 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIC3D: Style Image Conditioned Text-to-3D Gaussian Splatting Generation
Apr 09, 2026Recent progress in text-to-3D object generation enables the synthesis of detailed geometry from text input by leveraging 2D diffusion models and differentiable 3D representations. However, the approaches often suffer from limited controllability and texture ambiguity due to the limitation of the text modality. To address this, we present SIC3D, a controllable image-conditioned text-to-3D generation pipeline with 3D Gaussian Splatting (3DGS). There are two stages in SIC3D. The first stage generates the 3D object content from text with a text-to-3DGS generation model. The second stage transfers style from a reference image to the 3DGS. Within this stylization stage, we introduce a novel Variational Stylized Score Distillation (VSSD) loss to effectively capture both global and local texture patterns while mitigating conflicts between geometry and appearance. A scaling regularization is further applied to prevent the emergence of artifacts and preserve the pattern from the style image. Extensive experiments demonstrate that SIC3D enhances geometric fidelity and style adherence, outperforming prior approaches in both qualitative and quantitative evaluations.
SegMo: Segment-aligned Text to 3D Human Motion Generation
Dec 24, 2025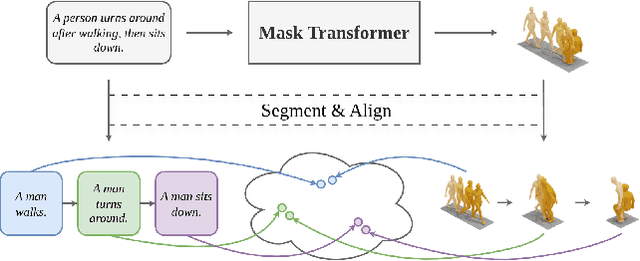
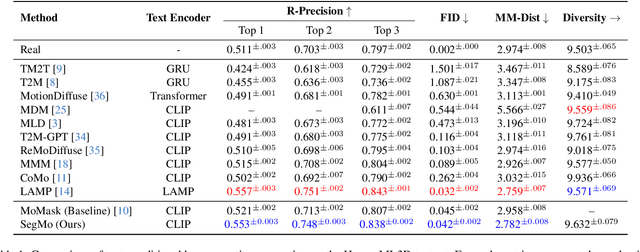
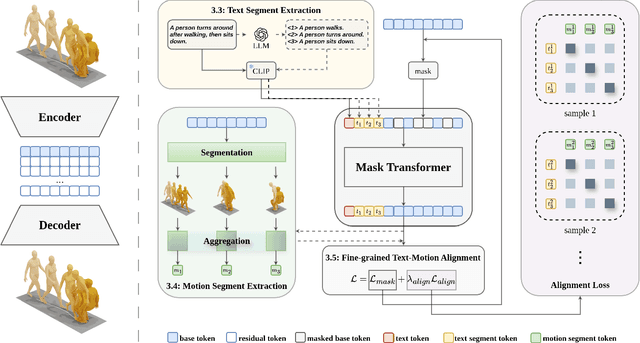
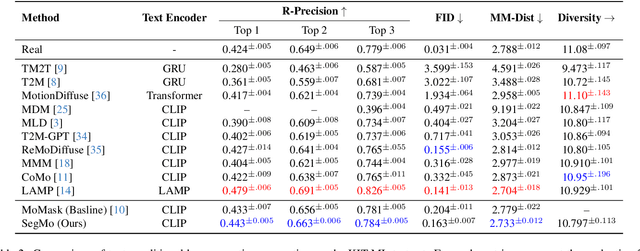
Generating 3D human motions from textual descriptions is an important research problem with broad applications in video games, virtual reality, and augmented reality. Recent methods align the textual description with human motion at the sequence level, neglecting the internal semantic structure of modalities. However, both motion descriptions and motion sequences can be naturally decomposed into smaller and semantically coherent segments, which can serve as atomic alignment units to achieve finer-grained correspondence. Motivated by this, we propose SegMo, a novel Segment-aligned text-conditioned human Motion generation framework to achieve fine-grained text-motion alignment. Our framework consists of three modules: (1) Text Segment Extraction, which decomposes complex textual descriptions into temporally ordered phrases, each representing a simple atomic action; (2) Motion Segment Extraction, which partitions complete motion sequences into corresponding motion segments; and (3) Fine-grained Text-Motion Alignment, which aligns text and motion segments with contrastive learning. Extensive experiments demonstrate that SegMo improves the strong baseline on two widely used datasets, achieving an improved TOP 1 score of 0.553 on the HumanML3D test set. Moreover, thanks to the learned shared embedding space for text and motion segments, SegMo can also be applied to retrieval-style tasks such as motion grounding and motion-to-text retrieval.
