 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
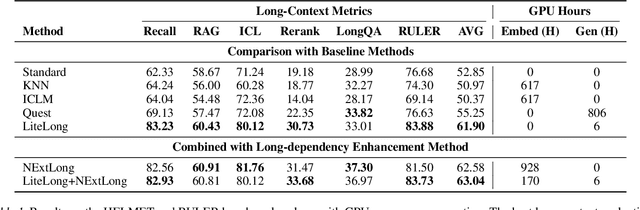


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
Fast Quiet-STaR: Thinking Without Thought Tokens
May 23, 2025Large Language Models (LLMs) have achieved impressive performance across a range of natural language processing tasks. However, recent advances demonstrate that further gains particularly in complex reasoning tasks require more than merely scaling up model sizes or training data. One promising direction is to enable models to think during the reasoning process. Recently, Quiet STaR significantly improves reasoning by generating token-level thought traces, but incurs substantial inference overhead. In this work, we propose Fast Quiet STaR, a more efficient reasoning framework that preserves the benefits of token-level reasoning while reducing computational cost. Our method introduces a curriculum learning based training strategy that gradually reduces the number of thought tokens, enabling the model to internalize more abstract and concise reasoning processes. We further extend this approach to the standard Next Token Prediction (NTP) setting through reinforcement learning-based fine-tuning, resulting in Fast Quiet-STaR NTP, which eliminates the need for explicit thought token generation during inference. Experiments on four benchmark datasets with Mistral 7B and Qwen2.5 7B demonstrate that Fast Quiet-STaR consistently outperforms Quiet-STaR in terms of average accuracy under the same inference time budget. Notably, Fast Quiet-STaR NTP achieves an average accuracy improvement of 9\% on Mistral 7B and 5.7\% on Qwen2.5 7B, while maintaining the same inference latency. Our code will be available at https://github.com/huangwei200012/Fast-Quiet-STaR.
LongMagpie: A Self-synthesis Method for Generating Large-scale Long-context Instructions
May 22, 2025High-quality long-context instruction data is essential for aligning long-context large language models (LLMs). Despite the public release of models like Qwen and Llama, their long-context instruction data remains proprietary. Human annotation is costly and challenging, while template-based synthesis methods limit scale, diversity, and quality. We introduce LongMagpie, a self-synthesis framework that automatically generates large-scale long-context instruction data. Our key insight is that aligned