 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Autonomous Navigation in Endovascular Interventions
Dec 23, 2025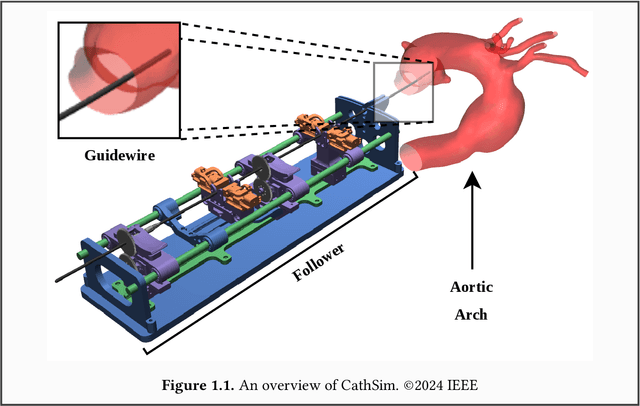
Cardiovascular diseases remain the leading cause of global mortality, with minimally invasive treatment options offered through endovascular interventions. However, the precision and adaptability of current robotic systems for endovascular navigation are limited by heuristic control, low autonomy, and the absence of haptic feedback. This thesis presents an integrated AI-driven framework for autonomous guidewire navigation in complex vascular environments, addressing key challenges in data availability, simulation fidelity, and navigational accuracy. A high-fidelity, real-time simulation platform, CathSim, is introduced for reinforcement learning based catheter navigation, featuring anatomically accurate vascular models and contact dynamics. Building on CathSim, the Expert Navigation Network is developed, a policy that fuses visual, kinematic, and force feedback for autonomous tool control. To mitigate data scarcity, the open-source, bi-planar fluoroscopic dataset Guide3D is proposed, comprising more than 8,700 annotated images for 3D guidewire reconstruction. Finally, SplineFormer, a transformer-based model, is introduced to directly predict guidewire geometry as continuous B-spline parameters, enabling interpretable, real-time navigation. The findings show that combining high-fidelity simulation, multimodal sensory fusion, and geometric modelling substantially improves autonomous endovascular navigation and supports safer, more precise minimally invasive procedures.
FedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025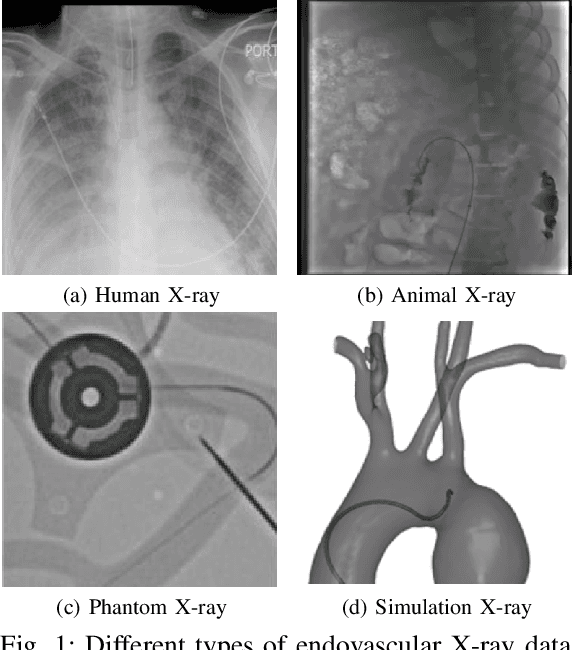
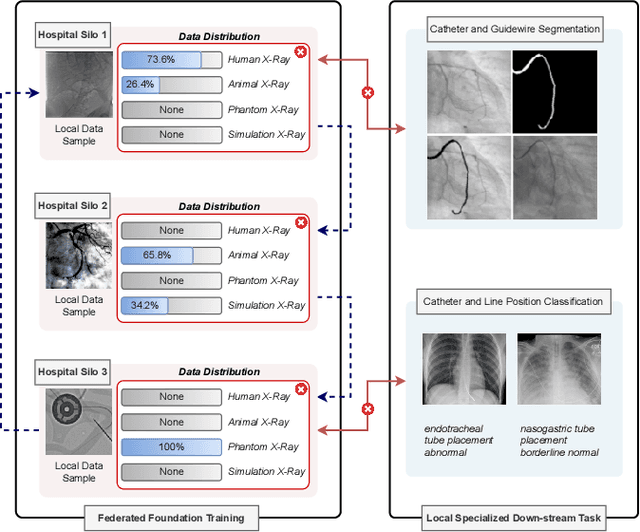

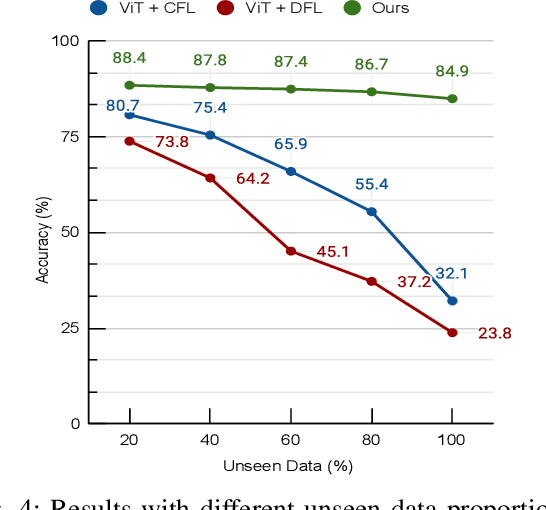
In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.
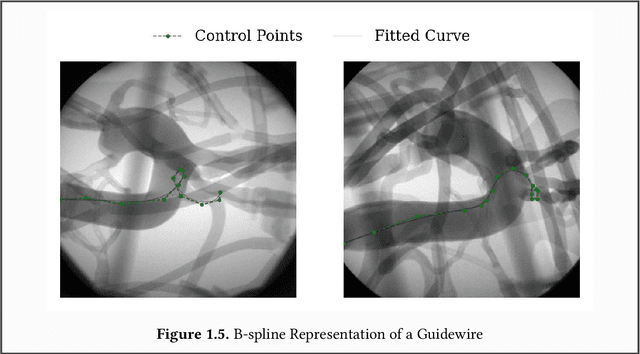
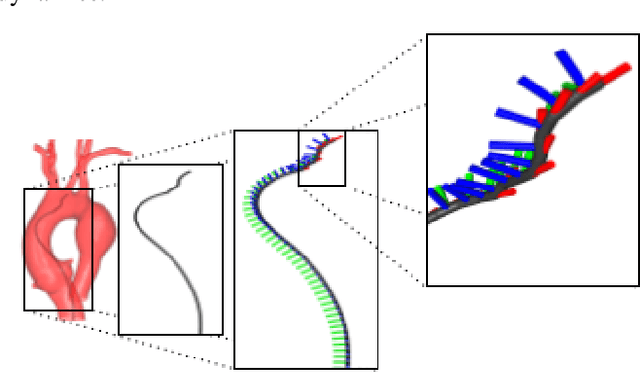
SplineFormer: An Explainable Transformer-Based Approach for Autonomous Endovascular Navigation
Jan 08, 2025


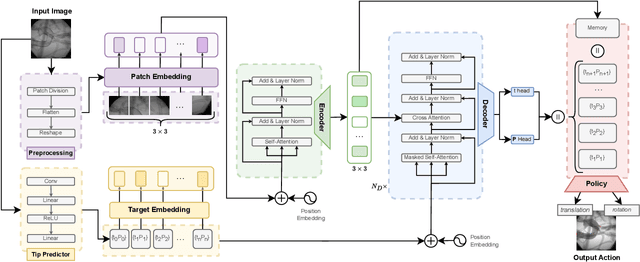
Endovascular navigation is a crucial aspect of minimally invasive procedures, where precise control of curvilinear instruments like guidewires is critical for successful interventions. A key challenge in this task is accurately predicting the evolving shape of the guidewire as it navigates through the vasculature, which presents complex deformations due to interactions with the vessel walls. Traditional segmentation methods often fail to provide accurate real-time shape predictions, limiting their effectiveness in highly dynamic environments. To address this, we propose SplineFormer, a new transformer-based architecture, designed specifically to predict the continuous, smooth shape of the guidewire in an explainable way. By leveraging the transformer's ability, our network effectively captures the intricate bending and twisting of the guidewire, representing it as a spline for greater accuracy and smoothness. We integrate our SplineFormer into an end-to-end robot navigation system by leveraging the condensed information. The experimental results demonstrate that our SplineFormer is able to perform endovascular navigation autonomously and achieves a 50% success rate when cannulating the brachiocephalic artery on the real robot.
