 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Spatial Diffusion: Intensity-Preserving Diffusion Modeling
May 03, 2025Generative diffusion models have achieved remarkable success in producing high-quality images. However, because these models typically operate in continuous intensity spaces - diffusing independently per pixel and color channel - they are fundamentally ill-suited for applications where quantities such as particle counts or material units are inherently discrete and governed by strict conservation laws such as mass preservation, limiting their applicability in scientific workflows. To address this limitation, we propose Discrete Spatial Diffusion (DSD), a framework based on a continuous-time, discrete-state jump stochastic process that operates directly in discrete spatial domains while strictly preserving mass in both forward and reverse diffusion processes. By using spatial diffusion to achieve mass preservation, we introduce stochasticity naturally through a discrete formulation. We demonstrate the expressive flexibility of DSD by performing image synthesis, class conditioning, and image inpainting across widely-used image benchmarks, with the ability to condition on image intensity. Additionally, we highlight its applicability to domain-specific scientific data for materials microstructure, bridging the gap between diffusion models and mass-conditioned scientific applications.
Enhancing Cross-Language Code Translation via Task-Specific Embedding Alignment in Retrieval-Augmented Generation
Dec 06, 2024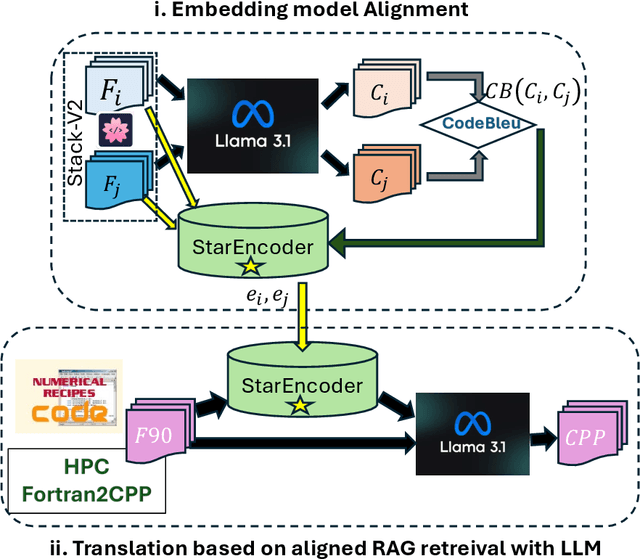



We introduce a novel method to enhance cross-language code translation from Fortran to C++ by integrating task-specific embedding alignment into a Retrieval-Augmented Generation (RAG) framework. Unlike conventional retrieval approaches that utilize generic embeddings agnostic to the downstream task, our strategy aligns the retrieval model directly with the objective of maximizing translation quality, as quantified by the CodeBLEU metric. This alignment ensures that the embeddings are semantically and syntactically meaningful for the specific code translation task. Our methodology involves constructing a dataset of 25,000 Fortran code snippets sourced from Stack-V2 dataset and generating their corresponding C++ translations using the LLaMA 3.1-8B language model. We compute pairwise CodeBLEU scores between the generated translations and ground truth examples to capture fine-grained similarities. These scores serve as supervision signals in a contrastive learning framework, where we optimize the embedding model to retrieve Fortran-C++ pairs that are most beneficial for improving the language model's translation performance. By integrating these CodeBLEU-optimized embeddings into the RAG framework, our approach significantly enhances both retrieval accuracy and code generation quality over methods employing generic embeddings. On the HPC Fortran2C++ dataset, our method elevates the average CodeBLEU score from 0.64 to 0.73, achieving a 14% relative improvement. On the Numerical Recipes dataset, we observe an increase from 0.52 to 0.60, marking a 15% relative improvement. Importantly, these gains are realized without any fine-tuning of the language model, underscoring the efficiency and practicality of our approach.
