 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
Aug 12, 2025

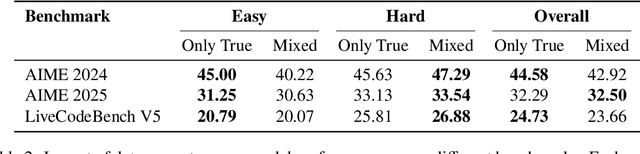

We present Klear-Reasoner, a model with long reasoning capabilities that demonstrates careful deliberation during problem solving, achieving outstanding performance across multiple benchmarks. Although there are already many excellent works related to inference models in the current community, there are still many problems with reproducing high-performance inference models due to incomplete disclosure of training details. This report provides an in-depth analysis of the reasoning model, covering the entire post-training workflow from data preparation and long Chain-of-Thought supervised fine-tuning (long CoT SFT) to reinforcement learning (RL), along with detailed ablation studies for each experimental component. For SFT data, our experiments show that a small number of high-quality data sources are more effective than a large number of diverse data sources, and that difficult samples can achieve better results without accuracy filtering. In addition, we investigate two key issues with current clipping mechanisms in RL: Clipping suppresses critical exploration signals and ignores suboptimal trajectories. To address these challenges, we propose Gradient-Preserving clipping Policy Optimization (GPPO) that gently backpropagates gradients from clipped tokens. GPPO not only enhances the model's exploration capacity but also improves its efficiency in learning from negative samples. Klear-Reasoner exhibits exceptional reasoning abilities in mathematics and programming, scoring 90.5% on AIME 2024, 83.2% on AIME 2025, 66.0% on LiveCodeBench V5 and 58.1% on LiveCodeBench V6.
Finedeep: Mitigating Sparse Activation in Dense LLMs via Multi-Layer Fine-Grained Experts
Feb 18, 2025



Large language models have demonstrated exceptional performance across a wide range of tasks. However, dense models usually suffer from sparse activation, where many activation values tend towards zero (i.e., being inactivated). We argue that this could restrict the efficient exploration of model representation space. To mitigate this issue, we propose Finedeep, a deep-layered fine-grained expert architecture for dense models. Our framework partitions the feed-forward neural network layers of traditional dense models into small experts, arranges them across multiple sub-layers. A novel routing mechanism is proposed to determine each expert's contribution. We conduct extensive experiments across various model sizes, demonstrating that our approach significantly outperforms traditional dense architectures in terms of perplexity and benchmark performance while maintaining a comparable number of parameters and floating-point operations. Moreover, we find that Finedeep achieves optimal results when balancing depth and width, specifically by adjusting the number of expert sub-layers and the number of experts per sub-layer. Empirical results confirm that Finedeep effectively alleviates sparse activation and efficiently utilizes representation capacity in dense models.
DSMoE: Matrix-Partitioned Experts with Dynamic Routing for Computation-Efficient Dense LLMs
Feb 18, 2025As large language models continue to scale, computational costs and resource consumption have emerged as significant challenges. While existing sparsification methods like pruning reduce computational overhead, they risk losing model knowledge through parameter removal. This paper proposes DSMoE (Dynamic Sparse Mixture-of-Experts), a novel approach that achieves sparsification by partitioning pre-trained FFN layers into computational blocks. We implement adaptive expert routing using sigmoid activation and straight-through estimators, enabling tokens to flexibly access different aspects of model knowledge based on input complexity. Additionally, we introduce a sparsity loss term to balance performance and computational efficiency. Extensive experiments on LLaMA models demonstrate that under equivalent computational constraints, DSMoE achieves superior performance compared to existing pruning and MoE approaches across language modeling and downstream tasks, particularly excelling in generation tasks. Analysis reveals that DSMoE learns distinctive layerwise activation patterns, providing new insights for future MoE architecture design.