Guide3D: A Bi-planar X-ray Dataset for 3D Shape Reconstruction
Oct 29, 2024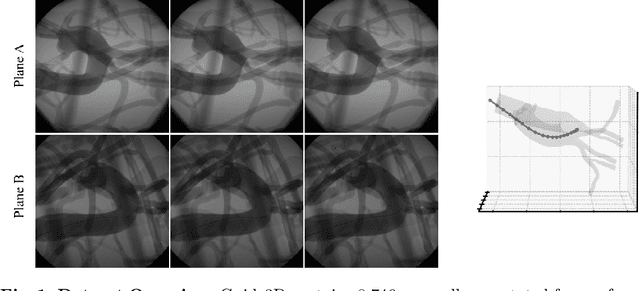
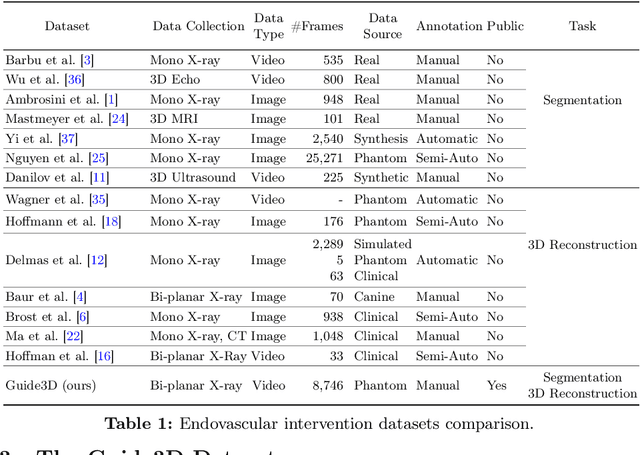

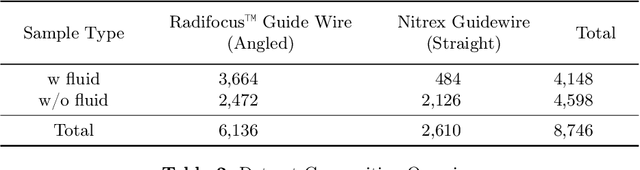
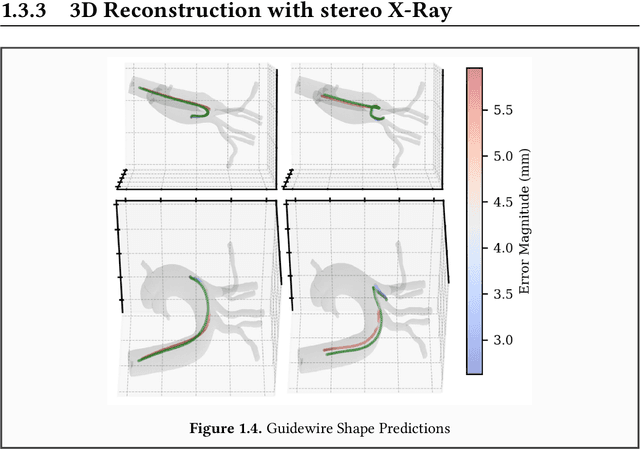
Endovascular surgical tool reconstruction represents an important factor in advancing endovascular tool navigation, which is an important step in endovascular surgery. However, the lack of publicly available datasets significantly restricts the development and validation of novel machine learning approaches. Moreover, due to the need for specialized equipment such as biplanar scanners, most of the previous research employs monoplanar fluoroscopic technologies, hence only capturing the data from a single view and significantly limiting the reconstruction accuracy. To bridge this gap, we introduce Guide3D, a bi-planar X-ray dataset for 3D reconstruction. The dataset represents a collection of high resolution bi-planar, manually annotated fluoroscopic videos, captured in real-world settings. Validating our dataset within a simulated environment reflective of clinical settings confirms its applicability for real-world applications. Furthermore, we propose a new benchmark for guidewrite shape prediction, serving as a strong baseline for future work. Guide3D not only addresses an essential need by offering a platform for advancing segmentation and 3D reconstruction techniques but also aids the development of more accurate and efficient endovascular surgery interventions. Our project is available at https://airvlab.github.io/guide3d/.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