HOI-Dyn: Learning Interaction Dynamics for Human-Object Motion Diffusion
Jul 03, 2025Generating realistic 3D human-object interactions (HOIs) remains a challenging task due to the difficulty of modeling detailed interaction dynamics. Existing methods treat human and object motions independently, resulting in physically implausible and causally inconsistent behaviors. In this work, we present HOI-Dyn, a novel framework that formulates HOI generation as a driver-responder system, where human actions drive object responses. At the core of our method is a lightweight transformer-based interaction dynamics model that explicitly predicts how objects should react to human motion. To further enforce consistency, we introduce a residual-based dynamics loss that mitigates the impact of dynamics prediction errors and prevents misleading optimization signals. The dynamics model is used only during training, preserving inference efficiency. Through extensive qualitative and quantitative experiments, we demonstrate that our approach not only enhances the quality of HOI generation but also establishes a feasible metric for evaluating the quality of generated interactions.
PViT: Prior-augmented Vision Transformer for Out-of-distribution Detection
Oct 27, 2024


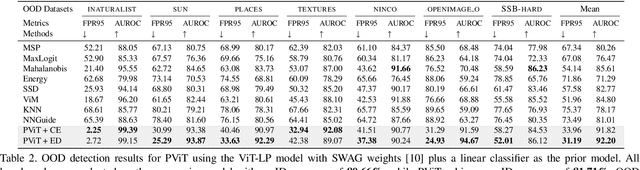
Vision Transformers (ViTs) have achieved remarkable success over various vision tasks, yet their robustness against data distribution shifts and inherent inductive biases remain underexplored. To enhance the robustness of ViT models for image Out-of-Distribution (OOD) detection, we introduce a novel and generic framework named Prior-augmented Vision Transformer (PViT). PViT identifies OOD samples by quantifying the divergence between the predicted class logits and the prior logits obtained from pre-trained models. Unlike existing state-of-the-art OOD detection methods, PViT shapes the decision boundary between ID and OOD by utilizing the proposed prior guide confidence, without requiring additional data modeling, generation methods, or structural modifications. Extensive experiments on the large-scale ImageNet benchmark demonstrate that PViT significantly outperforms existing state-of-the-art OOD detection methods. Additionally, through comprehensive analyses, ablation studies, and discussions, we show how PViT can strategically address specific challenges in managing large vision models, paving the way for new advancements in OOD detection.
MAPConNet: Self-supervised 3D Pose Transfer with Mesh and Point Contrastive Learning
Apr 26, 20233D pose transfer is a challenging generation task that aims to transfer the pose of a source geometry onto a target geometry with the target identity preserved. Many prior methods require keypoint annotations to find correspondence between the source and target. Current pose transfer methods allow end-to-end correspondence learning but require the desired final output as ground truth for supervision. Unsupervised methods have been proposed for graph convolutional models but they require ground truth correspondence between the source and target inputs. We present a novel self-supervised framework for 3D pose transfer which can be trained in unsupervised, semi-supervised, or fully supervised settings without any correspondence labels. We introduce two contrastive learning constraints in the latent space: a mesh-level loss for disentangling global patterns including pose and identity, and a point-level loss for discriminating local semantics. We demonstrate quantitatively and qualitatively that our method achieves state-of-the-art results in supervised 3D pose transfer, with comparable results in unsupervised and semi-supervised settings. Our method is also generalisable to unseen human and animal data with complex topologies.
