 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
VisualActBench: Can VLMs See and Act like a Human?
Dec 10, 2025Vision-Language Models (VLMs) have achieved impressive progress in perceiving and describing visual environments. However, their ability to proactively reason and act based solely on visual inputs, without explicit textual prompts, remains underexplored. We introduce a new task, Visual Action Reasoning, and propose VisualActBench, a large-scale benchmark comprising 1,074 videos and 3,733 human-annotated actions across four real-world scenarios. Each action is labeled with an Action Prioritization Level (APL) and a proactive-reactive type to assess models' human-aligned reasoning and value sensitivity. We evaluate 29 VLMs on VisualActBench and find that while frontier models like GPT4o demonstrate relatively strong performance, a significant gap remains compared to human-level reasoning, particularly in generating proactive, high-priority actions. Our results highlight limitations in current VLMs' ability to interpret complex context, anticipate outcomes, and align with human decision-making frameworks. VisualActBench establishes a comprehensive foundation for assessing and improving the real-world readiness of proactive, vision-centric AI agents.
Model Selection for Off-policy Evaluation: New Algorithms and Experimental Protocol
Feb 11, 2025



Holdout validation and hyperparameter tuning from data is a long-standing problem in offline reinforcement learning (RL). A standard framework is to use off-policy evaluation (OPE) methods to evaluate and select the policies, but OPE either incurs exponential variance (e.g., importance sampling) or has hyperparameters on their own (e.g., FQE and model-based). In this work we focus on hyperparameter tuning for OPE itself, which is even more under-investigated. Concretely, we select among candidate value functions ("model-free") or dynamics ("model-based") to best assess the performance of a target policy. Our contributions are two fold. We develop: (1) new model-free and model-based selectors with theoretical guarantees, and (2) a new experimental protocol for empirically evaluating them. Compared to the model-free protocol in prior works, our new protocol allows for more stable generation of candidate value functions, better control of misspecification, and evaluation of model-free and model-based methods alike. We exemplify the protocol on a Gym environment, and find that our new model-free selector, LSTD-Tournament, demonstrates promising empirical performance.
Assign Experiment Variants at Scale in Online Controlled Experiments
Dec 17, 2022Online controlled experiments (A/B tests) have become the gold standard for learning the impact of new product features in technology companies. Randomization enables the inference of causality from an A/B test. The randomized assignment maps end users to experiment buckets and balances user characteristics between the groups. Therefore, experiments can attribute any outcome differences between the experiment groups to the product feature under experiment. Technology companies run A/B tests at scale -- hundreds if not thousands of A/B tests concurrently, each with millions of users. The large scale poses unique challenges to randomization. First, the randomized assignment must be fast since the experiment service receives hundreds of thousands of queries per second. Second, the variant assignments must be independent between experiments. Third, the assignment must be consistent when users revisit or an experiment enrolls more users. We present a novel assignment algorithm and statistical tests to validate the randomized assignments. Our results demonstrate that not only is this algorithm computationally fast but also satisfies the statistical requirements -- unbiased and independent.