Autonomous Catheterization with Open-source Simulator and Expert Trajectory
Jan 20, 2024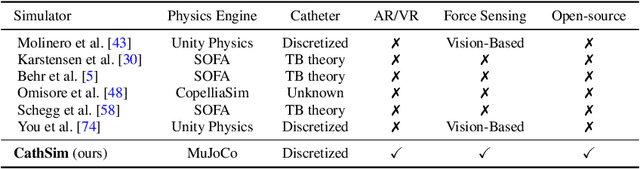
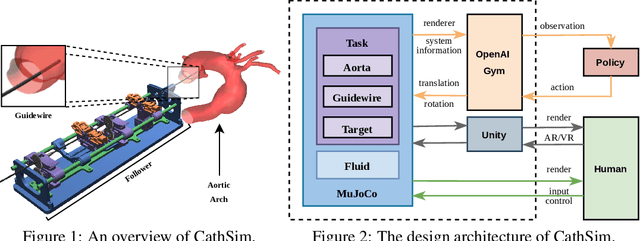
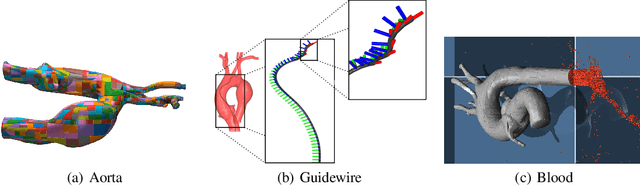
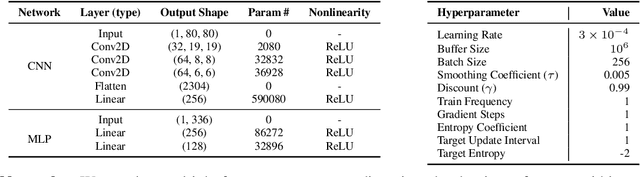
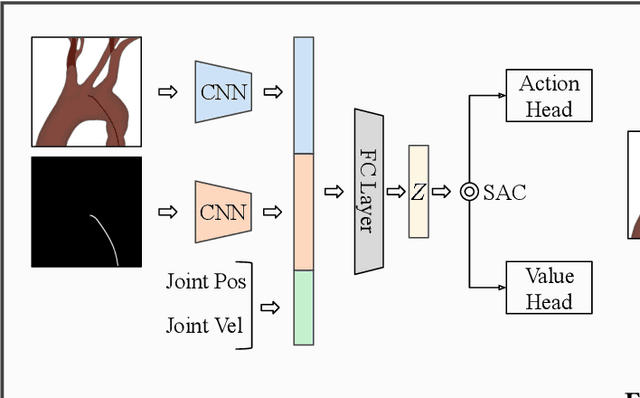
Endovascular robots have been actively developed in both academia and industry. However, progress toward autonomous catheterization is often hampered by the widespread use of closed-source simulators and physical phantoms. Additionally, the acquisition of large-scale datasets for training machine learning algorithms with endovascular robots is usually infeasible due to expensive medical procedures. In this chapter, we introduce CathSim, the first open-source simulator for endovascular intervention to address these limitations. CathSim emphasizes real-time performance to enable rapid development and testing of learning algorithms. We validate CathSim against the real robot and show that our simulator can successfully mimic the behavior of the real robot. Based on CathSim, we develop a multimodal expert navigation network and demonstrate its effectiveness in downstream endovascular navigation tasks. The intensive experimental results suggest that CathSim has the potential to significantly accelerate research in the autonomous catheterization field. Our project is publicly available at https://github.com/airvlab/cathsim.