Semi-Supervised Object Detection with Object-wise Contrastive Learning and Regression Uncertainty
Dec 06, 2022Semi-supervised object detection (SSOD) aims to boost detection performance by leveraging extra unlabeled data. The teacher-student framework has been shown to be promising for SSOD, in which a teacher network generates pseudo-labels for unlabeled data to assist the training of a student network. Since the pseudo-labels are noisy, filtering the pseudo-labels is crucial to exploit the potential of such framework. Unlike existing suboptimal methods, we propose a two-step pseudo-label filtering for the classification and regression heads in a teacher-student framework. For the classification head, OCL (Object-wise Contrastive Learning) regularizes the object representation learning that utilizes unlabeled data to improve pseudo-label filtering by enhancing the discriminativeness of the classification score. This is designed to pull together objects in the same class and push away objects from different classes. For the regression head, we further propose RUPL (Regression-Uncertainty-guided Pseudo-Labeling) to learn the aleatoric uncertainty of object localization for label filtering. By jointly filtering the pseudo-labels for the classification and regression heads, the student network receives better guidance from the teacher network for object detection task. Experimental results on Pascal VOC and MS-COCO datasets demonstrate the superiority of our proposed method with competitive performance compared to existing methods.
SeCGAN: Parallel Conditional Generative Adversarial Networks for Face Editing via Semantic Consistency
Nov 24, 2021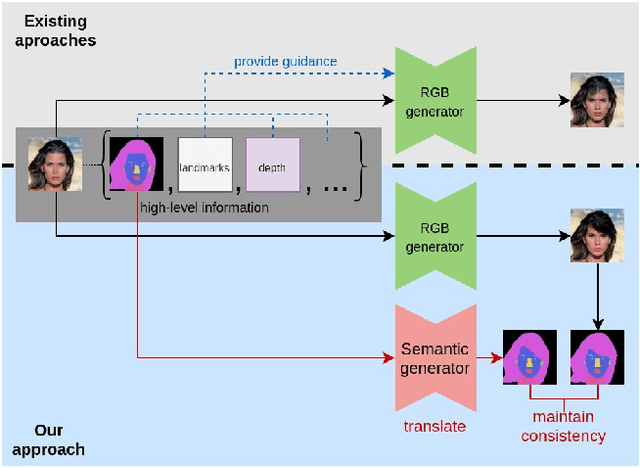
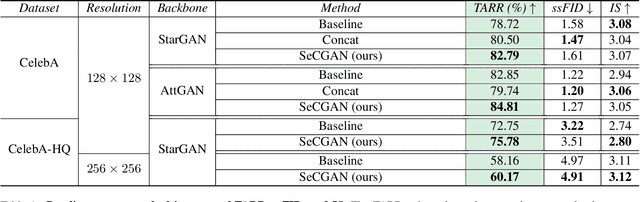
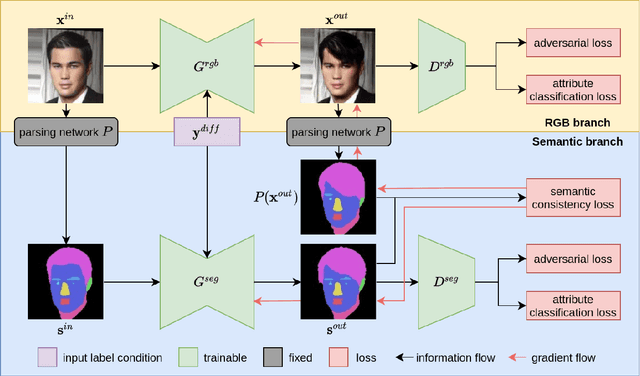
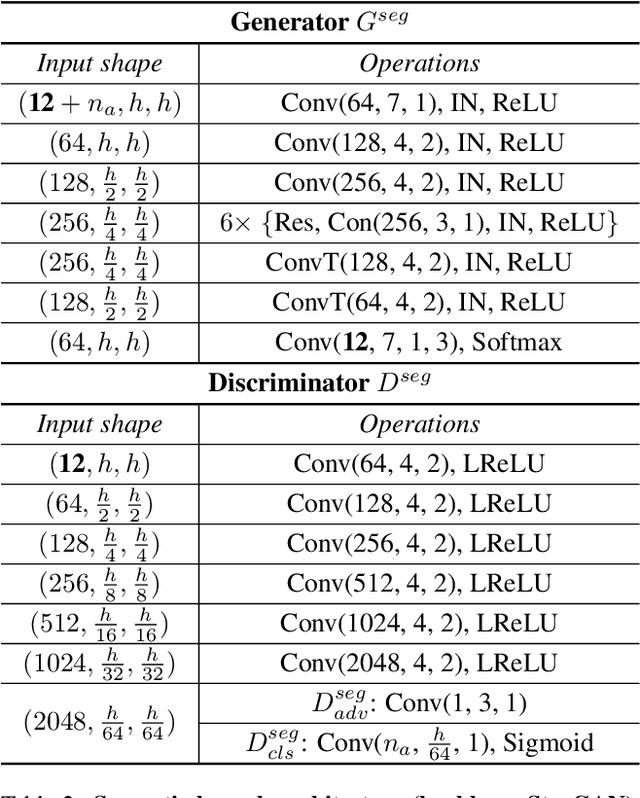
