 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo is better than one: A Collapse-free Multi-Reward RLIF Training Framework
May 21, 2026Reinforcement learning with verifiable rewards (RLVR) has substantially improved the reasoning ability of LLMs, but often depends on external supervision from human annotations or gold-standard solutions. Reinforcement learning from internal feedback (RLIF) has recently emerged as a scalable unsupervised alternative, using signals extracted from the model itself. However, existing RLIF methods typically rely on a single internal reward, which can lead to reward hacking, entropy collapse, and degraded reasoning structure. We propose a multi-reward RLIF framework that decomposes the training signal into two complementary components: an answer-level reward based on cluster voting and a completion-level reward based on token-wise self-certainty. To combine these signals robustly, we apply GDPO-based normalization to reduce reward-scale imbalance. We further introduce KL-Cov regularization, which targets low-entropy token distributions responsible for disproportionate entropy reduction, preserving exploration and preventing late-stage collapse. Across mathematical reasoning and code-generation benchmarks, our method improves stability and robustness over prior unsupervised RL approaches, while achieving performance close to supervised RLVR methods. These results show that complementary internal rewards, combined with targeted regularization, can support stable long-horizon reasoning without relying on external ground-truth supervision. Code will be released soon.
HandVQA: Diagnosing and Improving Fine-Grained Spatial Reasoning about Hands in Vision-Language Models
Mar 27, 2026Understanding the fine-grained articulation of human hands is critical in high-stakes settings such as robot-assisted surgery, chip manufacturing, and AR/VR-based human-AI interaction. Despite achieving near-human performance on general vision-language benchmarks, current vision-language models (VLMs) struggle with fine-grained spatial reasoning, especially in interpreting complex and articulated hand poses. We introduce HandVQA, a large-scale diagnostic benchmark designed to evaluate VLMs' understanding of detailed hand anatomy through visual question answering. Built upon high-quality 3D hand datasets (FreiHAND, InterHand2.6M, FPHA), our benchmark includes over 1.6M controlled multiple-choice questions that probe spatial relationships between hand joints, such as angles, distances, and relative positions. We evaluate several state-of-the-art VLMs (LLaVA, DeepSeek and Qwen-VL) in both base and fine-tuned settings, using lightweight fine-tuning via LoRA. Our findings reveal systematic limitations in current models, including hallucinated finger parts, incorrect geometric interpretations, and poor generalization. HandVQA not only exposes these critical reasoning gaps but provides a validated path to improvement. We demonstrate that the 3D-grounded spatial knowledge learned from our benchmark transfers in a zero-shot setting, significantly improving accuracy of model on novel downstream tasks like hand gesture recognition (+10.33%) and hand-object interaction (+2.63%).
FedVG: Gradient-Guided Aggregation for Enhanced Federated Learning
Feb 24, 2026Federated Learning (FL) enables collaborative model training across multiple clients without sharing their private data. However, data heterogeneity across clients leads to client drift, which degrades the overall generalization performance of the model. This effect is further compounded by overemphasis on poorly performing clients. To address this problem, we propose FedVG, a novel gradient-based federated aggregation framework that leverages a global validation set to guide the optimization process. Such a global validation set can be established using readily available public datasets, ensuring accessibility and consistency across clients without compromising privacy. In contrast to conventional approaches that prioritize client dataset volume, FedVG assesses the generalization ability of client models by measuring the magnitude of validation gradients across layers. Specifically, we compute layerwise gradient norms to derive a client-specific score that reflects how much each client needs to adjust for improved generalization on the global validation set, thereby enabling more informed and adaptive federated aggregation. Extensive experiments on both natural and medical image benchmarking datasets, across diverse model architectures, demonstrate that FedVG consistently improves performance, particularly in highly heterogeneous settings. Moreover, FedVG is modular and can be seamlessly integrated with various state-of-the-art FL algorithms, often further improving their results. Our code is available at https://github.com/alinadevkota/FedVG.