Patchfinder: Leveraging Visual Language Models for Accurate Information Retrieval using Model Uncertainty
Dec 03, 2024For decades, corporations and governments have relied on scanned documents to record vast amounts of information. However, extracting this information is a slow and tedious process due to the overwhelming amount of documents. The rise of vision language models presents a way to efficiently and accurately extract the information out of these documents. The current automated workflow often requires a two-step approach involving the extraction of information using optical character recognition software, and subsequent usage of large language models for processing this information. Unfortunately, these methods encounter significant challenges when dealing with noisy scanned documents. The high information density of such documents often necessitates using computationally expensive language models to effectively reduce noise. In this study, we propose PatchFinder, an algorithm that builds upon Vision Language Models (VLMs) to address the information extraction task. First, we devise a confidence-based score, called Patch Confidence, based on the Maximum Softmax Probability of the VLMs' output to measure the model's confidence in its predictions. Then, PatchFinder utilizes that score to determine a suitable patch size, partition the input document into overlapping patches of that size, and generate confidence-based predictions for the target information. Our experimental results show that PatchFinder can leverage Phi-3v, a 4.2 billion parameter vision language model, to achieve an accuracy of 94% on our dataset of 190 noisy scanned documents, surpassing the performance of ChatGPT-4o by 18.5 percentage points.
Enhancing Code Translation in Language Models with Few-Shot Learning via Retrieval-Augmented Generation
Jul 29, 2024



The advent of large language models (LLMs) has significantly advanced the field of code translation, enabling automated translation between programming languages. However, these models often struggle with complex translation tasks due to inadequate contextual understanding. This paper introduces a novel approach that enhances code translation through Few-Shot Learning, augmented with retrieval-based techniques. By leveraging a repository of existing code translations, we dynamically retrieve the most relevant examples to guide the model in translating new code segments. Our method, based on Retrieval-Augmented Generation (RAG), substantially improves translation quality by providing contextual examples from which the model can learn in real-time. We selected RAG over traditional fine-tuning methods due to its ability to utilize existing codebases or a locally stored corpus of code, which allows for dynamic adaptation to diverse translation tasks without extensive retraining. Extensive experiments on diverse datasets with open LLM models such as Starcoder, Llama3-70B Instruct, CodeLlama-34B Instruct, Granite-34B Code Instruct, and Mixtral-8x22B, as well as commercial LLM models like GPT-3.5 Turbo and GPT-4o, demonstrate our approach's superiority over traditional zero-shot methods, especially in translating between Fortran and CPP. We also explored varying numbers of shots i.e. examples provided during inference, specifically 1, 2, and 3 shots and different embedding models for RAG, including Nomic-Embed, Starencoder, and CodeBERT, to assess the robustness and effectiveness of our approach.
Reconstruction of Fields from Sparse Sensing: Differentiable Sensor Placement Enhances Generalization
Dec 14, 2023



Recreating complex, high-dimensional global fields from limited data points is a grand challenge across various scientific and industrial domains. Given the prohibitive costs of specialized sensors and the frequent inaccessibility of certain regions of the domain, achieving full field coverage is typically not feasible. Therefore, the development of algorithms that intelligently improve sensor placement is of significant value. In this study, we introduce a general approach that employs differentiable programming to exploit sensor placement within the training of a neural network model in order to improve field reconstruction. We evaluated our method using two distinct datasets; the results show that our approach improved test scores. Ultimately, our method of differentiable placement strategies has the potential to significantly increase data collection efficiency, enable more thorough area coverage, and reduce redundancy in sensor deployment.
Using Ornstein-Uhlenbeck Process to understand Denoising Diffusion Probabilistic Model and its Noise Schedules
Nov 29, 2023
The aim of this short note is to show that Denoising Diffusion Probabilistic Model DDPM, a non-homogeneous discrete-time Markov process, can be represented by a time-homogeneous continuous-time Markov process observed at non-uniformly sampled discrete times. Surprisingly, this continuous-time Markov process is the well-known and well-studied Ornstein-Ohlenbeck (OU) process, which was developed in 1930's for studying Brownian particles in Harmonic potentials. We establish the formal equivalence between DDPM and the OU process using its analytical solution. We further demonstrate that the design problem of the noise scheduler for non-homogeneous DDPM is equivalent to designing observation times for the OU process. We present several heuristic designs for observation times based on principled quantities such as auto-variance and Fisher Information and connect them to ad hoc noise schedules for DDPM. Interestingly, we show that the Fisher-Information-motivated schedule corresponds exactly the cosine schedule, which was developed without any theoretical foundation but is the current state-of-the-art noise schedule.
