 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Vision-Language-Action Models Requires Fewer Layers Than You Think
Jun 18, 2026Vision-Language-Action (VLA) models pre-trained on massive video-robot datasets have revolutionized robotic manipulation, yet their multi-billion parameter architectures impose prohibitive computational burdens during downstream fine-tuning and real-time inference. In this work, we reveal a highly non-trivial architectural characteristic of these continuous control foundation policies (e.g., pi_0, GR00T-N1.5): despite being trained on diverse physical trajectories, they exhibit severe layer-wise representational redundancy. To exploit this, we introduce a structural compression pipeline that is entirely training-free, bypassing the need of existing methods to load full-scale models to learn optimized token reductions or dynamic layer selectors. Instead, using only a single forward pass via Centered Kernel Alignment to identify redundant layer features, we remove twin layers to permanently compress the model depth by up to 50% across both the VLM backbone and the continuous control policy head. Downstream fine-tuning of this streamlined architecture yields a dual acceleration benefit: a 40-50% reduction in training time and up to 30% faster real-time inference, while matching or exceeding full-scale base model performance. We comprehensively validate our method across three simulation benchmarks (LIBERO, RoboCasa, SimplerEnv) and 10 diverse real-world manipulation tasks across 4 unique robotic embodiments. These results prove that advanced VLAs require significantly fewer layers than previously assumed, offering a highly compute-efficient paradigm for scalable robot learning.
CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
Apr 24, 2026Vision-Language-Action (VLA) models promise generalist robot manipulation, but are typically trained and deployed as short-horizon policies that assume the latest observation is sufficient for action reasoning. This assumption breaks in non-Markovian long-horizon tasks, where task-relevant evidence can be occluded or appear only earlier in the trajectory, and where clutter and distractors make fine-grained visual grounding brittle. We present CodeGraphVLP, a hierarchical framework that enables reliable long-horizon manipulation by combining a persistent semantic-graph state with an executable code-based planner and progress-guided visual-language prompting. The semantic-graph maintains task-relevant entities and relations under partial observability. The synthesized planner executes over this semantic-graph to perform efficient progress checks and outputs a subtask instruction together with subtask-relevant objects. We use these outputs to construct clutter-suppressed observations that focus the VLA executor on critical evidence. On real-world non-Markovian tasks, CodeGraphVLP improves task completion over strong VLA baselines and history-enabled variants while substantially lowering planning latency compared to VLM-in-the-loop planning. We also conduct extensive ablation studies to confirm the contributions of each component.
Mutual Information Collapse Explains Disentanglement Failure in $β$-VAEs
Feb 09, 2026The $β$-VAE is a foundational framework for unsupervised disentanglement, using $β$ to regulate the trade-off between latent factorization and reconstruction fidelity. Empirically, however, disentanglement performance exhibits a pervasive non-monotonic trend: benchmarks such as MIG and SAP typically peak at intermediate $β$ and collapse as regularization increases. We demonstrate that this collapse is a fundamental information-theoretic failure, where strong Kullback-Leibler pressure promotes marginal independence at the expense of the latent channel's semantic informativeness. By formalizing this mechanism in a linear-Gaussian setting, we prove that for $β> 1$, stationarity-induced dynamics trigger a spectral contraction of the encoder gain, driving latent-factor mutual information to zero. To resolve this, we introduce the $λβ$-VAE, which decouples regularization pressure from informational collapse via an auxiliary $L_2$ reconstruction penalty $λ$. Extensive experiments on dSprites, Shapes3D, and MPI3D-real confirm that $λ> 0$ stabilizes disentanglement and restores latent informativeness over a significantly broader range of $β$, providing a principled theoretical justification for dual-parameter regularization in variational inference backbones.
Gaussian-Mixture-Model Q-Functions for Policy Iteration in Reinforcement Learning
Dec 21, 2025Unlike their conventional use as estimators of probability density functions in reinforcement learning (RL), this paper introduces a novel function-approximation role for Gaussian mixture models (GMMs) as direct surrogates for Q-function losses. These parametric models, termed GMM-QFs, possess substantial representational capacity, as they are shown to be universal approximators over a broad class of functions. They are further embedded within Bellman residuals, where their learnable parameters -- a fixed number of mixing weights, together with Gaussian mean vectors and covariance matrices -- are inferred from data via optimization on a Riemannian manifold. This geometric perspective on the parameter space naturally incorporates Riemannian optimization into the policy-evaluation step of standard policy-iteration frameworks. Rigorous theoretical results are established, and supporting numerical tests show that, even without access to experience data, GMM-QFs deliver competitive performance and, in some cases, outperform state-of-the-art approaches across a range of benchmark RL tasks, all while maintaining a significantly smaller computational footprint than deep-learning methods that rely on experience data.