long-context LLMs, when presented with a document followed by special tokens preceding a user turn, auto-regressively generate contextually relevant queries. By harvesting these document-query pairs and the model's responses, LongMagpie produces high-quality instructions without human effort. Experiments on HELMET, RULER, and Longbench v2 demonstrate that LongMagpie achieves leading performance on long-context tasks while maintaining competitive performance on short-context tasks, establishing it as a simple and effective approach for open, diverse, and scalable long-context instruction data synthesis.
LSNet: See Large, Focus Small
Mar 29, 2025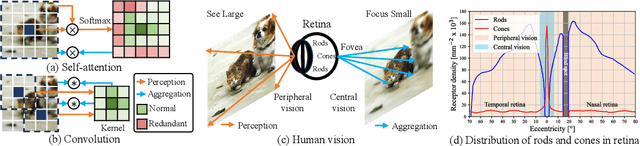
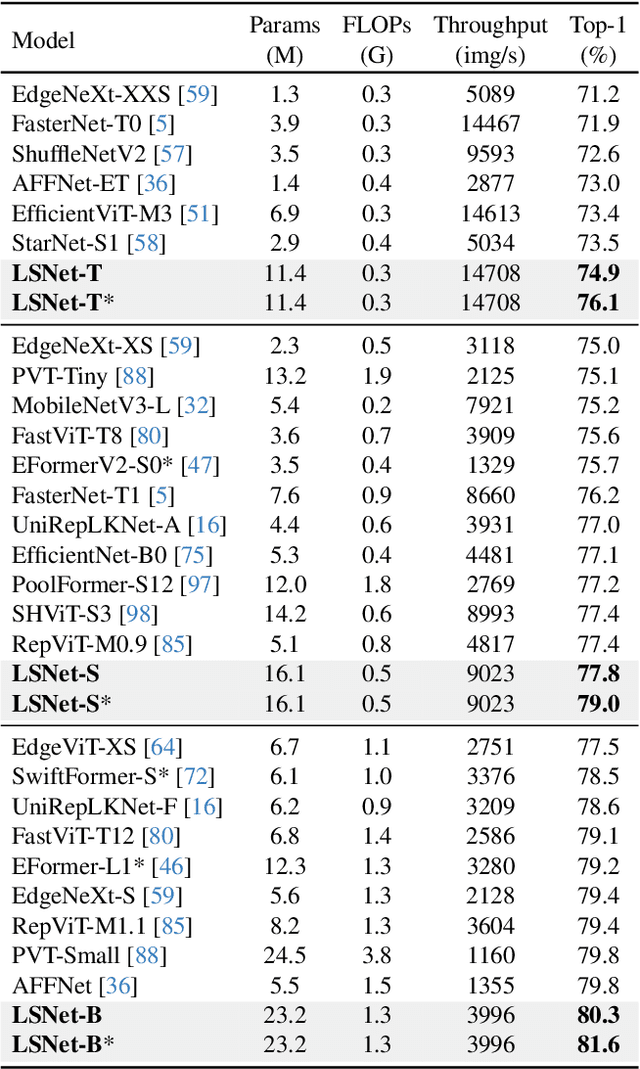
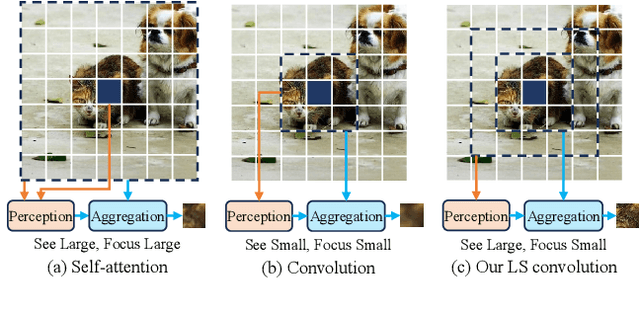
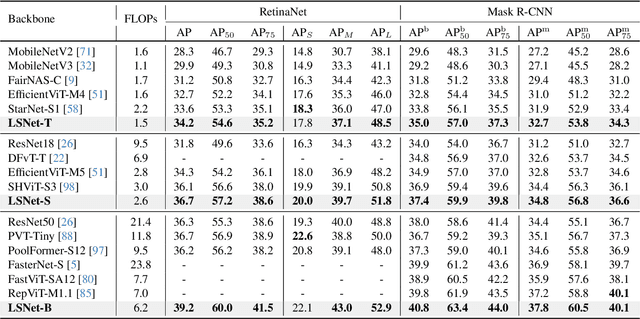
Vision network designs, including Convolutional Neural Networks and Vision Transformers, have significantly advanced the field of computer vision. Yet, their complex computations pose challenges for practical deployments, particularly in real-time applications. To tackle this issue, researchers have explored various lightweight and efficient network designs. However, existing lightweight models predominantly leverage self-attention mechanisms and convolutions for token mixing. This dependence brings limitations in effectiveness and efficiency in the perception and aggregation processes of lightweight networks, hindering the balance between performance and efficiency under limited computational budgets. In this paper, we draw inspiration from the dynamic heteroscale vision ability inherent in the efficient human vision system and propose a ``See Large, Focus Small'' strategy for lightweight vision network design. We introduce LS (\textbf{L}arge-\textbf{S}mall) convolution, which combines large-kernel perception and small-kernel aggregation. It can efficiently capture a wide range of perceptual information and achieve precise feature aggregation for dynamic and complex visual representations, thus enabling proficient processing of visual information. Based on LS convolution, we present LSNet, a new family of lightweight models. Extensive experiments demonstrate that LSNet achieves superior performance and efficiency over existing lightweight networks in various vision tasks. Codes and models are available at https://github.com/jameslahm/lsnet.
