 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAS : Prelim Attention Score for Detecting Object Hallucinations in Large Vision--Language Models
Nov 14, 2025Large vision-language models (LVLMs) are powerful, yet they remain unreliable due to object hallucinations. In this work, we show that in many hallucinatory predictions the LVLM effectively ignores the image and instead relies on previously generated output (prelim) tokens to infer new objects. We quantify this behavior via the mutual information between the image and the predicted object conditioned on the prelim, demonstrating that weak image dependence strongly correlates with hallucination. Building on this finding, we introduce the Prelim Attention Score (PAS), a lightweight, training-free signal computed from attention weights over prelim tokens. PAS requires no additional forward passes and can be computed on the fly during inference. Exploiting this previously overlooked signal, PAS achieves state-of-the-art object-hallucination detection across multiple models and datasets, enabling real-time filtering and intervention.
Diverging Towards Hallucination: Detection of Failures in Vision-Language Models via Multi-token Aggregation
May 16, 2025



Vision-language models (VLMs) now rival human performance on many multimodal tasks, yet they still hallucinate objects or generate unsafe text. Current hallucination detectors, e.g., single-token linear probing (SLP) and P(True), typically analyze only the logit of the first generated token or just its highest scoring component overlooking richer signals embedded within earlier token distributions. We demonstrate that analyzing the complete sequence of early logits potentially provides substantially more diagnostic information. We emphasize that hallucinations may only emerge after several tokens, as subtle inconsistencies accumulate over time. By analyzing the Kullback-Leibler (KL) divergence between logits corresponding to hallucinated and non-hallucinated tokens, we underscore the importance of incorporating later-token logits to more accurately capture the reliability dynamics of VLMs. In response, we introduce Multi-Token Reliability Estimation (MTRE), a lightweight, white-box method that aggregates logits from the first ten tokens using multi-token log-likelihood ratios and self-attention. Despite the challenges posed by large vocabulary sizes and long logit sequences, MTRE remains efficient and tractable. On MAD-Bench, MM-SafetyBench, MathVista, and four compositional-geometry benchmarks, MTRE improves AUROC by 9.4 +/- 1.3 points over SLP and by 12.1 +/- 1.7 points over P(True), setting a new state-of-the-art in hallucination detection for open-source VLMs.
Lost in OCR Translation? Vision-Based Approaches to Robust Document Retrieval
May 08, 2025Retrieval-Augmented Generation (RAG) has become a popular technique for enhancing the reliability and utility of Large Language Models (LLMs) by grounding responses in external documents. Traditional RAG systems rely on Optical Character Recognition (OCR) to first process scanned documents into text. However, even state-of-the-art OCRs can introduce errors, especially in degraded or complex documents. Recent vision-language approaches, such as ColPali, propose direct visual embedding of documents, eliminating the need for OCR. This study presents a systematic comparison between a vision-based RAG system (ColPali) and more traditional OCR-based pipelines utilizing Llama 3.2 (90B) and Nougat OCR across varying document qualities. Beyond conventional retrieval accuracy metrics, we introduce a semantic answer evaluation benchmark to assess end-to-end question-answering performance. Our findings indicate that while vision-based RAG performs well on documents it has been fine-tuned on, OCR-based RAG is better able to generalize to unseen documents of varying quality. We highlight the key trade-offs between computational efficiency and semantic accuracy, offering practical guidance for RAG practitioners in selecting between OCR-dependent and vision-based document retrieval systems in production environments.
ARCS: Agentic Retrieval-Augmented Code Synthesis with Iterative Refinement
Apr 29, 2025In supercomputing, efficient and optimized code generation is essential to leverage high-performance systems effectively. We propose Agentic Retrieval-Augmented Code Synthesis (ARCS), an advanced framework for accurate, robust, and efficient code generation, completion, and translation. ARCS integrates Retrieval-Augmented Generation (RAG) with Chain-of-Thought (CoT) reasoning to systematically break down and iteratively refine complex programming tasks. An agent-based RAG mechanism retrieves relevant code snippets, while real-time execution feedback drives the synthesis of candidate solutions. This process is formalized as a state-action search tree optimization, balancing code correctness with editing efficiency. Evaluations on the Geeks4Geeks and HumanEval benchmarks demonstrate that ARCS significantly outperforms traditional prompting methods in translation and generation quality. By enabling scalable and precise code synthesis, ARCS offers transformative potential for automating and optimizing code development in supercomputing applications, enhancing computational resource utilization.
