 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchfinder: Leveraging Visual Language Models for Accurate Information Retrieval using Model Uncertainty
Dec 03, 2024For decades, corporations and governments have relied on scanned documents to record vast amounts of information. However, extracting this information is a slow and tedious process due to the overwhelming amount of documents. The rise of vision language models presents a way to efficiently and accurately extract the information out of these documents. The current automated workflow often requires a two-step approach involving the extraction of information using optical character recognition software, and subsequent usage of large language models for processing this information. Unfortunately, these methods encounter significant challenges when dealing with noisy scanned documents. The high information density of such documents often necessitates using computationally expensive language models to effectively reduce noise. In this study, we propose PatchFinder, an algorithm that builds upon Vision Language Models (VLMs) to address the information extraction task. First, we devise a confidence-based score, called Patch Confidence, based on the Maximum Softmax Probability of the VLMs' output to measure the model's confidence in its predictions. Then, PatchFinder utilizes that score to determine a suitable patch size, partition the input document into overlapping patches of that size, and generate confidence-based predictions for the target information. Our experimental results show that PatchFinder can leverage Phi-3v, a 4.2 billion parameter vision language model, to achieve an accuracy of 94% on our dataset of 190 noisy scanned documents, surpassing the performance of ChatGPT-4o by 18.5 percentage points.
Information Extraction from Historical Well Records Using A Large Language Model
May 08, 2024To reduce environmental risks and impacts from orphaned wells (abandoned oil and gas wells), it is essential to first locate and then plug these wells. Although some historical documents are available, they are often unstructured, not cleaned, and outdated. Additionally, they vary widely by state and type. Manual reading and digitizing this information from historical documents are not feasible, given the high number of wells. Here, we propose a new computational approach for rapidly and cost-effectively locating these wells. Specifically, we leverage the advanced capabilities of large language models (LLMs) to extract vital information including well location and depth from historical records of orphaned wells. In this paper, we present an information extraction workflow based on open-source Llama 2 models and test them on a dataset of 160 well documents. Our results show that the developed workflow achieves excellent accuracy in extracting location and depth from clean, PDF-based reports, with a 100% accuracy rate. However, it struggles with unstructured image-based well records, where accuracy drops to 70%. The workflow provides significant benefits over manual human digitization, including reduced labor and increased automation. In general, more detailed prompting leads to improved information extraction, and those LLMs with more parameters typically perform better. We provided a detailed discussion of the current challenges and the corresponding opportunities/approaches to address them. Additionally, a vast amount of geoscientific information is locked up in old documents, and this work demonstrates that recent breakthroughs in LLMs enable us to unlock this information more broadly.
Learning the Factors Controlling Mineralization for Geologic Carbon Sequestration
Dec 20, 2023We perform a set of flow and reactive transport simulations within three-dimensional fracture networks to learn the factors controlling mineral reactions. CO$_2$ mineralization requires CO$_2$-laden water, dissolution of a mineral that then leads to precipitation of a CO$_2$-bearing mineral. Our discrete fracture networks (DFN) are partially filled with quartz that gradually dissolves until it reaches a quasi-steady state. At the end of the simulation, we measure the quartz remaining in each fracture within the domain. We observe that a small backbone of fracture exists, where the quartz is fully dissolved which leads to increased flow and transport. However, depending on the DFN topology and the rate of dissolution, we observe a large variability of these changes, which indicates an interplay between the fracture network structure and the impact of geochemical dissolution. In this work, we developed a machine learning framework to extract the important features that support mineralization in the form of dissolution. In addition, we use structural and topological features of the fracture network to predict the remaining quartz volume in quasi-steady state conditions. As a first step to characterizing carbon mineralization, we study dissolution with this framework. We studied a variety of reaction and fracture parameters and their impact on the dissolution of quartz in fracture networks. We found that the dissolution reaction rate constant of quartz and the distance to the flowing backbone in the fracture network are the two most important features that control the amount of quartz left in the system. For the first time, we use a combination of a finite-volume reservoir model and graph-based approach to study reactive transport in a complex fracture network to determine the key features that control dissolution.