Open Information Extraction from 2007 to 2022 -- A Survey
Aug 18, 2022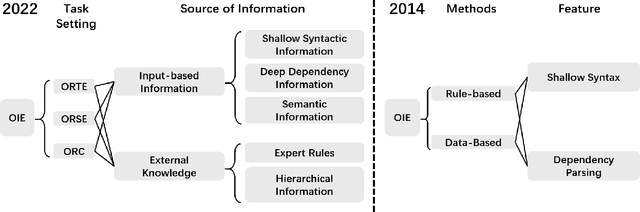
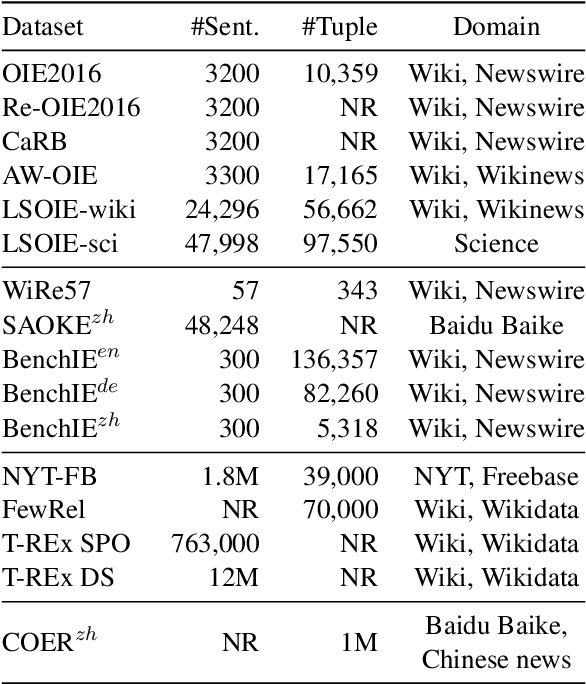
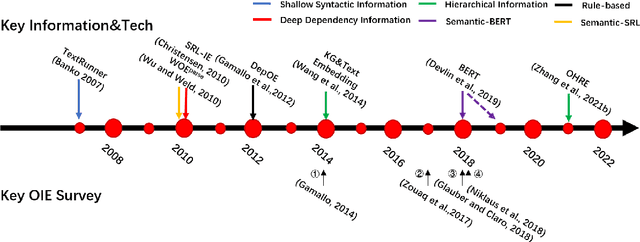
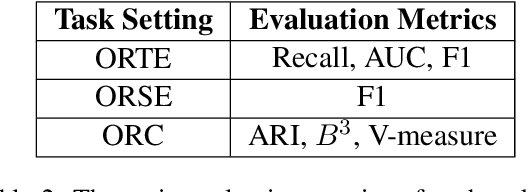
Open information extraction is an important NLP task that targets extracting structured information from unstructured text without limitations on the relation type or the domain of the text. This survey paper covers open information extraction technologies from 2007 to 2022 with a focus on new models not covered by previous surveys. We propose a new categorization method from the source of information perspective to accommodate the development of recent OIE technologies. In addition, we summarize three major approaches based on task settings as well as current popular datasets and model evaluation metrics. Given the comprehensive review, several future directions are shown from datasets, source of information, output form, method, and evaluation metric aspects.
Exploring Generative Neural Temporal Point Process
Aug 04, 2022
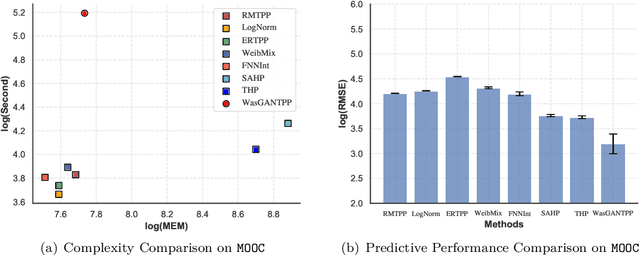
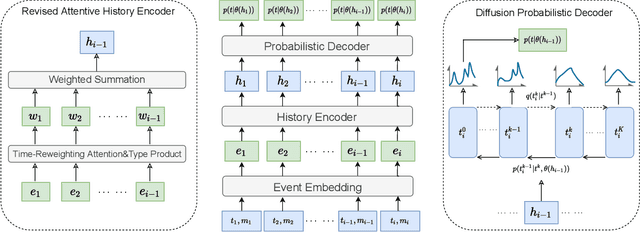

Temporal point process (TPP) is commonly used to model the asynchronous event sequence featuring occurrence timestamps and revealed by probabilistic models conditioned on historical impacts. While lots of previous works have focused on `goodness-of-fit' of TPP models by maximizing the likelihood, their predictive performance is unsatisfactory, which means the timestamps generated by models are far apart from true observations. Recently, deep generative models such as denoising diffusion and score matching models have achieved great progress in image generating tasks by demonstrating their capability of generating samples of high quality. However, there are no complete and unified works exploring and studying the potential of generative models in the context of event occurence modeling for TPP. In this work, we try to fill the gap by designing a unified \textbf{g}enerative framework for \textbf{n}eural \textbf{t}emporal \textbf{p}oint \textbf{p}rocess (\textsc{GNTPP}) model to explore their feasibility and effectiveness, and further improve models' predictive performance. Besides, in terms of measuring the historical impacts, we revise the attentive models which summarize influence from historical events with an adaptive reweighting term considering events' type relation and time intervals. Extensive experiments have been conducted to illustrate the improved predictive capability of \textsc{GNTPP} with a line of generative probabilistic decoders, and performance gain from the revised attention. To the best of our knowledge, this is the first work that adapts generative models in a complete unified framework and studies their effectiveness in the context of TPP. Our codebase including all the methods given in Section.5.1.1 is open in \url{https://github.com/BIRD-TAO/GNTPP}. We hope the code framework can facilitate future research in Neural TPPs.
Can Generative Pre-trained Language Models Serve as Knowledge Bases for Closed-book QA?