TT-LoRA MoE: Unifying Parameter-Efficient Fine-Tuning and Sparse Mixture-of-Experts
Apr 29, 2025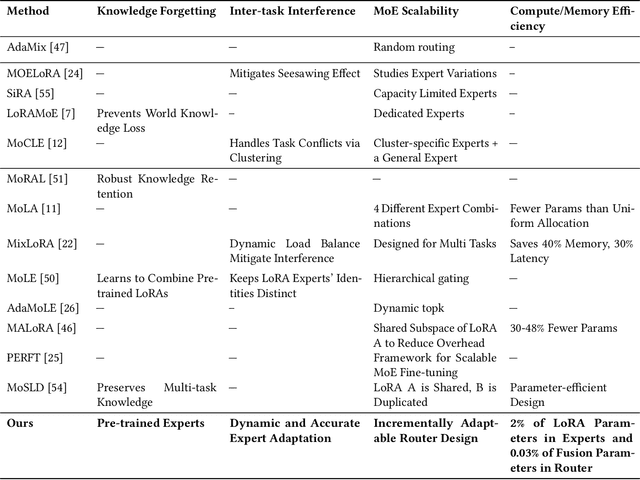
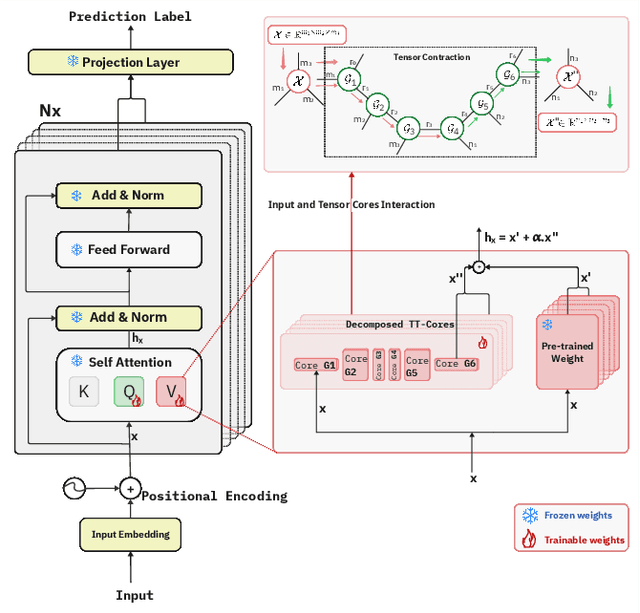
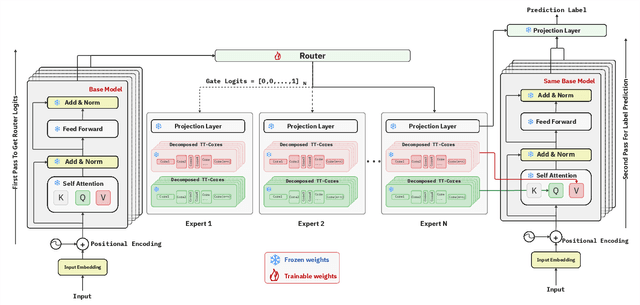

We propose Tensor-Trained Low-Rank Adaptation Mixture of Experts (TT-LoRA MoE), a novel computational framework integrating Parameter-Efficient Fine-Tuning (PEFT) with sparse MoE routing to address scalability challenges in large model deployments. Unlike traditional MoE approaches, which face substantial computational overhead as expert counts grow, TT-LoRA MoE decomposes training into two distinct, optimized stages. First, we independently train lightweight, tensorized low-rank adapters (TT-LoRA experts), each specialized for specific tasks. Subsequently, these expert adapters remain frozen, eliminating inter-task interference and catastrophic forgetting in multi-task setting. A sparse MoE router, trained separately, dynamically leverages base model representations to select exactly one specialized adapter per input at inference time, automating expert selection without explicit task specification. Comprehensive experiments confirm our architecture retains the memory efficiency of low-rank adapters, seamlessly scales to large expert pools, and achieves robust task-level optimization. This structured decoupling significantly enhances computational efficiency and flexibility: uses only 2% of LoRA, 0.3% of Adapters and 0.03% of AdapterFusion parameters and outperforms AdapterFusion by 4 value in multi-tasking, enabling practical and scalable multi-task inference deployments.