Reconstruction of Fields from Sparse Sensing: Differentiable Sensor Placement Enhances Generalization
Dec 14, 2023



Recreating complex, high-dimensional global fields from limited data points is a grand challenge across various scientific and industrial domains. Given the prohibitive costs of specialized sensors and the frequent inaccessibility of certain regions of the domain, achieving full field coverage is typically not feasible. Therefore, the development of algorithms that intelligently improve sensor placement is of significant value. In this study, we introduce a general approach that employs differentiable programming to exploit sensor placement within the training of a neural network model in order to improve field reconstruction. We evaluated our method using two distinct datasets; the results show that our approach improved test scores. Ultimately, our method of differentiable placement strategies has the potential to significantly increase data collection efficiency, enable more thorough area coverage, and reduce redundancy in sensor deployment.
Physics-informed machine learning with differentiable programming for heterogeneous underground reservoir pressure management
Jun 21, 2022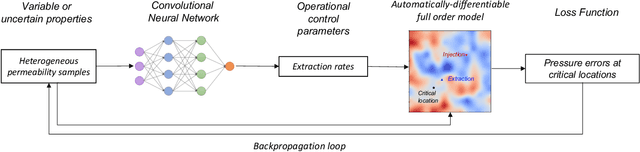

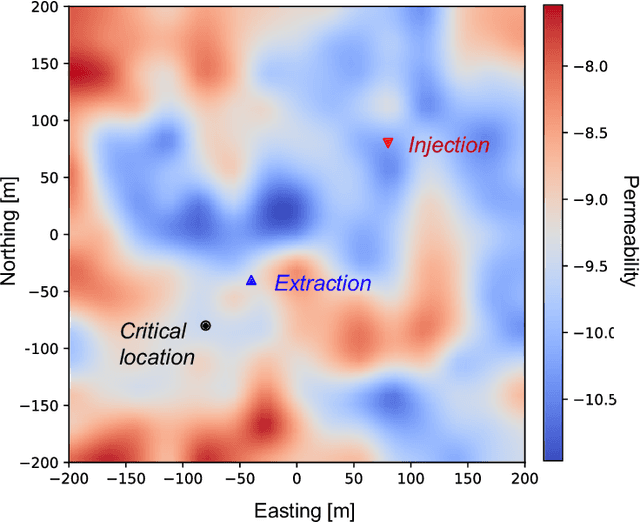
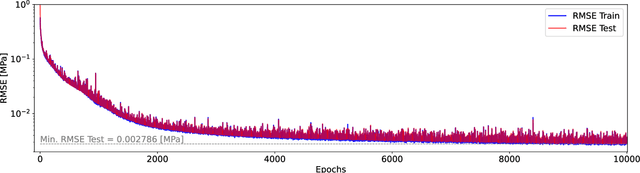
Avoiding over-pressurization in subsurface reservoirs is critical for applications like CO2 sequestration and wastewater injection. Managing the pressures by controlling injection/extraction are challenging because of complex heterogeneity in the subsurface. The heterogeneity typically requires high-fidelity physics-based models to make predictions on CO$_2$ fate. Furthermore, characterizing the heterogeneity accurately is fraught with parametric uncertainty. Accounting for both, heterogeneity and uncertainty, makes this a computationally-intensive problem challenging for current reservoir simulators. To tackle this, we use differentiable programming with a full-physics model and machine learning to determine the fluid extraction rates that prevent over-pressurization at critical reservoir locations. We use DPFEHM framework, which has trustworthy physics based on the standard two-point flux finite volume discretization and is also automatically differentiable like machine learning models. Our physics-informed machine learning framework uses convolutional neural networks to learn an appropriate extraction rate based on the permeability field. We also perform a hyperparameter search to improve the model's accuracy. Training and testing scenarios are executed to evaluate the feasibility of using physics-informed machine learning to manage reservoir pressures. We constructed and tested a sufficiently accurate simulator that is 400000 times faster than the underlying physics-based simulator, allowing for near real-time analysis and robust uncertainty quantification.