Multilingual Large Language Models: A Systematic Survey
Nov 19, 2024This paper provides a comprehensive survey of the latest research on multilingual large language models (MLLMs). MLLMs not only are able to understand and generate language across linguistic boundaries, but also represent an important advancement in artificial intelligence. We first discuss the architecture and pre-training objectives of MLLMs, highlighting the key components and methodologies that contribute to their multilingual capabilities. We then discuss the construction of multilingual pre-training and alignment datasets, underscoring the importance of data quality and diversity in enhancing MLLM performance. An important focus of this survey is on the evaluation of MLLMs. We present a detailed taxonomy and roadmap covering the assessment of MLLMs' cross-lingual knowledge, reasoning, alignment with human values, safety, interpretability and specialized applications. Specifically, we extensively discuss multilingual evaluation benchmarks and datasets, and explore the use of LLMs themselves as multilingual evaluators. To enhance MLLMs from black to white boxes, we also address the interpretability of multilingual capabilities, cross-lingual transfer and language bias within these models. Finally, we provide a comprehensive review of real-world applications of MLLMs across diverse domains, including biology, medicine, computer science, mathematics and law. We showcase how these models have driven innovation and improvements in these specialized fields while also highlighting the challenges and opportunities in deploying MLLMs within diverse language communities and application scenarios. We listed the paper related in this survey and publicly available at https://github.com/tjunlp-lab/Awesome-Multilingual-LLMs-Papers.
LANDeRMT: Detecting and Routing Language-Aware Neurons for Selectively Finetuning LLMs to Machine Translation
Sep 29, 2024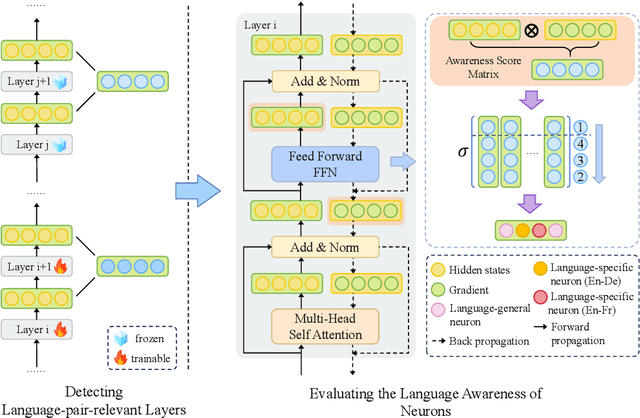
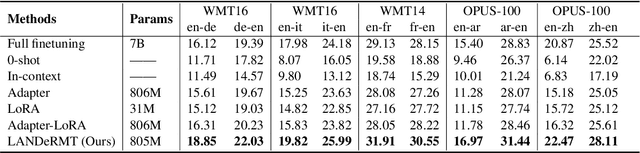
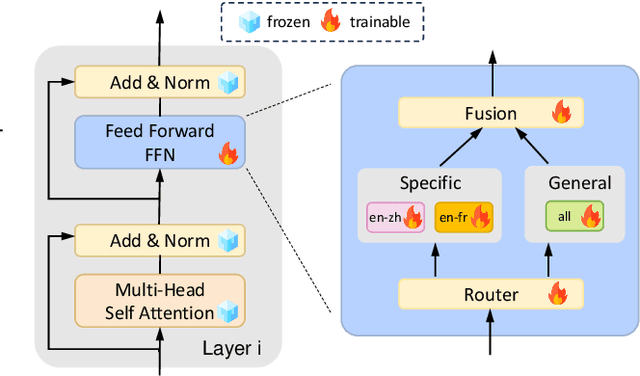
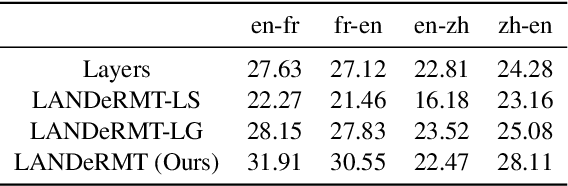
Recent advancements in large language models (LLMs) have shown promising results in multilingual translation even with limited bilingual supervision. The major challenges are catastrophic forgetting and parameter interference for finetuning LLMs when provided parallel training data. To address these challenges, we propose LANDeRMT, a \textbf{L}anguage-\textbf{A}ware \textbf{N}euron \textbf{De}tecting and \textbf{R}outing framework that selectively finetunes LLMs to \textbf{M}achine \textbf{T}ranslation with diverse translation training data. In LANDeRMT, we evaluate the awareness of neurons to MT tasks and categorize them into language-general and language-specific neurons. This categorization enables selective parameter updates during finetuning, mitigating parameter interference and catastrophic forgetting issues. For the detected neurons, we further propose a conditional awareness-based routing mechanism to dynamically adjust language-general and language-specific capacity within LLMs, guided by translation signals. Experimental results demonstrate that the proposed LANDeRMT is very effective in learning translation knowledge, significantly improving translation quality over various strong baselines for multiple language pairs.