Topological Signatures of Adversaries in Multimodal Alignments
Jan 29, 2025Multimodal Machine Learning systems, particularly those aligning text and image data like CLIP/BLIP models, have become increasingly prevalent, yet remain susceptible to adversarial attacks. While substantial research has addressed adversarial robustness in unimodal contexts, defense strategies for multimodal systems are underexplored. This work investigates the topological signatures that arise between image and text embeddings and shows how adversarial attacks disrupt their alignment, introducing distinctive signatures. We specifically leverage persistent homology and introduce two novel Topological-Contrastive losses based on Total Persistence and Multi-scale kernel methods to analyze the topological signatures introduced by adversarial perturbations. We observe a pattern of monotonic changes in the proposed topological losses emerging in a wide range of attacks on image-text alignments, as more adversarial samples are introduced in the data. By designing an algorithm to back-propagate these signatures to input samples, we are able to integrate these signatures into Maximum Mean Discrepancy tests, creating a novel class of tests that leverage topological signatures for better adversarial detection.
Enhancing Cross-Language Code Translation via Task-Specific Embedding Alignment in Retrieval-Augmented Generation
Dec 06, 2024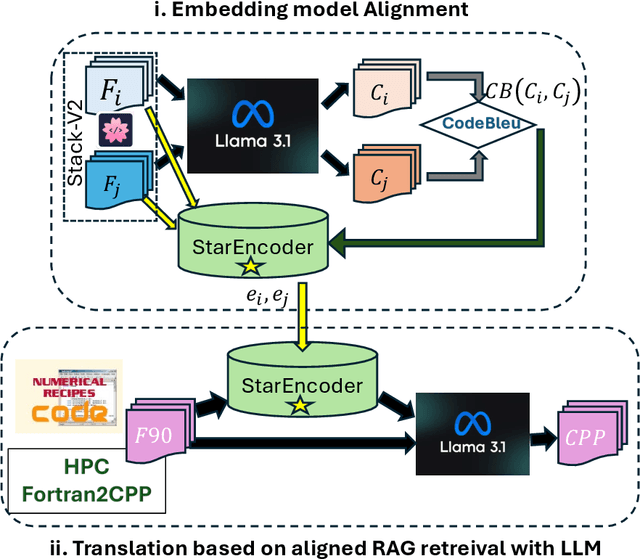



We introduce a novel method to enhance cross-language code translation from Fortran to C++ by integrating task-specific embedding alignment into a Retrieval-Augmented Generation (RAG) framework. Unlike conventional retrieval approaches that utilize generic embeddings agnostic to the downstream task, our strategy aligns the retrieval model directly with the objective of maximizing translation quality, as quantified by the CodeBLEU metric. This alignment ensures that the embeddings are semantically and syntactically meaningful for the specific code translation task. Our methodology involves constructing a dataset of 25,000 Fortran code snippets sourced from Stack-V2 dataset and generating their corresponding C++ translations using the LLaMA 3.1-8B language model. We compute pairwise CodeBLEU scores between the generated translations and ground truth examples to capture fine-grained similarities. These scores serve as supervision signals in a contrastive learning framework, where we optimize the embedding model to retrieve Fortran-C++ pairs that are most beneficial for improving the language model's translation performance. By integrating these CodeBLEU-optimized embeddings into the RAG framework, our approach significantly enhances both retrieval accuracy and code generation quality over methods employing generic embeddings. On the HPC Fortran2C++ dataset, our method elevates the average CodeBLEU score from 0.64 to 0.73, achieving a 14% relative improvement. On the Numerical Recipes dataset, we observe an increase from 0.52 to 0.60, marking a 15% relative improvement. Importantly, these gains are realized without any fine-tuning of the language model, underscoring the efficiency and practicality of our approach.
