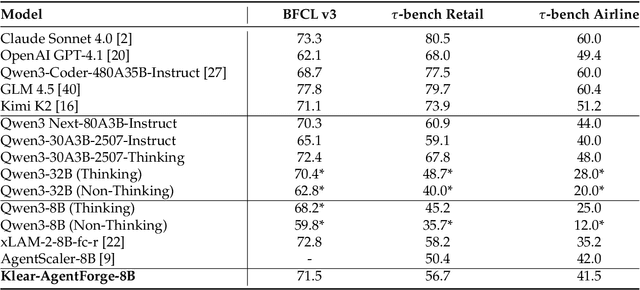
Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
SWIFT: A General Sensitive Weight Identification Framework for Fast Sensor-Transfer Pansharpening
Jul 27, 2025Pansharpening aims to fuse high-resolution panchromatic (PAN) images with low-resolution multispectral (LRMS) images to generate high-resolution multispectral (HRMS) images. Although deep learning-based methods have achieved promising performance, they generally suffer from severe performance degradation when applied to data from unseen sensors. Adapting these models through full-scale retraining or designing more complex architectures is often prohibitively expensive and impractical for real-world deployment. To address this critical challenge, we propose a fast and general-purpose framework for cross-sensor adaptation, SWIFT (Sensitive Weight Identification for Fast Transfer). Specifically, SWIFT employs an unsupervised sampling strategy based on data manifold structures to balance sample selection while mitigating the bias of traditional Farthest Point Sampling, efficiently selecting only 3\% of the most informative samples from the target domain. This subset is then used to probe a source-domain pre-trained model by analyzing the gradient behavior of its parameters, allowing for the quick identification and subsequent update of only the weight subset most sensitive to the domain shift. As a plug-and-play framework, SWIFT can be applied to various existing pansharpening models. Extensive experiments demonstrate that SWIFT reduces the adaptation time from hours to approximately one minute on a single NVIDIA RTX 4090 GPU. The adapted models not only substantially outperform direct-transfer baselines but also achieve performance competitive with, and in some cases superior to, full retraining, establishing a new state-of-the-art on cross-sensor pansharpening tasks for the WorldView-2 and QuickBird datasets.
Evaluating Multimodal Large Language Models on Video Captioning via Monte Carlo Tree Search
Jun 11, 2025Video captioning can be used to assess the video understanding capabilities of Multimodal Large Language Models (MLLMs). However, existing benchmarks and evaluation protocols suffer from crucial issues, such as inadequate or homogeneous creation of key points, exorbitant cost of data creation, and limited evaluation scopes. To address these issues, we propose an automatic framework, named AutoCaption, which leverages Monte Carlo Tree Search (MCTS) to construct numerous and diverse descriptive sentences (\textit{i.e.}, key points) that thoroughly represent video content in an iterative way. This iterative captioning strategy enables the continuous enhancement of video details such as actions, objects' attributes, environment details, etc. We apply AutoCaption to curate MCTS-VCB, a fine-grained video caption benchmark covering video details, thereby enabling a comprehensive evaluation of MLLMs on the video captioning task. We evaluate more than 20 open- and closed-source MLLMs of varying sizes on MCTS-VCB. Results show that MCTS-VCB can effectively and comprehensively evaluate the video captioning capability, with Gemini-1.5-Pro achieving the highest F1 score of 71.2. Interestingly, we fine-tune InternVL2.5-8B with the AutoCaption-generated data, which helps the model achieve an overall improvement of 25.0% on MCTS-VCB and 16.3% on DREAM-1K, further demonstrating the effectiveness of AutoCaption. The code and data are available at https://github.com/tjunlp-lab/MCTS-VCB.
FF-PNet: A Pyramid Network Based on Feature and Field for Brain Image Registration
May 08, 2025



In recent years, deformable medical image registration techniques have made significant progress. However, existing models still lack efficiency in parallel extraction of coarse and fine-grained features. To address this, we construct a new pyramid registration network based on feature and deformation field (FF-PNet). For coarse-grained feature extraction, we design a Residual Feature Fusion Module (RFFM), for fine-grained image deformation, we propose a Residual Deformation Field Fusion Module (RDFFM). Through the parallel operation of these two modules, the model can effectively handle complex image deformations. It is worth emphasizing that the encoding stage of FF-PNet only employs traditional convolutional neural networks without any attention mechanisms or multilayer perceptrons, yet it still achieves remarkable improvements in registration accuracy, fully demonstrating the superior feature decoding capabilities of RFFM and RDFFM. We conducted extensive experiments on the LPBA and OASIS datasets. The results show our network consistently outperforms popular methods in metrics like the Dice Similarity Coefficient.
Routing to the Right Expertise: A Trustworthy Judge for Instruction-based Image Editing
Apr 10, 2025



Instruction-based Image Editing (IIE) models have made significantly improvement due to the progress of multimodal large language models (MLLMs) and diffusion models, which can understand and reason about complex editing instructions. In addition to advancing current IIE models, accurately evaluating their output has become increasingly critical and challenging. Current IIE evaluation methods and their evaluation procedures often fall short of aligning with human judgment and often lack explainability. To address these limitations, we propose JUdgement through Routing of Expertise (JURE). Each expert in JURE is a pre-selected model assumed to be equipped with an atomic expertise that can provide useful feedback to judge output, and the router dynamically routes the evaluation task of a given instruction and its output to appropriate experts, aggregating their feedback into a final judge. JURE is trustworthy in two aspects. First, it can effortlessly provide explanations about its judge by examining the routed experts and their feedback. Second, experimental results demonstrate that JURE is reliable by achieving superior alignment with human judgments, setting a new standard for automated IIE evaluation. Moreover, JURE's flexible design is future-proof - modular experts can be seamlessly replaced or expanded to accommodate advancements in IIE, maintaining consistently high evaluation quality. Our evaluation data and results are available at https://github.com/Cyyyyyrus/JURE.git.
From Hospital to Portables: A Universal ECG Foundation Model Built on 10+ Million Diverse Recordings
Oct 05, 2024Artificial Intelligence (AI) has shown great promise in electrocardiogram (ECG) analysis and cardiovascular disease detection. However, developing a general AI-ECG model has been challenging due to inter-individual variability and the diversity of ECG diagnoses, limiting existing models to specific diagnostic tasks and datasets. Moreover, current AI-ECG models struggle to achieve comparable performance between single-lead and 12-lead ECGs, limiting the application of AI-ECG to portable and wearable ECG devices. To address these limitations, we introduce an ECG Foundation Model (ECGFounder), a general-purpose model that leverages real-world ECG annotations from cardiology experts to broaden the diagnostic capabilities of ECG analysis. ECGFounder is trained on over 10 million ECGs with 150 label categories from the Harvard-Emory ECG Database, enabling comprehensive cardiovascular disease diagnosis through ECG analysis. The model is designed to be both effective out-of-the-box and fine-tunable for downstream tasks, maximizing usability. More importantly, we extend its application to single-lead ECGs, enabling complex condition diagnoses and supporting various downstream tasks in mobile and remote monitoring scenarios. Experimental results demonstrate that ECGFounder achieves expert-level performance on internal validation sets for both 12-lead and single-lead ECGs, while also exhibiting strong classification performance and generalization across various diagnoses on external validation sets. When fine-tuned, ECGFounder outperforms baseline models in demographics detection, clinical event detection, and cross-modality cardiac rhythm diagnosis. The trained model and data will be publicly released upon publication through the bdsp.io. Our code is available at https://github.com/bdsp-core/ECGFounder.