Machine Learning in Heterogeneous Porous Materials
Feb 04, 2022

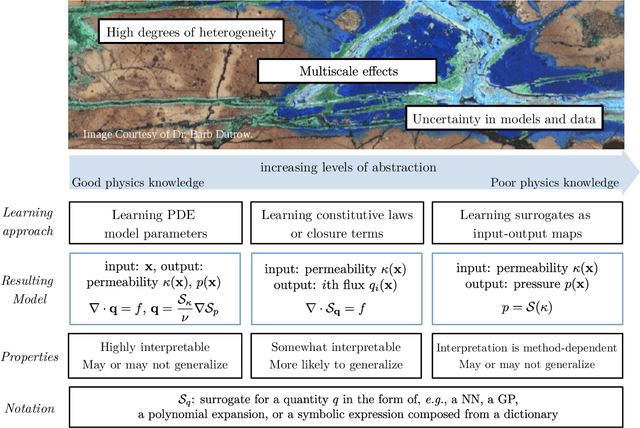
The "Workshop on Machine learning in heterogeneous porous materials" brought together international scientific communities of applied mathematics, porous media, and material sciences with experts in the areas of heterogeneous materials, machine learning (ML) and applied mathematics to identify how ML can advance materials research. Within the scope of ML and materials research, the goal of the workshop was to discuss the state-of-the-art in each community, promote crosstalk and accelerate multi-disciplinary collaborative research, and identify challenges and opportunities. As the end result, four topic areas were identified: ML in predicting materials properties, and discovery and design of novel materials, ML in porous and fractured media and time-dependent phenomena, Multi-scale modeling in heterogeneous porous materials via ML, and Discovery of materials constitutive laws and new governing equations. This workshop was part of the AmeriMech Symposium series sponsored by the National Academies of Sciences, Engineering and Medicine and the U.S. National Committee on Theoretical and Applied Mechanics.
Multi-Scale Neural Networks for to Fluid Flow in 3D Porous Media
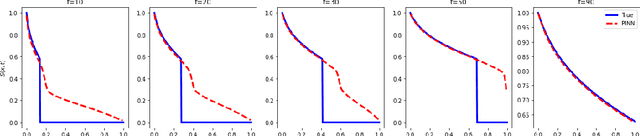
Feb 10, 2021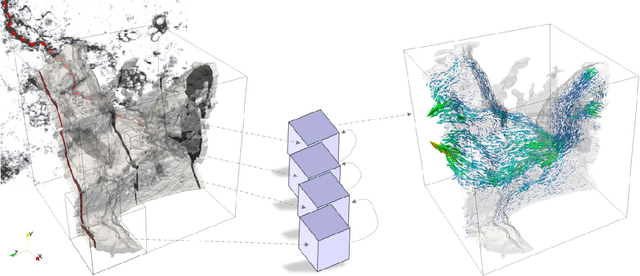
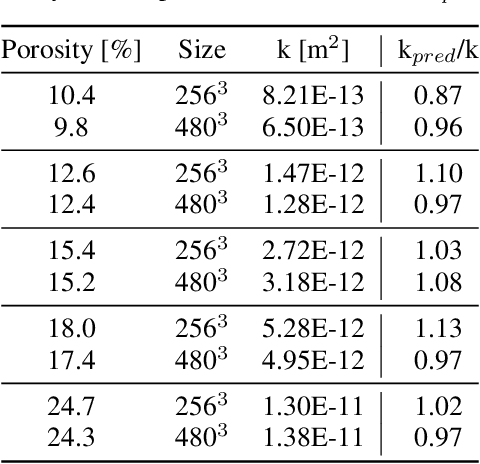
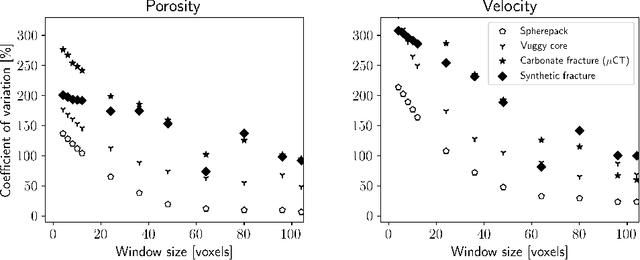
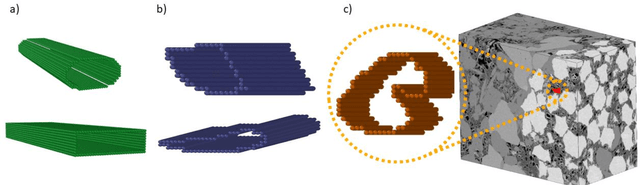
The permeability of complex porous materials can be obtained via direct flow simulation, which provides the most accurate results, but is very computationally expensive. In particular, the simulation convergence time scales poorly as simulation domains become tighter or more heterogeneous. Semi-analytical models that rely on averaged structural properties (i.e. porosity and tortuosity) have been proposed, but these features only summarize the domain, resulting in limited applicability. On the other hand, data-driven machine learning approaches have shown great promise for building more general models by virtue of accounting for the spatial arrangement of the domains solid boundaries. However, prior approaches building on the Convolutional Neural Network (ConvNet) literature concerning 2D image recognition problems do not scale well to the large 3D domains required to obtain a Representative Elementary Volume (REV). As such, most prior work focused on homogeneous samples, where a small REV entails that that the global nature of fluid flow could