 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSMoE: Matrix-Partitioned Experts with Dynamic Routing for Computation-Efficient Dense LLMs
Feb 18, 2025As large language models continue to scale, computational costs and resource consumption have emerged as significant challenges. While existing sparsification methods like pruning reduce computational overhead, they risk losing model knowledge through parameter removal. This paper proposes DSMoE (Dynamic Sparse Mixture-of-Experts), a novel approach that achieves sparsification by partitioning pre-trained FFN layers into computational blocks. We implement adaptive expert routing using sigmoid activation and straight-through estimators, enabling tokens to flexibly access different aspects of model knowledge based on input complexity. Additionally, we introduce a sparsity loss term to balance performance and computational efficiency. Extensive experiments on LLaMA models demonstrate that under equivalent computational constraints, DSMoE achieves superior performance compared to existing pruning and MoE approaches across language modeling and downstream tasks, particularly excelling in generation tasks. Analysis reveals that DSMoE learns distinctive layerwise activation patterns, providing new insights for future MoE architecture design.
Finedeep: Mitigating Sparse Activation in Dense LLMs via Multi-Layer Fine-Grained Experts
Feb 18, 2025



Large language models have demonstrated exceptional performance across a wide range of tasks. However, dense models usually suffer from sparse activation, where many activation values tend towards zero (i.e., being inactivated). We argue that this could restrict the efficient exploration of model representation space. To mitigate this issue, we propose Finedeep, a deep-layered fine-grained expert architecture for dense models. Our framework partitions the feed-forward neural network layers of traditional dense models into small experts, arranges them across multiple sub-layers. A novel routing mechanism is proposed to determine each expert's contribution. We conduct extensive experiments across various model sizes, demonstrating that our approach significantly outperforms traditional dense architectures in terms of perplexity and benchmark performance while maintaining a comparable number of parameters and floating-point operations. Moreover, we find that Finedeep achieves optimal results when balancing depth and width, specifically by adjusting the number of expert sub-layers and the number of experts per sub-layer. Empirical results confirm that Finedeep effectively alleviates sparse activation and efficiently utilizes representation capacity in dense models.
CartesianMoE: Boosting Knowledge Sharing among Experts via Cartesian Product Routing in Mixture-of-Experts
Oct 21, 2024Large language models (LLM) have been attracting much attention from the community recently, due to their remarkable performance in all kinds of downstream tasks. According to the well-known scaling law, scaling up a dense LLM enhances its capabilities, but also significantly increases the computational complexity. Mixture-of-Experts (MoE) models address that by allowing the model size to grow without substantially raising training or inference costs. Yet MoE models face challenges regarding knowledge sharing among experts, making their performance somehow sensitive to routing accuracy. To tackle that, previous works introduced shared experts and combined their outputs with those of the top $K$ routed experts in an ``addition'' manner. In this paper, inspired by collective matrix factorization to learn shared knowledge among data, we propose CartesianMoE, which implements more effective knowledge sharing among experts in more like a ``multiplication'' manner. Extensive experimental results indicate that CartesianMoE outperforms previous MoE models for building LLMs, in terms of both perplexity and downstream task performance. And we also find that CartesianMoE achieves better expert routing robustness.
CT-GAT: Cross-Task Generative Adversarial Attack based on Transferability
Nov 05, 2023
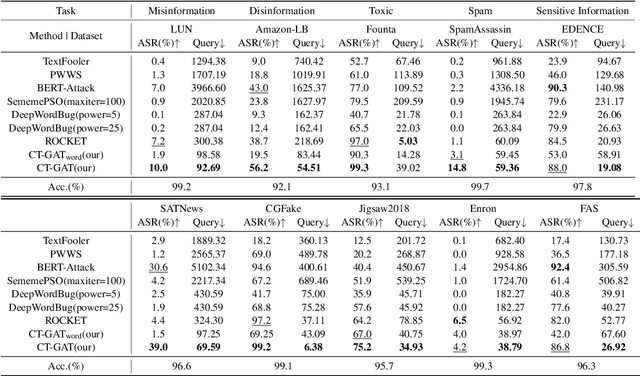
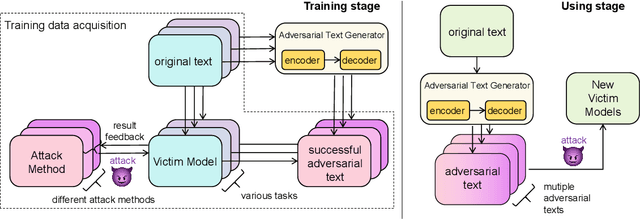