Med-MMFL: A Multimodal Federated Learning Benchmark in Healthcare
Feb 04, 2026Federated learning (FL) enables collaborative model training across decentralized medical institutions while preserving data privacy. However, medical FL benchmarks remain scarce, with existing efforts focusing mainly on unimodal or bimodal modalities and a limited range of medical tasks. This gap underscores the need for standardized evaluation to advance systematic understanding in medical MultiModal FL (MMFL). To this end, we introduce Med-MMFL, the first comprehensive MMFL benchmark for the medical domain, encompassing diverse modalities, tasks, and federation scenarios. Our benchmark evaluates six representative state-of-the-art FL algorithms, covering different aggregation strategies, loss formulations, and regularization techniques. It spans datasets with 2 to 4 modalities, comprising a total of 10 unique medical modalities, including text, pathology images, ECG, X-ray, radiology reports, and multiple MRI sequences. Experiments are conducted across naturally federated, synthetic IID, and synthetic non-IID settings to simulate real-world heterogeneity. We assess segmentation, classification, modality alignment (retrieval), and VQA tasks. To support reproducibility and fair comparison of future multimodal federated learning (MMFL) methods under realistic medical settings, we release the complete benchmark implementation, including data processing and partitioning pipelines, at https://github.com/bhattarailab/Med-MMFL-Benchmark .
Local K-Similarity Constraint for Federated Learning with Label Noise
Nov 09, 2025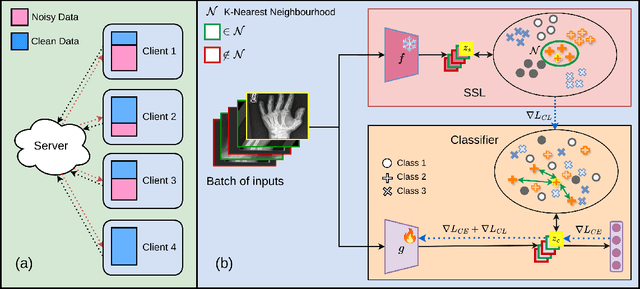

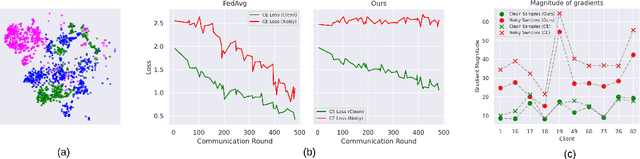
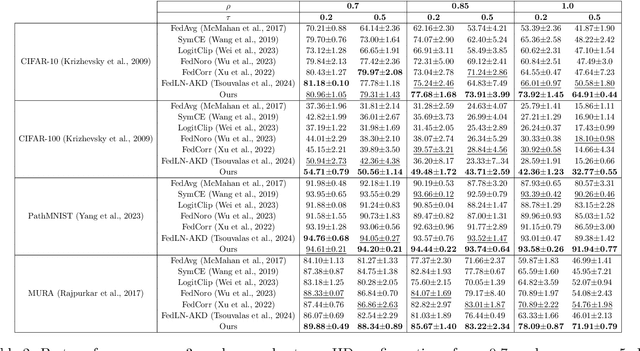
Federated learning on clients with noisy labels is a challenging problem, as such clients can infiltrate the global model, impacting the overall generalizability of the system. Existing methods proposed to handle noisy clients assume that a sufficient number of clients with clean labels are available, which can be leveraged to learn a robust global model while dampening the impact of noisy clients. This assumption fails when a high number of heterogeneous clients contain noisy labels, making the existing approaches ineffective. In such scenarios, it is important to locally regularize the clients before communication with the global model, to ensure the global model isn't corrupted by noisy clients. While pre-trained self-supervised models can be effective for local regularization, existing centralized approaches relying on pretrained initialization are impractical in a federated setting due to the potentially large size of these models, which increases communication costs. In that line, we propose a regularization objective for client models that decouples the pre-trained and classification models by enforcing similarity between close data points within the client. We leverage the representation space of a self-supervised pretrained model to evaluate the closeness among examples. This regularization, when applied with the standard objective function for the downstream task in standard noisy federated settings, significantly improves performance, outperforming existing state-of-the-art federated methods in multiple computer vision and medical image classification benchmarks. Unlike other techniques that rely on self-supervised pretrained initialization, our method does not require the pretrained model and classifier backbone to share the same architecture, making it architecture-agnostic.