Scientific Data Compression and Super-Resolution Sampling
Nov 17, 2025Modern scientific simulations, observations, and large-scale experiments generate data at volumes that often exceed the limits of storage, processing, and analysis. This challenge drives the development of data reduction methods that efficiently manage massive datasets while preserving essential physical features and quantities of interest. In many scientific workflows, it is also crucial to enable data recovery from compressed representations - a task known as super-resolution - with guarantees on the preservation of key physical characteristics. A notable example is checkpointing and restarting, which is essential for long-running simulations to recover from failures, resume after interruptions, or examine intermediate results. In this work, we introduce a novel framework for scientific data compression and super-resolution, grounded in recent advances in learning exponential families. Our method preserves and quantifies uncertainty in physical quantities of interest and supports flexible trade-offs between compression ratio and reconstruction fidelity.
PAS : Prelim Attention Score for Detecting Object Hallucinations in Large Vision--Language Models
Nov 14, 2025Large vision-language models (LVLMs) are powerful, yet they remain unreliable due to object hallucinations. In this work, we show that in many hallucinatory predictions the LVLM effectively ignores the image and instead relies on previously generated output (prelim) tokens to infer new objects. We quantify this behavior via the mutual information between the image and the predicted object conditioned on the prelim, demonstrating that weak image dependence strongly correlates with hallucination. Building on this finding, we introduce the Prelim Attention Score (PAS), a lightweight, training-free signal computed from attention weights over prelim tokens. PAS requires no additional forward passes and can be computed on the fly during inference. Exploiting this previously overlooked signal, PAS achieves state-of-the-art object-hallucination detection across multiple models and datasets, enabling real-time filtering and intervention.
Online reinforcement learning via sparse Gaussian mixture model Q-functions
Sep 18, 2025This paper introduces a structured and interpretable online policy-iteration framework for reinforcement learning (RL), built around the novel class of sparse Gaussian mixture model Q-functions (S-GMM-QFs). Extending earlier work that trained GMM-QFs offline, the proposed framework develops an online scheme that leverages streaming data to encourage exploration. Model complexity is regulated through sparsification by Hadamard overparametrization, which mitigates overfitting while preserving expressiveness. The parameter space of S-GMM-QFs is naturally endowed with a Riemannian manifold structure, allowing for principled parameter updates via online gradient descent on a smooth objective. Numerical tests show that S-GMM-QFs match the performance of dense deep RL (DeepRL) methods on standard benchmarks while using significantly fewer parameters, and maintain strong performance even in low-parameter-count regimes where sparsified DeepRL methods fail to generalize.
Diverging Towards Hallucination: Detection of Failures in Vision-Language Models via Multi-token Aggregation
May 16, 2025



Vision-language models (VLMs) now rival human performance on many multimodal tasks, yet they still hallucinate objects or generate unsafe text. Current hallucination detectors, e.g., single-token linear probing (SLP) and P(True), typically analyze only the logit of the first generated token or just its highest scoring component overlooking richer signals embedded within earlier token distributions. We demonstrate that analyzing the complete sequence of early logits potentially provides substantially more diagnostic information. We emphasize that hallucinations may only emerge after several tokens, as subtle inconsistencies accumulate over time. By analyzing the Kullback-Leibler (KL) divergence between logits corresponding to hallucinated and non-hallucinated tokens, we underscore the importance of incorporating later-token logits to more accurately capture the reliability dynamics of VLMs. In response, we introduce Multi-Token Reliability Estimation (MTRE), a lightweight, white-box method that aggregates logits from the first ten tokens using multi-token log-likelihood ratios and self-attention. Despite the challenges posed by large vocabulary sizes and long logit sequences, MTRE remains efficient and tractable. On MAD-Bench, MM-SafetyBench, MathVista, and four compositional-geometry benchmarks, MTRE improves AUROC by 9.4 +/- 1.3 points over SLP and by 12.1 +/- 1.7 points over P(True), setting a new state-of-the-art in hallucination detection for open-source VLMs.
Topological Signatures of Adversaries in Multimodal Alignments
Jan 29, 2025Multimodal Machine Learning systems, particularly those aligning text and image data like CLIP/BLIP models, have become increasingly prevalent, yet remain susceptible to adversarial attacks. While substantial research has addressed adversarial robustness in unimodal contexts, defense strategies for multimodal systems are underexplored. This work investigates the topological signatures that arise between image and text embeddings and shows how adversarial attacks disrupt their alignment, introducing distinctive signatures. We specifically leverage persistent homology and introduce two novel Topological-Contrastive losses based on Total Persistence and Multi-scale kernel methods to analyze the topological signatures introduced by adversarial perturbations. We observe a pattern of monotonic changes in the proposed topological losses emerging in a wide range of attacks on image-text alignments, as more adversarial samples are introduced in the data. By designing an algorithm to back-propagate these signatures to input samples, we are able to integrate these signatures into Maximum Mean Discrepancy tests, creating a novel class of tests that leverage topological signatures for better adversarial detection.