Jun 03, 2021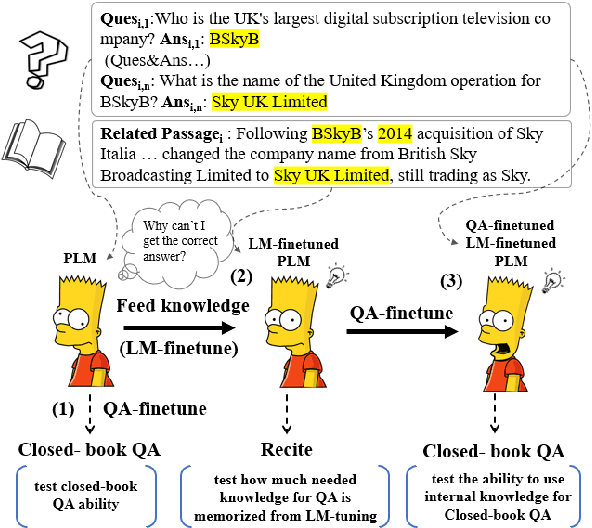
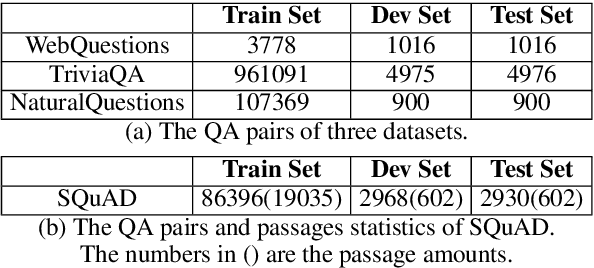
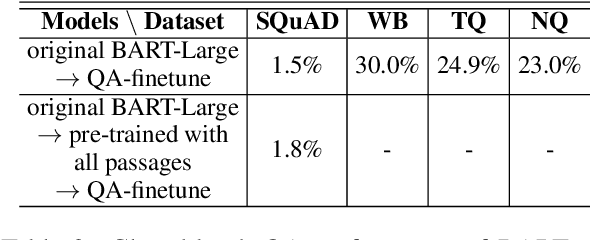
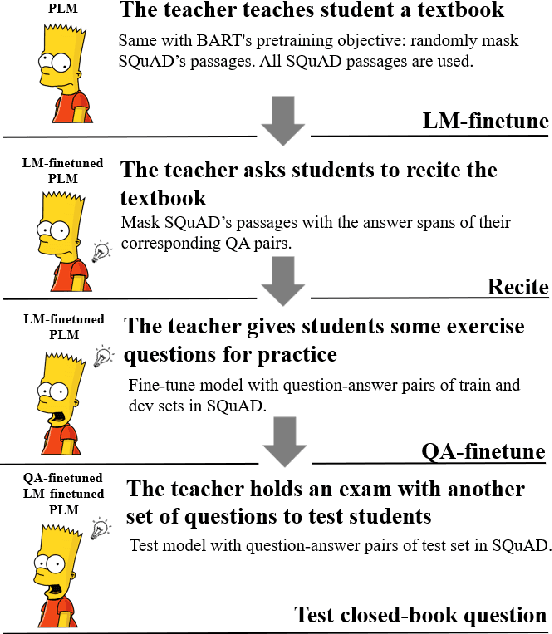
Recent work has investigated the interesting question using pre-trained language models (PLMs) as knowledge bases for answering open questions. However, existing work is limited in using small benchmarks with high test-train overlaps. We construct a new dataset of closed-book QA using SQuAD, and investigate the performance of BART. Experiments show that it is challenging for BART to remember training facts in high precision, and also challenging to answer closed-book questions even if relevant knowledge is retained. Some promising directions are found, including decoupling the knowledge memorizing process and the QA finetune process, forcing the model to recall relevant knowledge when question answering.
NEUer at SemEval-2021 Task 4: Complete Summary Representation by Filling Answers into Question for Matching Reading Comprehension
May 25, 2021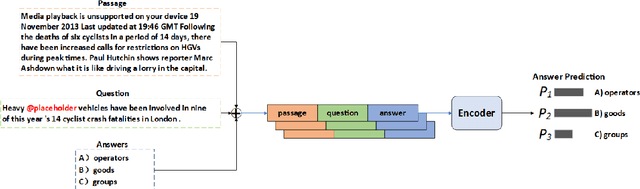
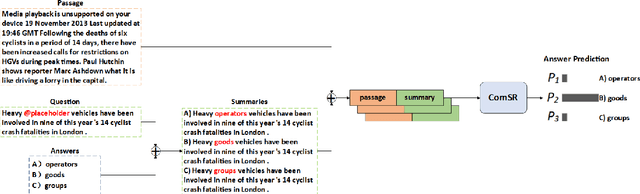

SemEval task 4 aims to find a proper option from multiple candidates to resolve the task of machine reading comprehension. Most existing approaches propose to concat question and option together to form a context-aware model. However, we argue that straightforward concatenation can only provide a coarse-grained context for the MRC task, ignoring the specific positions of the option relative to the question. In this paper, we propose a novel MRC model by filling options into the question to produce a fine-grained context (defined as summary) which can better reveal the relationship between option and question. We conduct a series of experiments on the given dataset, and the results show that our approach outperforms other counterparts to a large extent.