3D Guidewire Shape Reconstruction from Monoplane Fluoroscopic Images
Nov 19, 2023


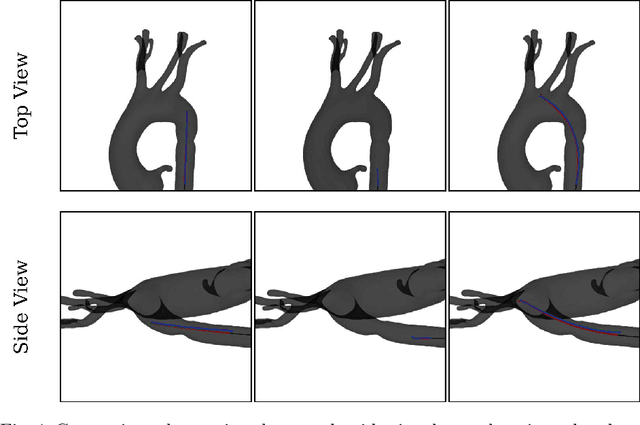
Endovascular navigation, essential for diagnosing and treating endovascular diseases, predominantly hinges on fluoroscopic images due to the constraints in sensory feedback. Current shape reconstruction techniques for endovascular intervention often rely on either a priori information or specialized equipment, potentially subjecting patients to heightened radiation exposure. While deep learning holds potential, it typically demands extensive data. In this paper, we propose a new method to reconstruct the 3D guidewire by utilizing CathSim, a state-of-the-art endovascular simulator, and a 3D Fluoroscopy Guidewire Reconstruction Network (3D-FGRN). Our 3D-FGRN delivers results on par with conventional triangulation from simulated monoplane fluoroscopic images. Our experiments accentuate the efficiency of the proposed network, demonstrating it as a promising alternative to traditional methods.
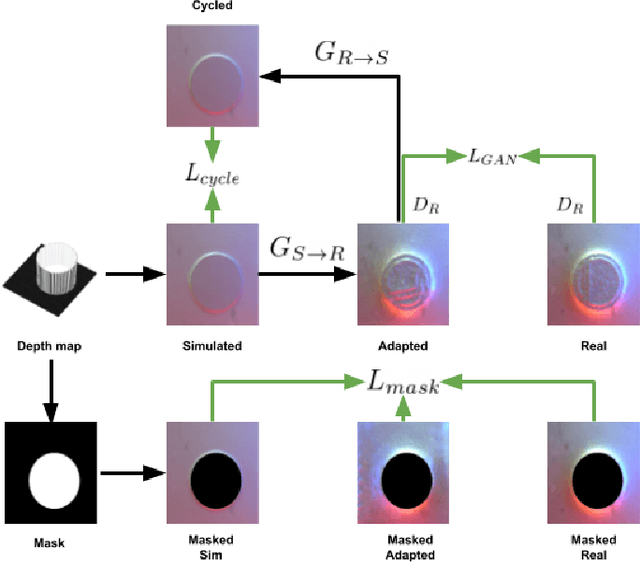
Translating Simulation Images to X-ray Images via Multi-Scale Semantic Matching
Apr 16, 2023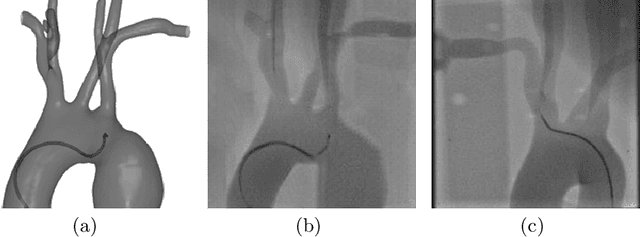
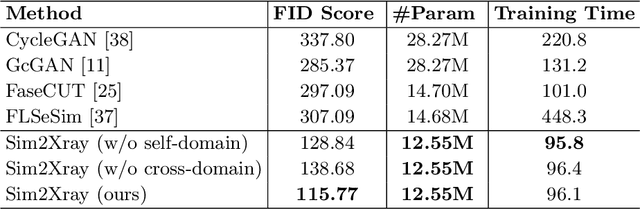