Semantically guided conditional Generative Adversarial Networks (cGANs) have become a popular approach for face editing in recent years. However, most existing methods introduce semantic masks as direct conditional inputs to the generator and often require the target masks to perform the corresponding translation in the RGB space. We propose SeCGAN, a novel label-guided cGAN for editing face images utilising semantic information without the need to specify target semantic masks. During training, SeCGAN has two branches of generators and discriminators operating in parallel, with one trained to translate RGB images and the other for semantic masks. To bridge the two branches in a mutually beneficial manner, we introduce a semantic consistency loss which constrains both branches to have consistent semantic outputs. Whilst both branches are required during training, the RGB branch is our primary network and the semantic branch is not needed for inference. Our results on CelebA and CelebA-HQ demonstrate that our approach is able to generate facial images with more accurate attributes, outperforming competitive baselines in terms of Target Attribute Recognition Rate whilst maintaining quality metrics such as self-supervised Fr\'{e}chet Inception Distance and Inception Score.
NEUer at SemEval-2021 Task 4: Complete Summary Representation by Filling Answers into Question for Matching Reading Comprehension
May 25, 2021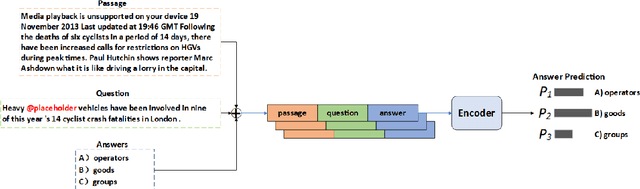
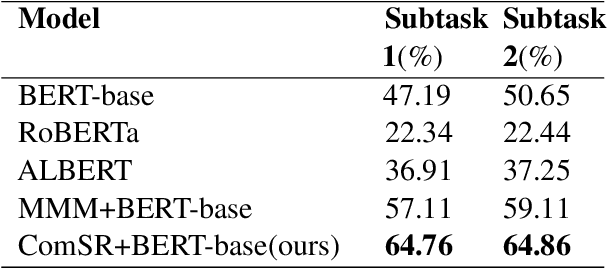
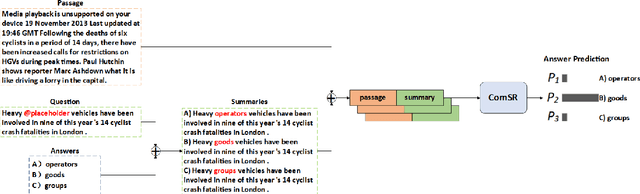

SemEval task 4 aims to find a proper option from multiple candidates to resolve the task of machine reading comprehension. Most existing approaches propose to concat question and option together to form a context-aware model. However, we argue that straightforward concatenation can only provide a coarse-grained context for the MRC task, ignoring the specific positions of the option relative to the question. In this paper, we propose a novel MRC model by filling options into the question to produce a fine-grained context (defined as summary) which can better reveal the relationship between option and question. We conduct a series of experiments on the given dataset, and the results show that our approach outperforms other counterparts to a large extent.