FedEFM: Federated Endovascular Foundation Model with Unseen Data
Jan 28, 2025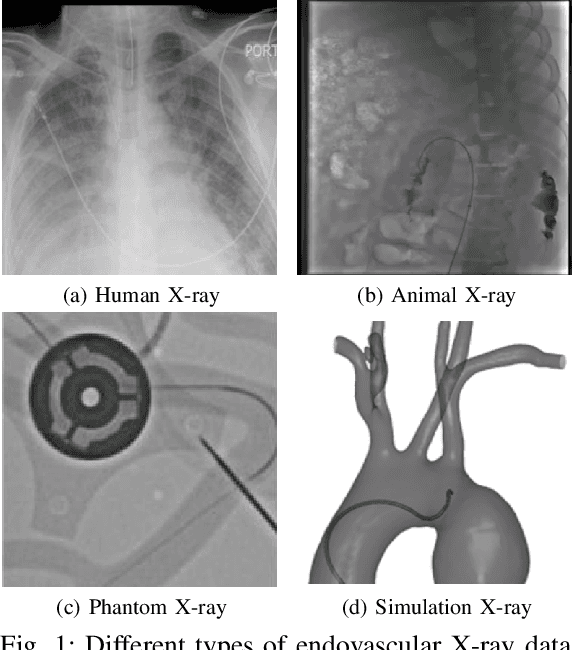
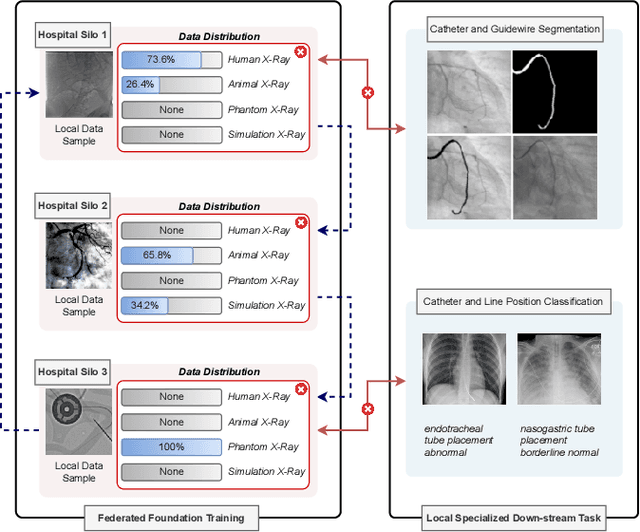

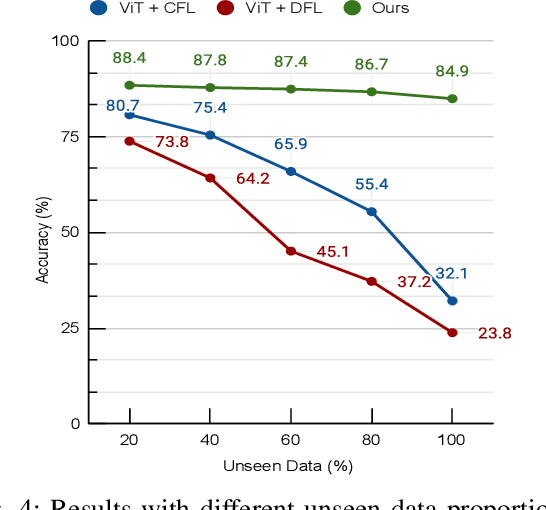
In endovascular surgery, the precise identification of catheters and guidewires in X-ray images is essential for reducing intervention risks. However, accurately segmenting catheter and guidewire structures is challenging due to the limited availability of labeled data. Foundation models offer a promising solution by enabling the collection of similar domain data to train models whose weights can be fine-tuned for downstream tasks. Nonetheless, large-scale data collection for training is constrained by the necessity of maintaining patient privacy. This paper proposes a new method to train a foundation model in a decentralized federated learning setting for endovascular intervention. To ensure the feasibility of the training, we tackle the unseen data issue using differentiable Earth Mover's Distance within a knowledge distillation framework. Once trained, our foundation model's weights provide valuable initialization for downstream tasks, thereby enhancing task-specific performance. Intensive experiments show that our approach achieves new state-of-the-art results, contributing to advancements in endovascular intervention and robotic-assisted endovascular surgery, while addressing the critical issue of data sharing in the medical domain.