Mitigation of Spatial Nonstationarity with Vision Transformers
Dec 09, 2022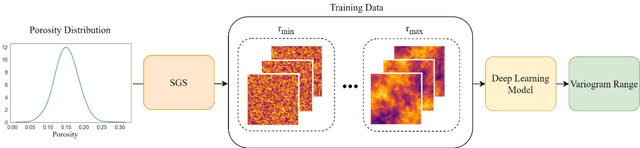
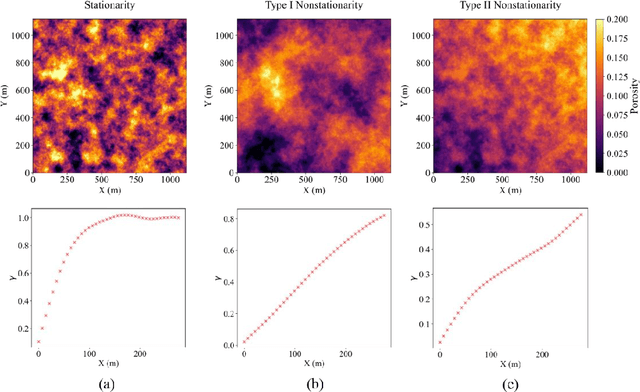
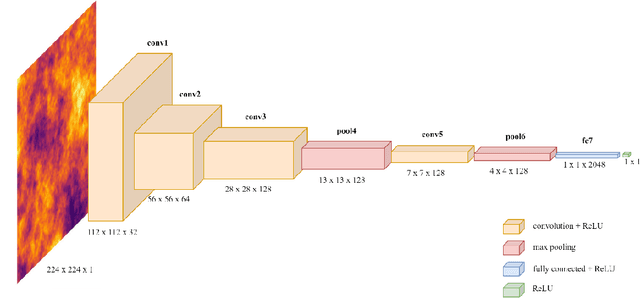
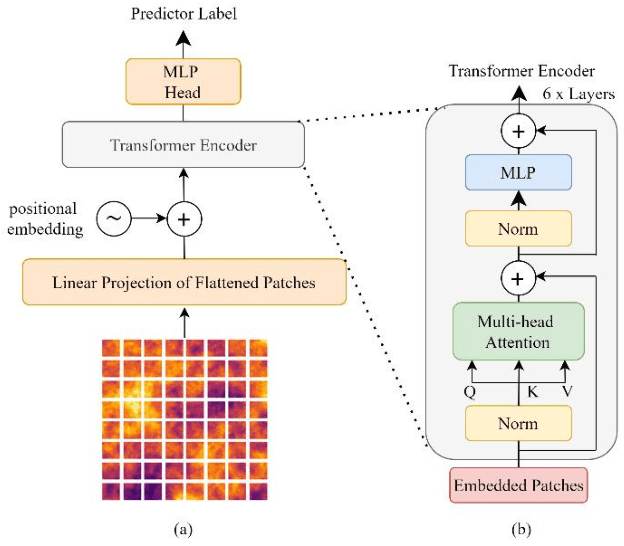
Spatial nonstationarity, the location variance of features' statistical distributions, is ubiquitous in many natural settings. For example, in geological reservoirs rock matrix porosity varies vertically due to geomechanical compaction trends, in mineral deposits grades vary due to sedimentation and concentration processes, in hydrology rainfall varies due to the atmosphere and topography interactions, and in metallurgy crystalline structures vary due to differential cooling. Conventional geostatistical modeling workflows rely on the assumption of stationarity to be able to model spatial features for the geostatistical inference. Nevertheless, this is often not a realistic assumption when dealing with nonstationary spatial data and this has motivated a variety of nonstationary spatial modeling workflows such as trend and residual decomposition, cosimulation with secondary features, and spatial segmentation and independent modeling over stationary subdomains. The advent of deep learning technologies has enabled new workflows for modeling spatial relationships. However, there is a paucity of demonstrated best practice and general guidance on mitigation of spatial nonstationarity with deep learning in the geospatial context. We demonstrate the impact of two common types of geostatistical spatial nonstationarity on deep learning model prediction performance and propose the mitigation of such impacts using self-attention (vision transformer) models. We demonstrate the utility of vision transformers for the mitigation of nonstationarity with relative errors as low as 10%, exceeding the performance of alternative deep learning methods such as convolutional neural networks. We establish best practice by demonstrating the ability of self-attention networks for modeling large-scale spatial relationships in the presence of commonly observed geospatial nonstationarity.