FuxiTranyu: A Multilingual Large Language Model Trained with Balanced Data
Aug 13, 2024
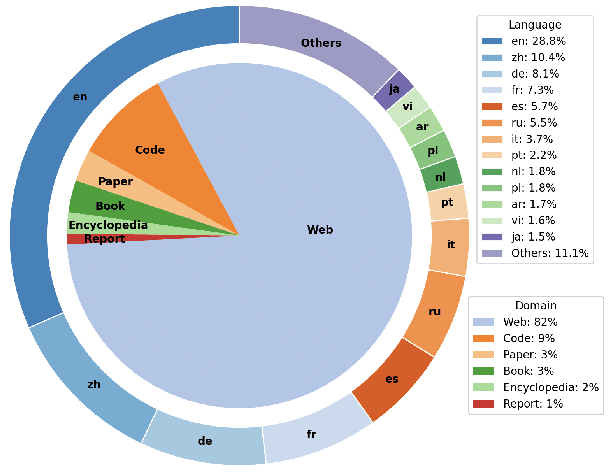
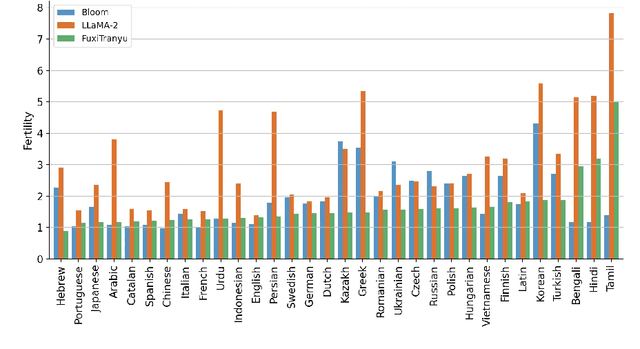
Large language models (LLMs) have demonstrated prowess in a wide range of tasks. However, many LLMs exhibit significant performance discrepancies between high- and low-resource languages. To mitigate this challenge, we present FuxiTranyu, an open-source multilingual LLM, which is designed to satisfy the need of the research community for balanced and high-performing multilingual capabilities. FuxiTranyu-8B, the base model with 8 billion parameters, is trained from scratch on a meticulously balanced multilingual data repository that contains 600 billion tokens covering 43 natural languages and 16 programming languages. In addition to the base model, we also develop two instruction-tuned models: FuxiTranyu-8B-SFT that is fine-tuned on a diverse multilingual instruction dataset, and FuxiTranyu-8B-DPO that is further refined with DPO on a preference dataset for enhanced alignment ability. Extensive experiments on a wide range of multilingual benchmarks demonstrate the competitive performance of FuxiTranyu against existing multilingual LLMs, e.g., BLOOM-7B, PolyLM-13B, Llama-2-Chat-7B and Mistral-7B-Instruct. Interpretability analyses at both the neuron and representation level suggest that FuxiTranyu is able to learn consistent multilingual representations across different languages. To promote further research into multilingual LLMs and their working mechanisms, we release both the base and instruction-tuned FuxiTranyu models together with 58 pretraining checkpoints at HuggingFace and Github.
Is Robustness Transferable across Languages in Multilingual Neural Machine Translation?
Oct 31, 2023Robustness, the ability of models to maintain performance in the face of perturbations, is critical for developing reliable NLP systems. Recent studies have shown promising results in improving the robustness of models through adversarial training and data augmentation. However, in machine translation, most of these studies have focused on bilingual machine translation with a single translation direction. In this paper, we investigate the transferability of robustness across different languages in multilingual neural machine translation. We propose a robustness transfer analysis protocol and conduct a series of experiments. In particular, we use character-, word-, and multi-level noises to attack the specific translation direction of the multilingual neural machine translation model and evaluate the robustness of other translation directions. Our findings demonstrate that the robustness gained in one translation direction can indeed transfer to other translation directions. Additionally, we empirically find scenarios where robustness to character-level noise and word-level noise is more likely to transfer.