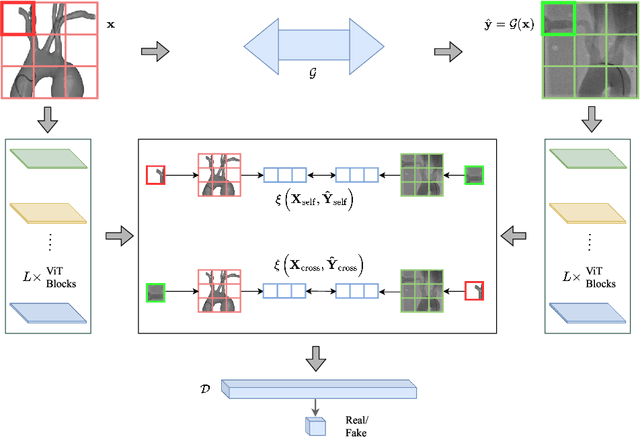
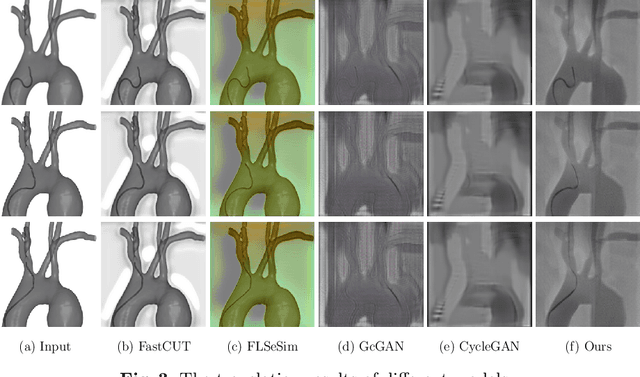
Endovascular intervention training is increasingly being conducted in virtual simulators. However, transferring the experience from endovascular simulators to the real world remains an open problem. The key challenge is the virtual environments are usually not realistically simulated, especially the simulation images. In this paper, we propose a new method to translate simulation images from an endovascular simulator to X-ray images. Previous image-to-image translation methods often focus on visual effects and neglect structure information, which is critical for medical images. To address this gap, we propose a new method that utilizes multi-scale semantic matching. We apply self-domain semantic matching to ensure that the input image and the generated image have the same positional semantic relationships. We further apply cross-domain matching to eliminate the effects of different styles. The intensive experiment shows that our method generates realistic X-ray images and outperforms other state-of-the-art approaches by a large margin. We also collect a new large-scale dataset to serve as the new benchmark for this task. Our source code and dataset will be made publicly available.