Predictive Scale-Bridging Simulations through Active Learning
Sep 20, 2022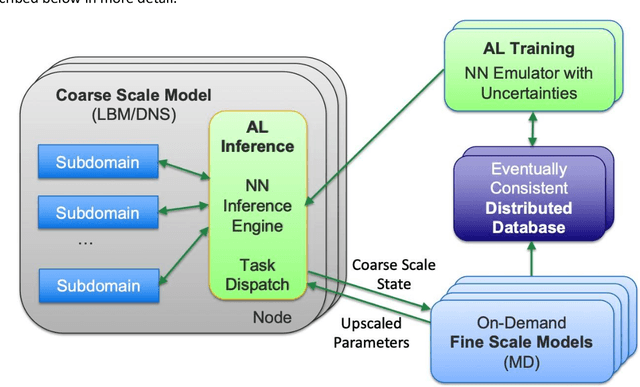
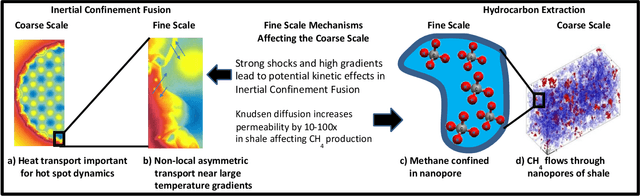
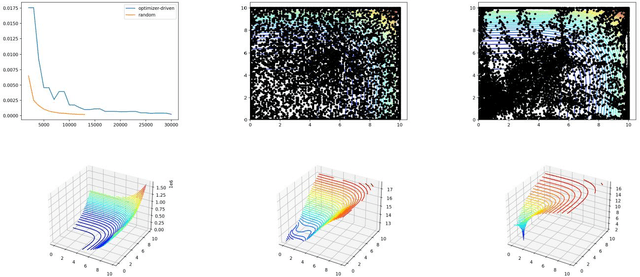
Throughout computational science, there is a growing need to utilize the continual improvements in raw computational horsepower to achieve greater physical fidelity through scale-bridging over brute-force increases in the number of mesh elements. For instance, quantitative predictions of transport in nanoporous media, critical to hydrocarbon extraction from tight shale formations, are impossible without accounting for molecular-level interactions. Similarly, inertial confinement fusion simulations rely on numerical diffusion to simulate molecular effects such as non-local transport and mixing without truly accounting for molecular interactions. With these two disparate applications in mind, we develop a novel capability which uses an active learning approach to optimize the use of local fine-scale simulations for informing coarse-scale hydrodynamics. Our approach addresses three challenges: forecasting continuum coarse-scale trajectory to speculatively execute new fine-scale molecular dynamics calculations, dynamically updating coarse-scale from fine-scale calculations, and quantifying uncertainty in neural network models.
MudrockNet: Semantic Segmentation of Mudrock SEM Images through Deep Learning
Feb 05, 2021
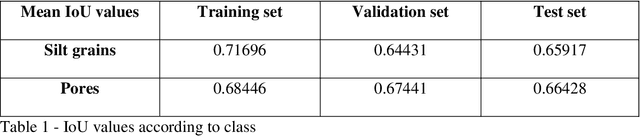
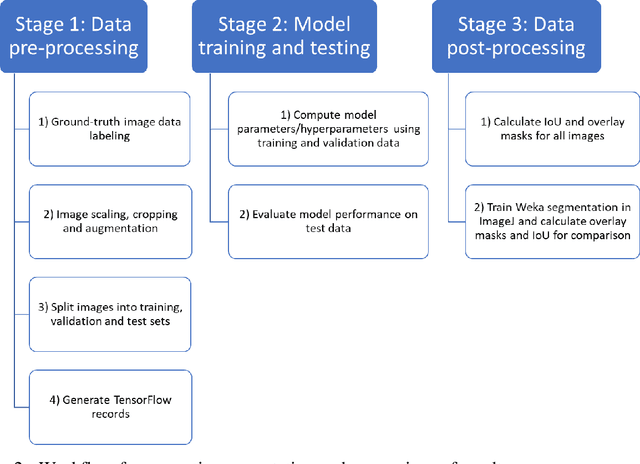
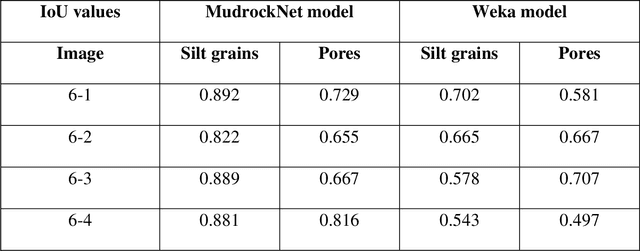
Segmentation and analysis of individual pores and grains of mudrocks from scanning electron microscope images is non-trivial because of noise, imaging artifacts, variation in pixel grayscale values across images, and overlaps in grayscale values among different physical features such as silt grains, clay grains, and pores in an image, which make their identification difficult. Moreover, because grains and pores often have overlapping grayscale values, direct application of threshold-based segmentation techniques is not sufficient. Recent advances in the field of computer vision have made it easier and faster to segment images and identify multiple occurrences of such features in an image, provided that ground-truth data for training the algorithm is available. Here, we propose a deep learning SEM image segmentation model, MudrockNet based on Google's DeepLab-v3+ architecture implemented with the TensorFlow library. The ground-truth data was obtained from an image-processing workflow applied to scanning electron microscope images of uncemented muds from the Kumano