Estimating 2D Keypoints of Surgical Tools Using Vision-Language Models with Low-Rank Adaptation
Aug 28, 2025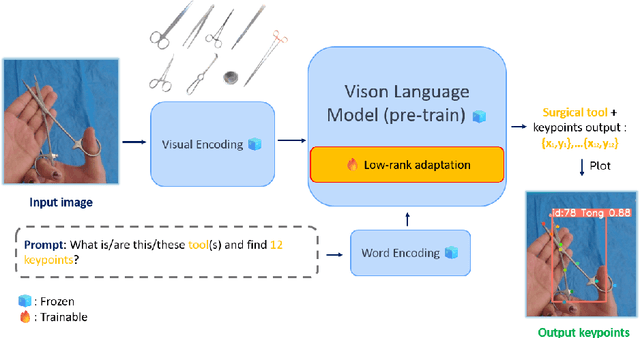



This paper presents a novel pipeline for 2D keypoint estima- tion of surgical tools by leveraging Vision Language Models (VLMs) fine- tuned using a low rank adjusting (LoRA) technique. Unlike traditional Convolutional Neural Network (CNN) or Transformer-based approaches, which often suffer from overfitting in small-scale medical datasets, our method harnesses the generalization capabilities of pre-trained VLMs. We carefully design prompts to create an instruction-tuning dataset and use them to align visual features with semantic keypoint descriptions. Experimental results show that with only two epochs of fine tuning, the adapted VLM outperforms the baseline models, demonstrating the ef- fectiveness of LoRA in low-resource scenarios. This approach not only improves keypoint detection performance, but also paves the way for future work in 3D surgical hands and tools pose estimation.
Effect of Data Augmentation on Conformal Prediction for Diabetic Retinopathy
Aug 19, 2025The clinical deployment of deep learning models for high-stakes tasks such as diabetic retinopathy (DR) grading requires demonstrable reliability. While models achieve high accuracy, their clinical utility is limited by a lack of robust uncertainty quantification. Conformal prediction (CP) offers a distribution-free framework to generate prediction sets with statistical guarantees of coverage. However, the interaction between standard training practices like data augmentation and the validity of these guarantees is not well understood. In this study, we systematically investigate how different data augmentation strategies affect the performance of conformal predictors for DR grading. Using the DDR dataset, we evaluate two backbone architectures -- ResNet-50 and a Co-Scale Conv-Attentional Transformer (CoaT) -- trained under five augmentation regimes: no augmentation, standard geometric transforms, CLAHE, Mixup, and CutMix. We analyze the downstream effects on conformal metrics, including empirical coverage, average prediction set size, and correct efficiency. Our results demonstrate that sample-mixing strategies like Mixup and CutMix not only improve predictive accuracy but also yield more reliable and efficient uncertainty estimates. Conversely, methods like CLAHE can negatively impact model certainty. These findings highlight the need to co-design augmentation strategies with downstream uncertainty quantification in mind to build genuinely trustworthy AI systems for medical imaging.
