 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZigZagkv: Dynamic KV Cache Compression for Long-context Modeling based on Layer Uncertainty
Dec 12, 2024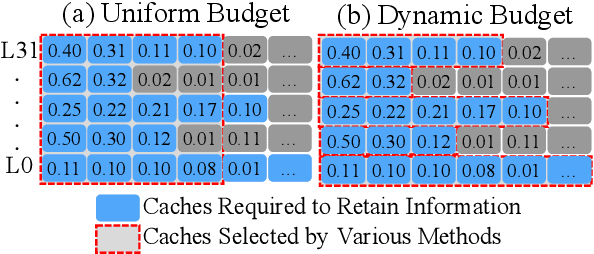



Large Language models (LLMs) have become a research hotspot. To accelerate the inference of LLMs, storing computed caches in memory has become the standard technique. However, as the inference length increases, growing KV caches might lead to out-of-memory issues. Many existing methods address this issue through KV cache compression, primarily by preserving key tokens throughout all layers to reduce information loss. Most of them allocate a uniform budget size for each layer to retain. However, we observe that the minimum budget sizes needed to retain essential information vary across layers and models based on the perspectives of attention and hidden state output. Building on this observation, this paper proposes a simple yet effective KV cache compression method that leverages layer uncertainty to allocate budget size for each layer. Experimental results show that the proposed method can reduce memory usage of the KV caches to only $\sim$20\% when compared to Full KV inference while achieving nearly lossless performance.
FuxiTranyu: A Multilingual Large Language Model Trained with Balanced Data
Aug 13, 2024
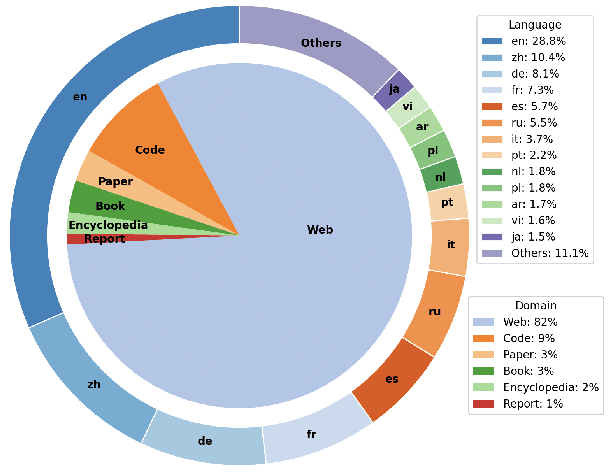
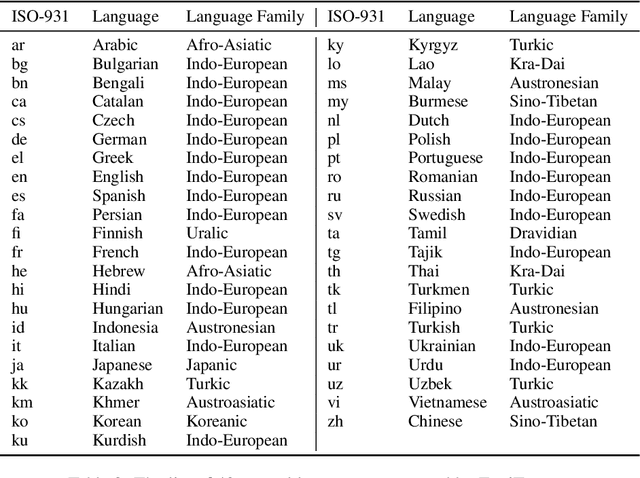
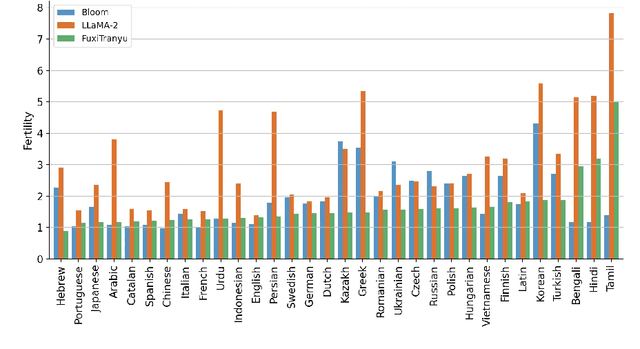
Large language models (LLMs) have demonstrated prowess in a wide range of tasks. However, many LLMs exhibit significant performance discrepancies between high- and low-resource languages. To mitigate this challenge, we present FuxiTranyu, an open-source multilingual LLM, which is designed to satisfy the need of the research community for balanced and high-performing multilingual capabilities. FuxiTranyu-8B, the base model with 8 billion parameters, is trained from scratch on a meticulously balanced multilingual data repository that contains 600 billion tokens covering 43 natural languages and 16 programming languages. In addition to