Basin offshore Japan at depths < 1.1 km. The trained deep learning model obtained a pixel-accuracy about 90%, and predictions for the test data obtained a mean intersection over union (IoU) of 0.6591 for silt grains and 0.6642 for pores. We also compared our model with the random forest classifier using trainable Weka segmentation in ImageJ, and it was observed that MudrockNet gave better predictions for both silt grains and pores. The size, concentration, and spatial arrangement of the silt and clay grains can affect the petrophysical properties of a mudrock, and an automated method to accurately identify the different grains and pores in mudrocks can help improve reservoir and seal characterization for petroleum exploration and anthropogenic waste sequestration.
Modeling nanoconfinement effects using active learning
May 07, 2020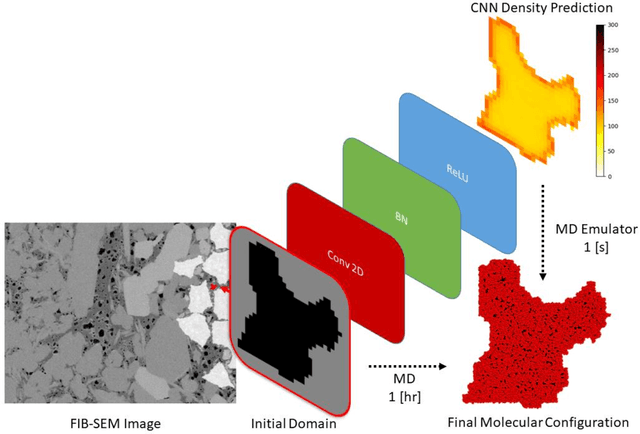


Predicting the spatial configuration of gas molecules in nanopores of shale formations is crucial for fluid flow forecasting and hydrocarbon reserves estimation. The key challenge in these tight formations is that the majority of the pore sizes are less than 50 nm. At this scale, the fluid properties are affected by nanoconfinement effects due to the increased fluid-solid interactions. For instance, gas adsorption to the pore walls could account for up to 85% of the total hydrocarbon volume in a tight reservoir. Although there are analytical solutions that describe this phenomenon for simple geometries, they are not suitable for describing realistic pores, where surface roughness and geometric anisotropy play important roles. To describe these, molecular dynamics (MD) simulations are used since they consider fluid-solid and fluid-fluid interactions at the molecular level. However, MD simulations are computationally expensive, and are not able to simulate scales larger than a few connected nanopores. We present a method for building and training physics-based deep learning surrogate models to carry out fast and accurate predictions of molecular configurations of gas inside nanopores. Since training deep learning models requires extensive databases that are computationally expensive to create, we employ active learning (AL). AL reduces the overhead of creating comprehensive sets of high-fidelity data by determining where the model uncertainty is greatest, and running simulations on the fly to minimize it. The proposed workflow enables nanoconfinement effects to be rigorously considered at the mesoscale where complex connected sets of nanopores control key applications such as hydrocarbon recovery and CO2 sequestration.