HEAL: Hierarchical Embedding Alignment Loss for Improved Retrieval and Representation Learning
Dec 05, 2024Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external document retrieval to provide domain-specific or up-to-date knowledge. The effectiveness of RAG depends on the relevance of retrieved documents, which is influenced by the semantic alignment of embeddings with the domain's specialized content. Although full fine-tuning can align language models to specific domains, it is computationally intensive and demands substantial data. This paper introduces Hierarchical Embedding Alignment Loss (HEAL), a novel method that leverages hierarchical fuzzy clustering with matrix factorization within contrastive learning to efficiently align LLM embeddings with domain-specific content. HEAL computes level/depth-wise contrastive losses and incorporates hierarchical penalties to align embeddings with the underlying relationships in label hierarchies. This approach enhances retrieval relevance and document classification, effectively reducing hallucinations in LLM outputs. In our experiments, we benchmark and evaluate HEAL across diverse domains, including Healthcare, Material Science, Cyber-security, and Applied Maths.
Patchfinder: Leveraging Visual Language Models for Accurate Information Retrieval using Model Uncertainty
Dec 03, 2024For decades, corporations and governments have relied on scanned documents to record vast amounts of information. However, extracting this information is a slow and tedious process due to the overwhelming amount of documents. The rise of vision language models presents a way to efficiently and accurately extract the information out of these documents. The current automated workflow often requires a two-step approach involving the extraction of information using optical character recognition software, and subsequent usage of large language models for processing this information. Unfortunately, these methods encounter significant challenges when dealing with noisy scanned documents. The high information density of such documents often necessitates using computationally expensive language models to effectively reduce noise. In this study, we propose PatchFinder, an algorithm that builds upon Vision Language Models (VLMs) to address the information extraction task. First, we devise a confidence-based score, called Patch Confidence, based on the Maximum Softmax Probability of the VLMs' output to measure the model's confidence in its predictions. Then, PatchFinder utilizes that score to determine a suitable patch size, partition the input document into overlapping patches of that size, and generate confidence-based predictions for the target information. Our experimental results show that PatchFinder can leverage Phi-3v, a 4.2 billion parameter vision language model, to achieve an accuracy of 94% on our dataset of 190 noisy scanned documents, surpassing the performance of ChatGPT-4o by 18.5 percentage points.
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024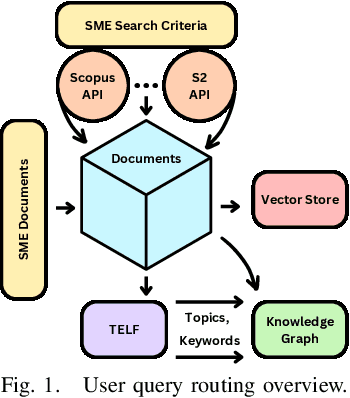
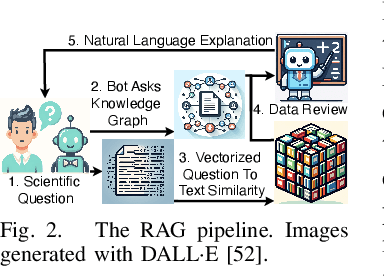
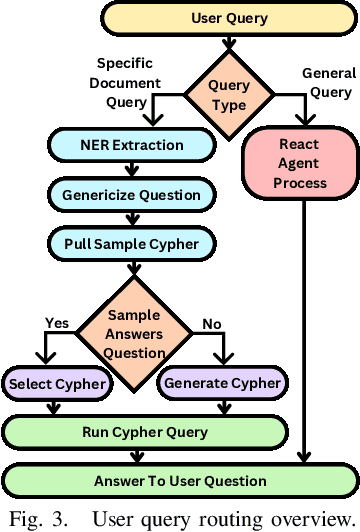
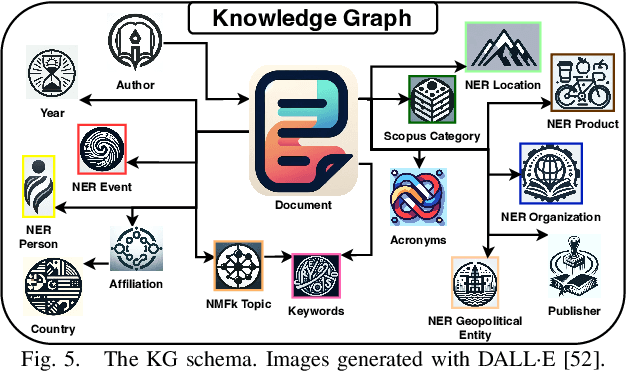
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.