the base model, we also develop two instruction-tuned models: FuxiTranyu-8B-SFT that is fine-tuned on a diverse multilingual instruction dataset, and FuxiTranyu-8B-DPO that is further refined with DPO on a preference dataset for enhanced alignment ability. Extensive experiments on a wide range of multilingual benchmarks demonstrate the competitive performance of FuxiTranyu against existing multilingual LLMs, e.g., BLOOM-7B, PolyLM-13B, Llama-2-Chat-7B and Mistral-7B-Instruct. Interpretability analyses at both the neuron and representation level suggest that FuxiTranyu is able to learn consistent multilingual representations across different languages. To promote further research into multilingual LLMs and their working mechanisms, we release both the base and instruction-tuned FuxiTranyu models together with 58 pretraining checkpoints at HuggingFace and Github.
Understanding the RoPE Extensions of Long-Context LLMs: An Attention Perspective
Jun 19, 2024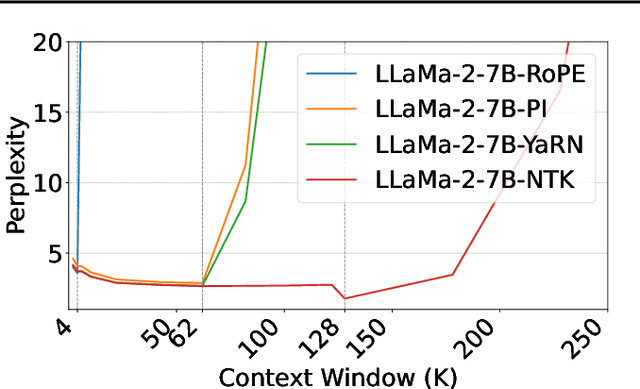
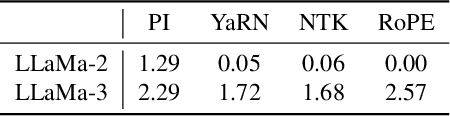

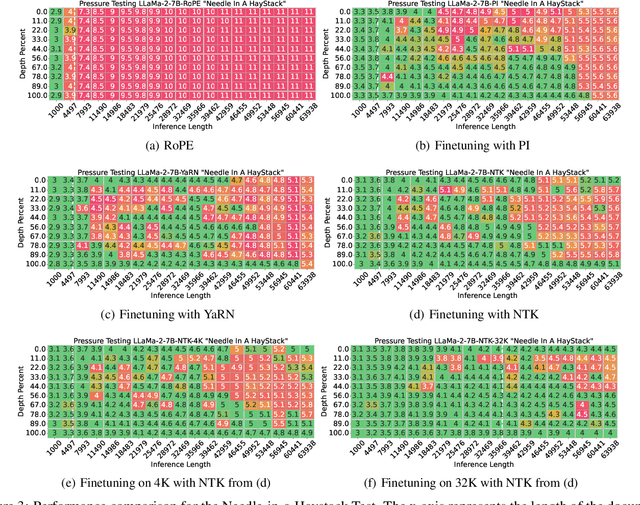
Enabling LLMs to handle lengthy context is currently a research hotspot. Most LLMs are built upon rotary position embedding (RoPE), a popular position encoding method. Therefore, a prominent path is to extrapolate the RoPE trained on comparably short texts to far longer texts. A heavy bunch of efforts have been dedicated to boosting the extrapolation via extending the formulations of the RoPE, however, few of them have attempted to showcase their inner workings comprehensively. In this paper, we are driven to offer a straightforward yet in-depth understanding of RoPE extensions from an attention perspective and on two benchmarking tasks. A broad array of experiments reveals several valuable findings: 1) Maintaining attention patterns to those at the pretrained length improves extrapolation; 2) Large attention uncertainty leads to retrieval errors; 3) Using longer continual pretraining lengths for RoPE extensions could reduce attention uncertainty and significantly enhance extrapolation.