Addressing Bias in VLMs for Glaucoma Detection Without Protected Attribute Supervision
Aug 12, 2025Vision-Language Models (VLMs) have achieved remarkable success on multimodal tasks such as image-text retrieval and zero-shot classification, yet they can exhibit demographic biases even when explicit protected attributes are absent during training. In this work, we focus on automated glaucoma screening from retinal fundus images, a critical application given that glaucoma is a leading cause of irreversible blindness and disproportionately affects underserved populations. Building on a reweighting-based contrastive learning framework, we introduce an attribute-agnostic debiasing method that (i) infers proxy subgroups via unsupervised clustering of image-image embeddings, (ii) computes gradient-similarity weights between the CLIP-style multimodal loss and a SimCLR-style image-pair contrastive loss, and (iii) applies these weights in a joint, top-$k$ weighted objective to upweight underperforming clusters. This label-free approach adaptively targets the hardest examples, thereby reducing subgroup disparities. We evaluate our method on the Harvard FairVLMed glaucoma subset, reporting Equalized Odds Distance (EOD), Equalized Subgroup AUC (ES AUC), and Groupwise AUC to demonstrate equitable performance across inferred demographic subgroups.
NERO: Explainable Out-of-Distribution Detection with Neuron-level Relevance
Jun 18, 2025

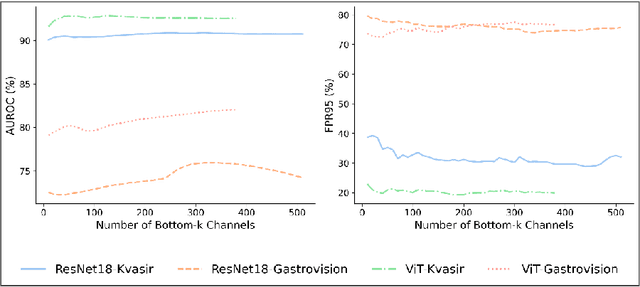

Ensuring reliability is paramount in deep learning, particularly within the domain of medical imaging, where diagnostic decisions often hinge on model outputs. The capacity to separate out-of-distribution (OOD) samples has proven to be a valuable indicator of a model's reliability in research. In medical imaging, this is especially critical, as identifying OOD inputs can help flag potential anomalies that might otherwise go undetected. While many OOD detection methods rely on feature or logit space representations, recent works suggest these approaches may not fully capture OOD diversity. To address this, we propose a novel OOD scoring mechanism, called NERO, that leverages neuron-level relevance at the feature layer. Specifically, we cluster neuron-level relevance for each in-distribution (ID) class to form representative centroids and introduce a relevance distance metric to quantify a new sample's deviation from these centroids, enhancing OOD separability. Additionally, we refine performance by incorporating scaled relevance in the bias term and combining feature norms. Our framework also enables explainable OOD detection. We validate its effectiveness across multiple deep learning architectures on the gastrointestinal imaging benchmarks Kvasir and GastroVision, achieving improvements over state-of-the-art OOD detection methods.
Federated Foundation Model for GI Endoscopy Images
May 30, 2025



Gastrointestinal (GI) endoscopy is essential in identifying GI tract abnormalities in order to detect diseases in their early stages and improve patient outcomes. Although deep learning has shown success in supporting GI diagnostics and decision-making, these models require curated datasets with labels that are expensive to acquire. Foundation models offer a promising solution by learning general-purpose representations, which can be finetuned for specific tasks, overcoming data scarcity. Developing foundation models for medical imaging holds significant potential, but the sensitive and protected nature of medical data presents unique challenges. Foundation model training typically requires extensive datasets, and while hospitals generate large volumes of data, privacy restrictions prevent direct data sharing, making foundation model training infeasible in most scenarios. In this work, we propose a FL framework for training foundation models for gastroendoscopy imaging, enabling data to remain within local hospital environments while contributing to a shared model. We explore several established FL algorithms, assessing their suitability for training foundation models without relying on task-specific labels, conducting experiments in both homogeneous and heterogeneous settings. We evaluate the trained foundation model on three critical downstream tasks--classification, detection, and segmentation--and demonstrate that it achieves improved performance across all tasks, highlighting the effectiveness of our approach in a federated, privacy-preserving setting.