Learning Feature Aggregation for Deep 3D Morphable Models
May 05, 2021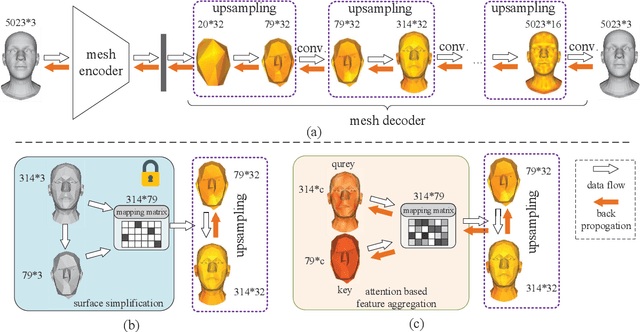

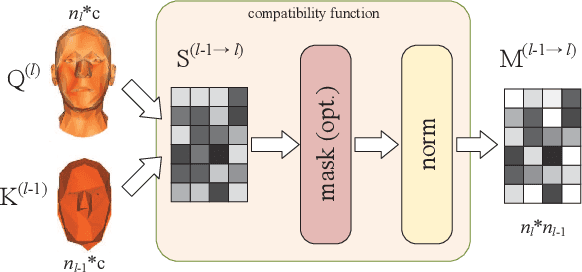

3D morphable models are widely used for the shape representation of an object class in computer vision and graphics applications. In this work, we focus on deep 3D morphable models that directly apply deep learning on 3D mesh data with a hierarchical structure to capture information at multiple scales. While great efforts have been made to design the convolution operator, how to best aggregate vertex features across hierarchical levels deserves further attention. In contrast to resorting to mesh decimation, we propose an attention based module to learn mapping matrices for better feature aggregation across hierarchical levels. Specifically, the mapping matrices are generated by a compatibility function of the keys and queries. The keys and queries are trainable variables, learned by optimizing the target objective, and shared by all data samples of the same object class. Our proposed module can be used as a train-only drop-in replacement for the feature aggregation in existing architectures for both downsampling and upsampling. Our experiments show that through the end-to-end training of the mapping matrices, we achieve state-of-the-art results on a variety of 3D shape datasets in comparison to existing morphable models.
Geometry-based Distance Decomposition for Monocular 3D Object Detection
Apr 08, 2021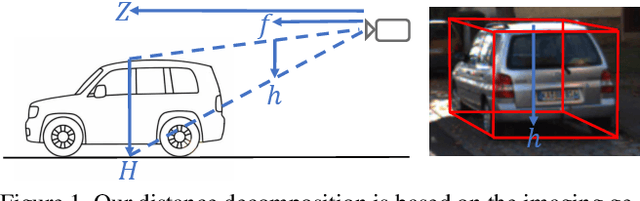
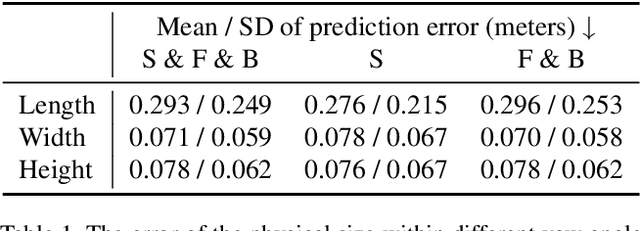

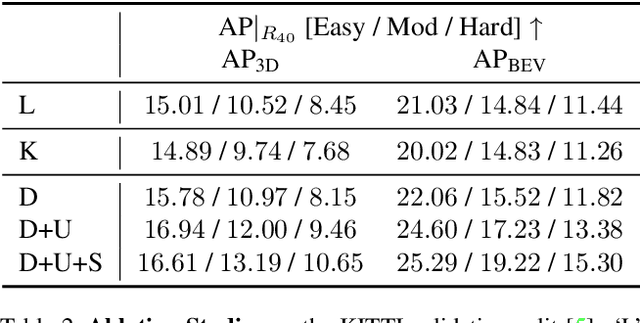
Monocular 3D object detection is of great significance for autonomous driving but remains challenging. The core challenge is to predict the distance of objects in the absence of explicit depth information. Unlike regressing the distance as a single variable in most existing methods, we propose a novel geometry-based distance decomposition to recover the distance by its factors. The decomposition factors the distance of objects into the most representative and stable variables, i.e. the physical height and the projected visual height in the image plane. Moreover, the decomposition maintains the self-consistency between the two heights, leading to the robust distance prediction when both predicted heights are inaccurate. The decomposition also enables us to trace the cause of the distance uncertainty for different scenarios. Such decomposition makes the distance prediction interpretable, accurate, and robust. Our method directly predicts 3D bounding boxes from RGB images with a compact architecture, making the training and inference simple and efficient. The experimental results show that our method achieves the state-of-the-art performance on the monocular 3D Object detection and Birds Eye View tasks on the KITTI dataset, and can generalize to images with different camera intrinsics.