YOLOE: Real-Time Seeing Anything
Mar 10, 2025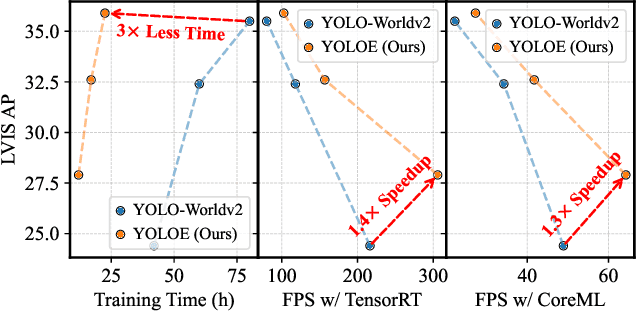
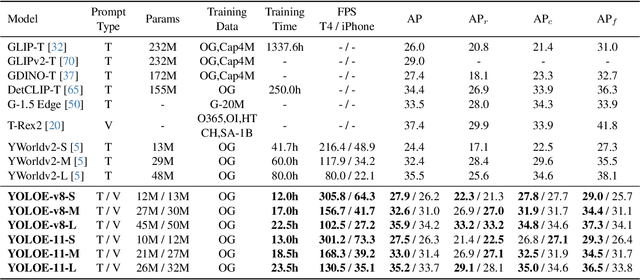
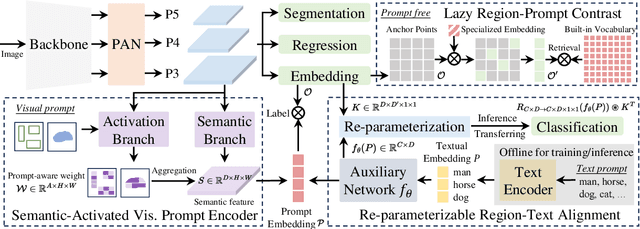
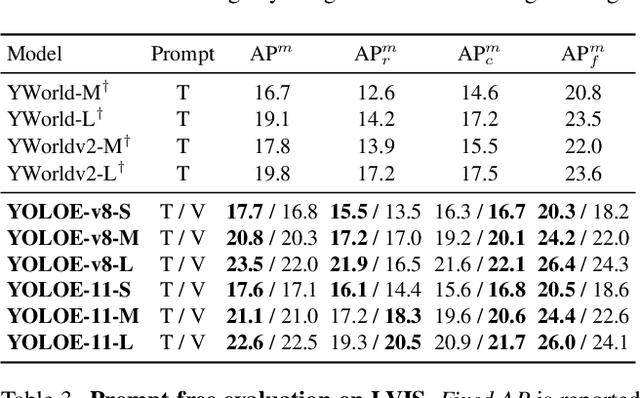
Object detection and segmentation are widely employed in computer vision applications, yet conventional models like YOLO series, while efficient and accurate, are limited by predefined categories, hindering adaptability in open scenarios. Recent open-set methods leverage text prompts, visual cues, or prompt-free paradigm to overcome this, but often compromise between performance and efficiency due to high computational demands or deployment complexity. In this work, we introduce YOLOE, which integrates detection and segmentation across diverse open prompt mechanisms within a single highly efficient model, achieving real-time seeing anything. For text prompts, we propose Re-parameterizable Region-Text Alignment (RepRTA) strategy. It refines pretrained textual embeddings via a re-parameterizable lightweight auxiliary network and enhances visual-textual alignment with zero inference and transferring overhead. For visual prompts, we present Semantic-Activated Visual Prompt Encoder (SAVPE). It employs decoupled semantic and activation branches to bring improved visual embedding and accuracy with minimal complexity. For prompt-free scenario, we introduce Lazy Region-Prompt Contrast (LRPC) strategy. It utilizes a built-in large vocabulary and specialized embedding to identify all objects, avoiding costly language model dependency. Extensive experiments show YOLOE's exceptional zero-shot performance and transferability with high inference efficiency and low training cost. Notably, on LVIS, with 3$\times$ less training cost and 1.4$\times$ inference speedup, YOLOE-v8-S surpasses YOLO-Worldv2-S by 3.5 AP. When transferring to COCO, YOLOE-v8-L achieves 0.6 AP$^b$ and 0.4 AP$^m$ gains over closed-set YOLOv8-L with nearly 4$\times$ less training time. Code and models are available at https://github.com/THU-MIG/yoloe.
