 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeCGAN: Parallel Conditional Generative Adversarial Networks for Face Editing via Semantic Consistency
Paper and Code
Nov 24, 2021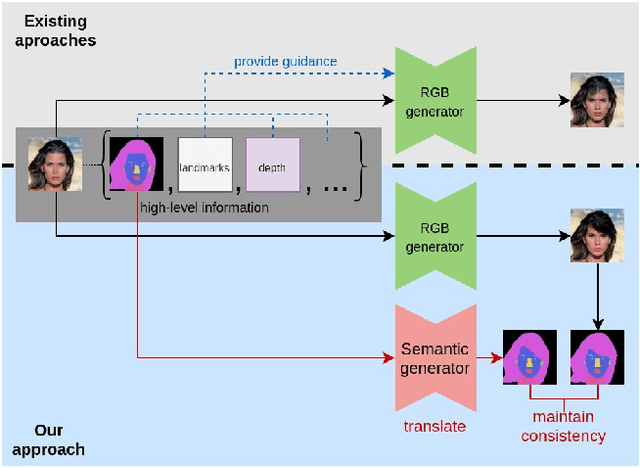
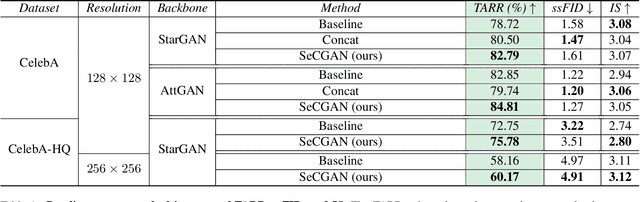
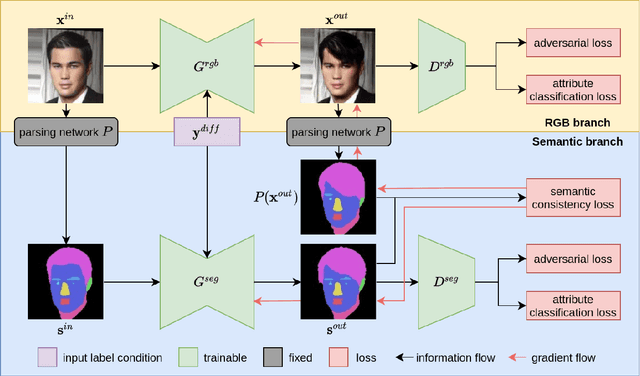
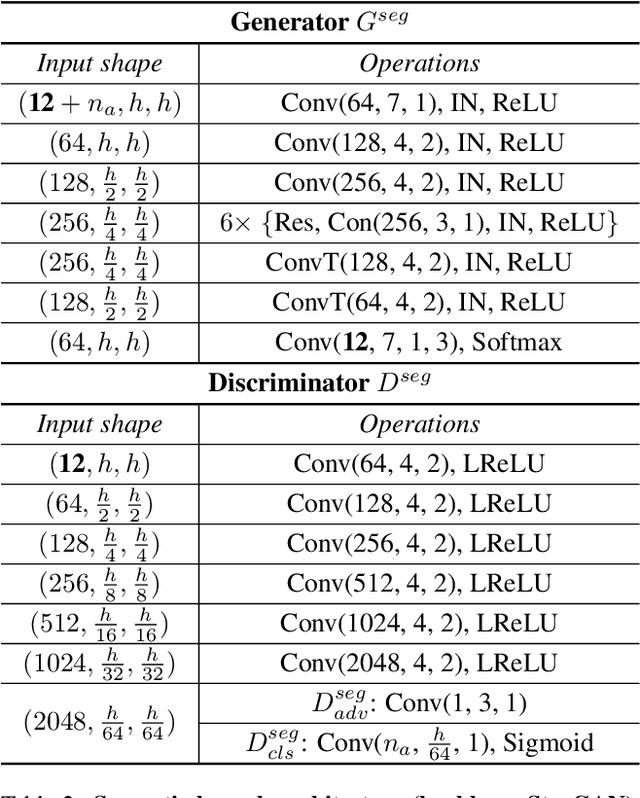
Semantically guided conditional Generative Adversarial Networks (cGANs) have become a popular approach for face editing in recent years. However, most existing methods introduce semantic masks as direct conditional inputs to the generator and often require the target masks to perform the corresponding translation in the RGB space. We propose SeCGAN, a novel label-guided cGAN for editing face images utilising semantic information without the need to specify target semantic masks. During training, SeCGAN has two branches of generators and discriminators operating in parallel, with one trained to translate RGB images and the other for semantic masks. To bridge the two branches in a mutually beneficial manner, we introduce a semantic consistency loss which constrains both branches to have consistent semantic outputs. Whilst both branches are required during training, the RGB branch is our primary network and the semantic branch is not needed for inference. Our results on CelebA and CelebA-HQ demonstrate that our approach is able to generate facial images with more accurate attributes, outperforming competitive baselines in terms of Target Attribute Recognition Rate whilst maintaining quality metrics such as self-supervised Fr\'{e}chet Inception Distance and Inception Score.