QiaoNing at SemEval-2020 Task 4: Commonsense Validation and Explanation system based on ensemble of language model
Sep 06, 2020


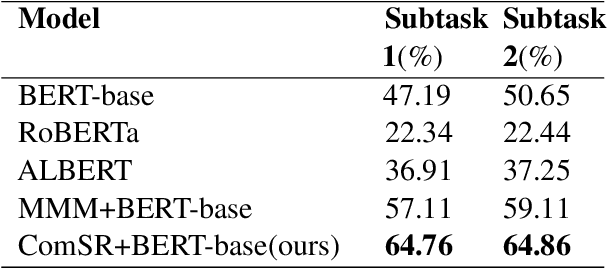
In this paper, we present language model system submitted to SemEval-2020 Task 4 competition: "Commonsense Validation and Explanation". We participate in two subtasks for subtask A: validation and subtask B: Explanation. We implemented with transfer learning using pretrained language models (BERT, XLNet, RoBERTa, and ALBERT) and fine-tune them on this task. Then we compared their characteristics in this task to help future researchers understand and use these models more properly. The ensembled model better solves this problem, making the model's accuracy reached 95.9% on subtask A, which just worse than human's by only 3% accuracy.
Introducing a Generative Adversarial Network Model for Lagrangian Trajectory Simulation
Jan 13, 2019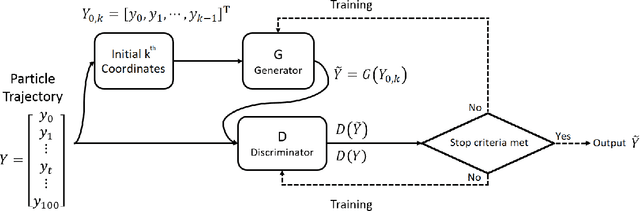
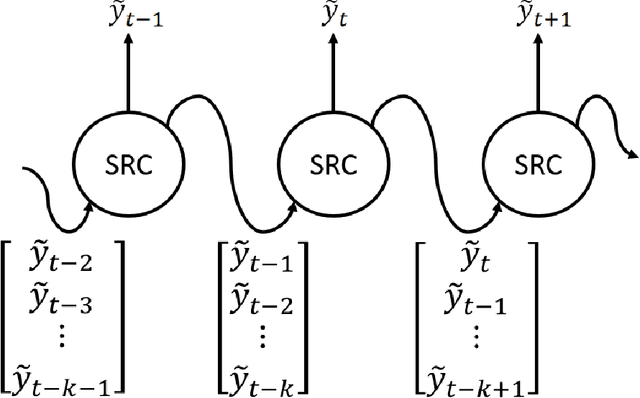
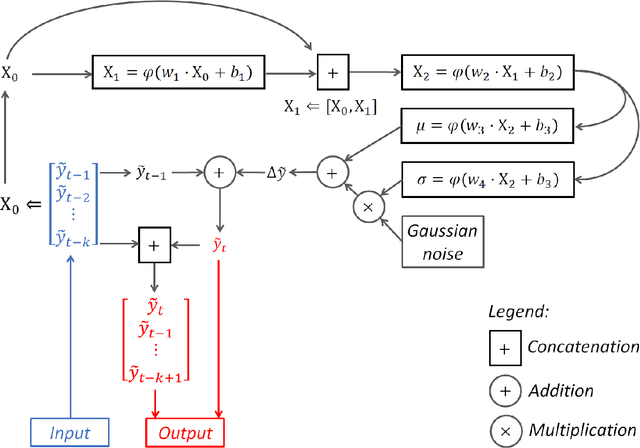
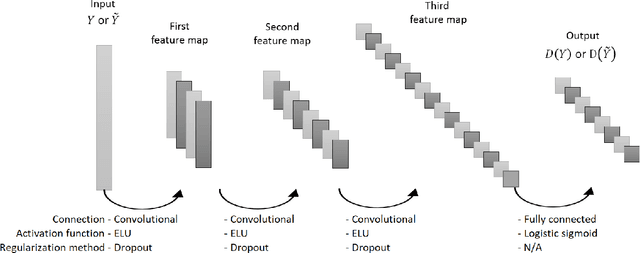
We introduce a generative adversarial network (GAN) model to simulate the 3-dimensional Lagrangian motion of particles trapped in the recirculation zone of a buoyancy-opposed flame. The GAN model comprises a stochastic recurrent neural network, serving as a generator, and a convoluted neural network, serving as a discriminator. Adversarial training was performed to the point where the best-trained discriminator failed to distinguish the ground truth from the trajectory produced by the best-trained generator. The model performance was then benchmarked against a statistical analysis performed on both the simulated trajectories and the ground truth, with regard to the accuracy and generalization criteria.