Finedeep: Mitigating Sparse Activation in Dense LLMs via Multi-Layer Fine-Grained Experts
Feb 18, 2025



Large language models have demonstrated exceptional performance across a wide range of tasks. However, dense models usually suffer from sparse activation, where many activation values tend towards zero (i.e., being inactivated). We argue that this could restrict the efficient exploration of model representation space. To mitigate this issue, we propose Finedeep, a deep-layered fine-grained expert architecture for dense models. Our framework partitions the feed-forward neural network layers of traditional dense models into small experts, arranges them across multiple sub-layers. A novel routing mechanism is proposed to determine each expert's contribution. We conduct extensive experiments across various model sizes, demonstrating that our approach significantly outperforms traditional dense architectures in terms of perplexity and benchmark performance while maintaining a comparable number of parameters and floating-point operations. Moreover, we find that Finedeep achieves optimal results when balancing depth and width, specifically by adjusting the number of expert sub-layers and the number of experts per sub-layer. Empirical results confirm that Finedeep effectively alleviates sparse activation and efficiently utilizes representation capacity in dense models.
DSMoE: Matrix-Partitioned Experts with Dynamic Routing for Computation-Efficient Dense LLMs
Feb 18, 2025As large language models continue to scale, computational costs and resource consumption have emerged as significant challenges. While existing sparsification methods like pruning reduce computational overhead, they risk losing model knowledge through parameter removal. This paper proposes DSMoE (Dynamic Sparse Mixture-of-Experts), a novel approach that achieves sparsification by partitioning pre-trained FFN layers into computational blocks. We implement adaptive expert routing using sigmoid activation and straight-through estimators, enabling tokens to flexibly access different aspects of model knowledge based on input complexity. Additionally, we introduce a sparsity loss term to balance performance and computational efficiency. Extensive experiments on LLaMA models demonstrate that under equivalent computational constraints, DSMoE achieves superior performance compared to existing pruning and MoE approaches across language modeling and downstream tasks, particularly excelling in generation tasks. Analysis reveals that DSMoE learns distinctive layerwise activation patterns, providing new insights for future MoE architecture design.
Breaking the Stage Barrier: A Novel Single-Stage Approach to Long Context Extension for Large Language Models
Dec 10, 2024Recently, Large language models (LLMs) have revolutionized Natural Language Processing (NLP). Pretrained LLMs, due to limited training context size, struggle with handling long token sequences, limiting their performance on various downstream tasks. Current solutions toward long context modeling often employ multi-stage continual pertaining, which progressively increases the effective context length through several continual pretraining stages. However, those approaches require extensive manual tuning and human expertise. In this paper, we introduce a novel single-stage continual pretraining method, Head-Adaptive Rotary Position Encoding (HARPE), to equip LLMs with long context modeling capabilities while simplifying the training process. Our HARPE leverages different Rotary Position Encoding (RoPE) base frequency values across different attention heads and directly trains LLMs on the target context length. Extensive experiments on 4 language modeling benchmarks, including the latest RULER benchmark, demonstrate that HARPE excels in understanding and integrating long-context tasks with single-stage training, matching and even outperforming existing multi-stage methods. Our results highlight that HARPE successfully breaks the stage barrier for training LLMs with long context modeling capabilities.