Towards a Deep Understanding of Multilingual End-to-End Speech Translation
Oct 31, 2023



In this paper, we employ Singular Value Canonical Correlation Analysis (SVCCA) to analyze representations learnt in a multilingual end-to-end speech translation model trained over 22 languages. SVCCA enables us to estimate representational similarity across languages and layers, enhancing our understanding of the functionality of multilingual speech translation and its potential connection to multilingual neural machine translation. The multilingual speech translation model is trained on the CoVoST 2 dataset in all possible directions, and we utilize LASER to extract parallel bitext data for SVCCA analysis. We derive three major findings from our analysis: (I) Linguistic similarity loses its efficacy in multilingual speech translation when the training data for a specific language is limited. (II) Enhanced encoder representations and well-aligned audio-text data significantly improve translation quality, surpassing the bilingual counterparts when the training data is not compromised. (III) The encoder representations of multilingual speech translation demonstrate superior performance in predicting phonetic features in linguistic typology prediction. With these findings, we propose that releasing the constraint of limited data for low-resource languages and subsequently combining them with linguistically related high-resource languages could offer a more effective approach for multilingual end-to-end speech translation.
NEUer at SemEval-2021 Task 4: Complete Summary Representation by Filling Answers into Question for Matching Reading Comprehension
May 25, 2021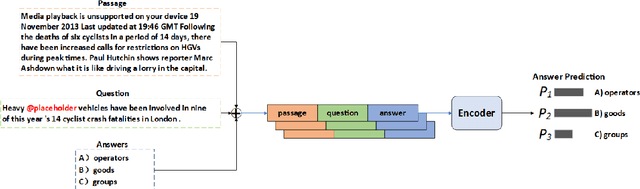
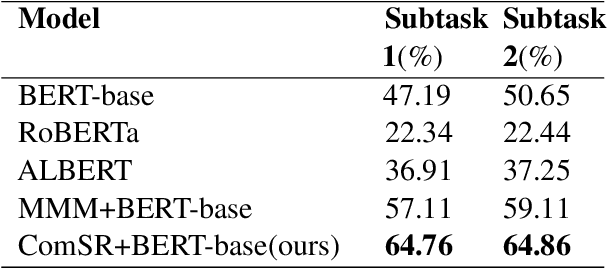
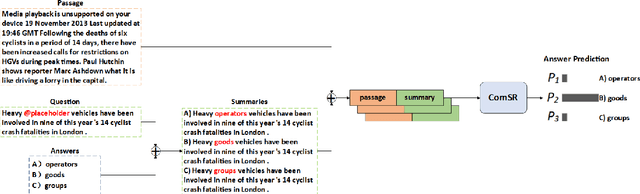

SemEval task 4 aims to find a proper option from multiple candidates to resolve the task of machine reading comprehension. Most existing approaches propose to concat question and option together to form a context-aware model. However, we argue that straightforward concatenation can only provide a coarse-grained context for the MRC task, ignoring the specific positions of the option relative to the question. In this paper, we propose a novel MRC model by filling options into the question to produce a fine-grained context (defined as summary) which can better reveal the relationship between option and question. We conduct a series of experiments on the given dataset, and the results show that our approach outperforms other counterparts to a large extent.