CathSim: An Open-source Simulator for Autonomous Cannulation
Aug 02, 2022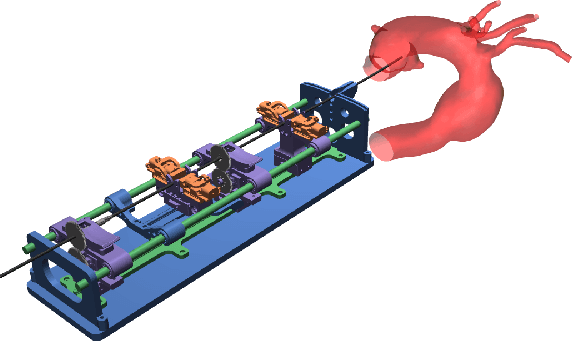
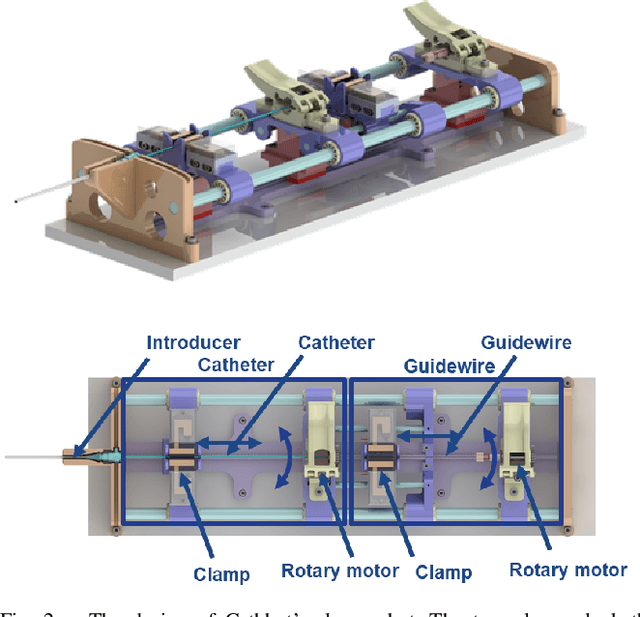

Autonomous robots in endovascular operations have the potential to navigate circulatory systems safely and reliably while decreasing the susceptibility to human errors. However, there are numerous challenges involved with the process of training such robots such as long training duration due to sample inefficiency of machine learning algorithms and safety issues arising from the interaction between the catheter and the endovascular phantom. Physics simulators have been used in the context of endovascular procedures, but they are typically employed for staff training and generally do not conform to the autonomous cannulation goal. Furthermore, most current simulators are closed-source which hinders the collaborative development of safe and reliable autonomous systems. In this work, we introduce CathSim, an open-source simulation environment that accelerates the development of machine learning algorithms for autonomous endovascular navigation. We first simulate the high-fidelity catheter and aorta with the state-of-the-art endovascular robot. We then provide the capability of real-time force sensing between the catheter and the aorta in the simulation environment. We validate our simulator by conducting two different catheterisation tasks within two primary arteries using two popular reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC). The experimental results show that using our open-source simulator, we can successfully train the reinforcement learning agents to perform different autonomous cannulation tasks.
Reducing Tactile Sim2Real Domain Gaps via Deep Texture Generation Networks
Dec 03, 2021


Recently simulation methods have been developed for optical tactile sensors to enable the Sim2Real learning, i.e., firstly training models in simulation before deploying them on the real robot. However, some artefacts in the real objects are unpredictable, such as imperfections caused by fabrication processes, or scratches by the natural wear and tear, and thus cannot be represented in the simulation, resulting in a significant gap between the simulated and real tactile images. To address this Sim2Real gap, we propose a novel texture generation network that maps the simulated images into photorealistic tactile images that resemble a real sensor contacting a real imperfect object. Each simulated tactile image is first divided into two types of regions: areas that are in contact with the object and areas that are not. The former is applied with generated textures learned from real textures in the real tactile images, whereas the latter maintains its appearance as when the sensor is not in contact with any object. This makes sure that the artefacts are only applied to the deformed regions of the sensor. Our extensive experiments show that the proposed texture generation network can generate these realistic artefacts on the deformed regions of the sensor, while avoiding leaking the textures into areas of no contact. Quantitative experiments further reveal that when using the adapted images generated by our proposed network for a Sim2Real classification task, the drop in accuracy caused by the Sim2Real gap is reduced from 38.43% to merely 0.81%. As such, this work has the potential to accelerate the Sim2Real learning for robotic tasks requiring tactile sensing.