[CLS] Token Tells Everything Needed for Training-free Efficient MLLMs
Dec 08, 2024![Figure 1 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F1-Figure1-1.png&w=640&q=75)
![Figure 2 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F6-Table1-1.png&w=640&q=75)
![Figure 3 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F4-Figure2-1.png&w=640&q=75)
![Figure 4 for [CLS] Token Tells Everything Needed for Training-free Efficient MLLMs](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fdef0b0ef768be4c551f56adc209bf441a4105d6e%2F7-Table2-1.png&w=640&q=75)
Multimodal Large Language Models (MLLMs) have recently demonstrated strong performance across a wide range of vision-language tasks, garnering significant attention in the computer vision. However, their efficient deployment remains a substantial challenge due to high computational costs and memory requirements. Recognizing the redundancy of information within the vision modality, recent studies have explored methods for compressing visual tokens in MLLMs to enhance efficiency in a training-free manner. Despite their effectiveness, existing methods like Fast rely on the attention between visual tokens and prompt text tokens as the importance indicator, overlooking the relevance to response text and thus introducing perception bias. In this paper, we demonstrate that in MLLMs, the [CLS] token in the visual encoder inherently knows which visual tokens are important for MLLMs. Building on this prior, we introduce a simple yet effective method for train-free visual token compression, called VTC-CLS. Firstly, it leverages the attention score of the [CLS] token on visual tokens as an importance indicator for pruning visual tokens. Besides, we also explore ensembling the importance scores derived by the [CLS] token from different layers to capture the key visual information more comprehensively. Extensive experiments demonstrate that our VTC-CLS achieves the state-of-the-art performance across various tasks compared with baseline methods. It also brings notably less computational costs in a training-free manner, highlighting its effectiveness and superiority. Code and models are available at \url{https://github.com/THU-MIG/VTC-CLS}.
PrefixKV: Adaptive Prefix KV Cache is What Vision Instruction-Following Models Need for Efficient Generation
Dec 04, 2024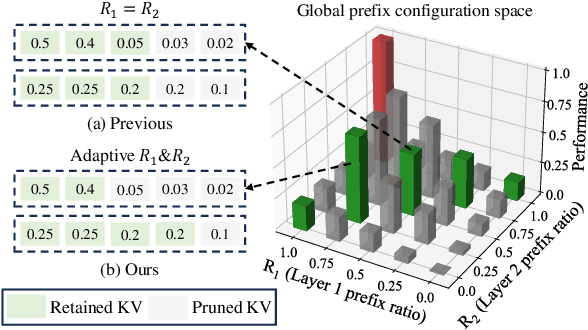

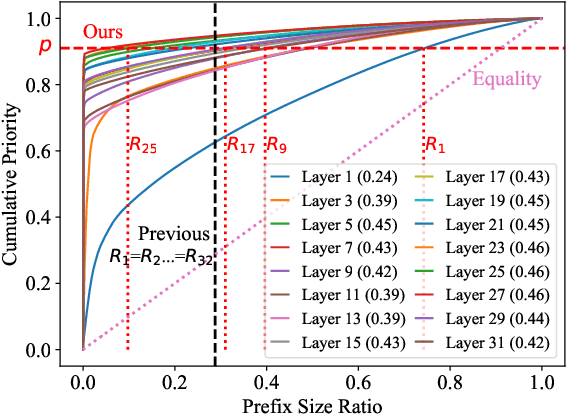

Recently, large vision-language models (LVLMs) have rapidly gained popularity for their strong generation and reasoning capabilities given diverse multimodal inputs. However, these models incur significant computational and memory overhead during inference, which greatly hinders the efficient deployment in practical scenarios. The extensive key-value (KV) cache, necessitated by the lengthy input and output sequences, notably contributes to the high inference cost. Based on this, recent works have investigated ways to reduce the KV cache size for higher efficiency. Although effective, they generally overlook the distinct importance distributions of KV vectors across layers and maintain the same cache size for each layer during the next token prediction. This results in the significant contextual information loss for certain layers, leading to notable performance decline. To address this, we present PrefixKV. It reframes the challenge of determining KV cache sizes for all layers into the task of searching for the optimal global prefix configuration. With an adaptive layer-wise KV retention recipe based on binary search, the maximum contextual information can thus be preserved in each layer, facilitating the generation. Extensive experiments demonstrate that our method achieves the state-of-the-art performance compared with others. It exhibits superior inference efficiency and generation quality trade-offs, showing promising potential for practical applications. Code is available at \url{https://github.com/THU-MIG/PrefixKV}.