be mostly neglected, and accordingly, the memory bottleneck of addressing 3D domains with ConvNets was side-stepped. Therefore, important geometries such as fractures and vuggy domains could not be well-modeled. In this work, we address this limitation with a general multiscale deep learning model that is able to learn from porous media simulation data. By using a coupled set of neural networks that view the domain on different scales, we enable the evaluation of large images in approximately one second on a single Graphics Processing Unit. This model architecture opens up the possibility of modeling domain sizes that would not be feasible using traditional direct simulation tools on a desktop computer.
Modeling nanoconfinement effects using active learning
May 07, 2020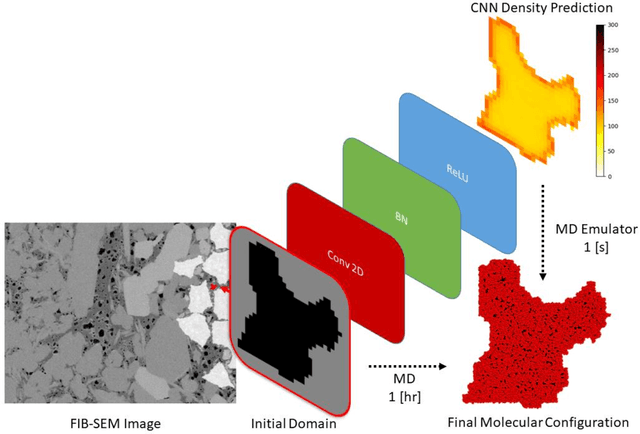


Predicting the spatial configuration of gas molecules in nanopores of shale formations is crucial for fluid flow forecasting and hydrocarbon reserves estimation. The key challenge in these tight formations is that the majority of the pore sizes are less than 50 nm. At this scale, the fluid properties are affected by nanoconfinement effects due to the increased fluid-solid interactions. For instance, gas adsorption to the pore walls could account for up to 85% of the total hydrocarbon volume in a tight reservoir. Although there are analytical solutions that describe this phenomenon for simple geometries, they are not suitable for describing realistic pores, where surface roughness and geometric anisotropy play important roles. To describe these, molecular dynamics (MD) simulations are used since they consider fluid-solid and fluid-fluid interactions at the molecular level. However, MD simulations are computationally expensive, and are not able to simulate scales larger than a few connected nanopores. We present a method for building and training physics-based deep learning surrogate models to carry out fast and accurate predictions of molecular configurations of gas inside nanopores. Since training deep learning models requires extensive databases that are computationally expensive to create, we employ active learning (AL). AL reduces the overhead of creating comprehensive sets of high-fidelity data by determining where the model uncertainty is greatest, and running simulations on the fly to minimize it. The proposed workflow enables nanoconfinement effects to be rigorously considered at the mesoscale where complex connected sets of nanopores control key applications such as hydrocarbon recovery and CO2 sequestration.