Neural network models are vulnerable to adversarial examples, and adversarial transferability further increases the risk of adversarial attacks. Current methods based on transferability often rely on substitute models, which can be impractical and costly in real-world scenarios due to the unavailability of training data and the victim model's structural details. In this paper, we propose a novel approach that directly constructs adversarial examples by extracting transferable features across various tasks. Our key insight is that adversarial transferability can extend across different tasks. Specifically, we train a sequence-to-sequence generative model named CT-GAT using adversarial sample data collected from multiple tasks to acquire universal adversarial features and generate adversarial examples for different tasks. We conduct experiments on ten distinct datasets, and the results demonstrate that our method achieves superior attack performance with small cost.
MeaeQ: Mount Model Extraction Attacks with Efficient Queries
Oct 21, 2023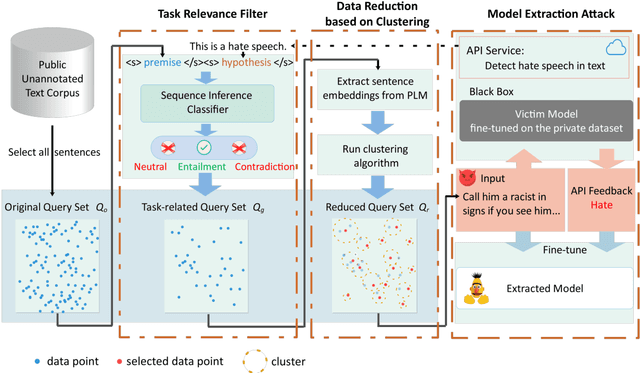
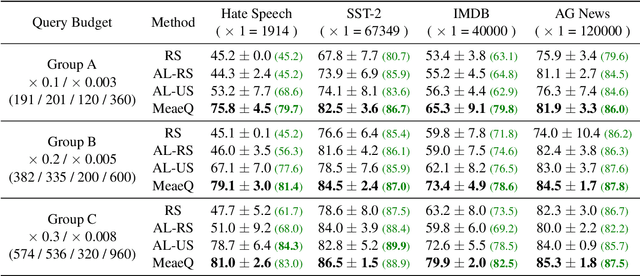
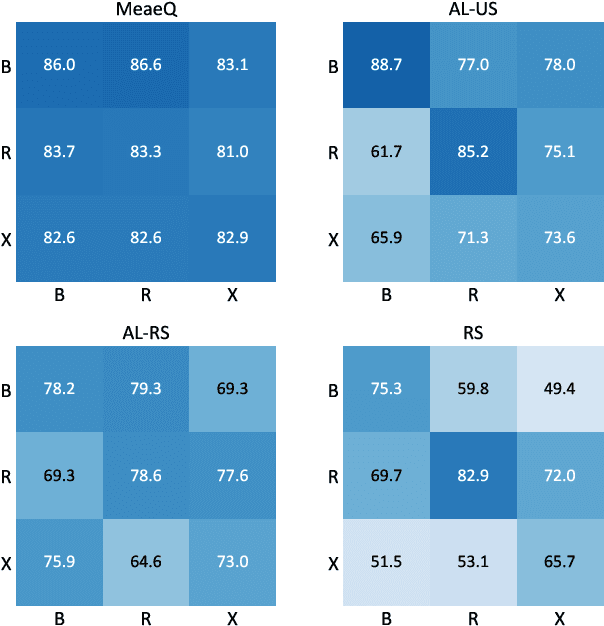

We study model extraction attacks in natural language processing (NLP) where attackers aim to steal victim models by repeatedly querying the open Application Programming Interfaces (APIs). Recent works focus on limited-query budget settings and adopt random sampling or active learning-based sampling strategies on publicly available, unannotated data sources. However, these methods often result in selected queries that lack task relevance and data diversity, leading to limited success in achieving satisfactory results with low query costs. In this paper, we propose MeaeQ (Model extraction attack with efficient Queries), a straightforward yet effective method to address these issues. Specifically, we initially utilize a zero-shot sequence inference classifier, combined with API service information, to filter task-relevant data from a public text corpus instead of a problem domain-specific dataset. Furthermore, we employ a clustering-based data reduction technique to obtain representative data as queries for the attack. Extensive experiments conducted on four benchmark datasets demonstrate that MeaeQ achieves higher functional similarity to the victim model than baselines while requiring fewer queries. Our code is available at https://github.com/C-W-D/MeaeQ.