 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Science in the Age of Artificial Intelligence
Nov 13, 2025Artificial intelligence (AI) is reshaping how research is conceived, conducted, and communicated across fields from chemistry to biomedicine. This commentary examines how AI is transforming the research workflow. AI systems now help researchers manage the information deluge, filtering the literature, surfacing cross-disciplinary links for ideas and collaborations, generating hypotheses, and designing and executing experiments. These developments mark a shift from AI as a mere computational tool to AI as an active collaborator in science. Yet this transformation demands thoughtful integration and governance. We argue that at this time AI must augment but not replace human judgment in academic workflows such as peer review, ethical evaluation, and validation of results. This paper calls for the deliberate adoption of AI within the scientific practice through policies that promote transparency, reproducibility, and accountability.
Topic Modeling and Link-Prediction for Material Property Discovery
Jul 08, 2025



Link prediction infers missing or future relations between graph nodes, based on connection patterns. Scientific literature networks and knowledge graphs are typically large, sparse, and noisy, and often contain missing links between entities. We present an AI-driven hierarchical link prediction framework that integrates matrix factorization to infer hidden associations and steer discovery in complex material domains. Our method combines Hierarchical Nonnegative Matrix Factorization (HNMFk) and Boolean matrix factorization (BNMFk) with automatic model selection, as well as Logistic matrix factorization (LMF), we use to construct a three-level topic tree from a 46,862-document corpus focused on 73 transition-metal dichalcogenides (TMDs). These materials are studied in a variety of physics fields with many current and potential applications. An ensemble BNMFk + LMF approach fuses discrete interpretability with probabilistic scoring. The resulting HNMFk clusters map each material onto coherent topics like superconductivity, energy storage, and tribology. Also, missing or weakly connected links are highlight between topics and materials, suggesting novel hypotheses for cross-disciplinary exploration. We validate our method by removing publications about superconductivity in well-known superconductors, and show the model predicts associations with the superconducting TMD clusters. This shows the method finds hidden connections in a graph of material to latent topic associations built from scientific literature, especially useful when examining a diverse corpus of scientific documents covering the same class of phenomena or materials but originating from distinct communities and perspectives. The inferred links generating new hypotheses, produced by our method, are exposed through an interactive Streamlit dashboard, designed for human-in-the-loop scientific discovery.
Matrix Factorization for Inferring Associations and Missing Links
Mar 06, 2025Missing link prediction is a method for network analysis, with applications in recommender systems, biology, social sciences, cybersecurity, information retrieval, and Artificial Intelligence (AI) reasoning in Knowledge Graphs. Missing link prediction identifies unseen but potentially existing connections in a network by analyzing the observed patterns and relationships. In proliferation detection, this supports efforts to identify and characterize attempts by state and non-state actors to acquire nuclear weapons or associated technology - a notoriously challenging but vital mission for global security. Dimensionality reduction techniques like Non-Negative Matrix Factorization (NMF) and Logistic Matrix Factorization (LMF) are effective but require selection of the matrix rank parameter, that is, of the number of hidden features, k, to avoid over/under-fitting. We introduce novel Weighted (WNMFk), Boolean (BNMFk), and Recommender (RNMFk) matrix factorization methods, along with ensemble variants incorporating logistic factorization, for link prediction. Our methods integrate automatic model determination for rank estimation by evaluating stability and accuracy using a modified bootstrap methodology and uncertainty quantification (UQ), assessing prediction reliability under random perturbations. We incorporate Otsu threshold selection and k-means clustering for Boolean matrix factorization, comparing them to coordinate descent-based Boolean thresholding. Our experiments highlight the impact of rank k selection, evaluate model performance under varying test-set sizes, and demonstrate the benefits of UQ for reliable predictions using abstention. We validate our methods on three synthetic datasets (Boolean and uniformly distributed) and benchmark them against LMF and symmetric LMF (symLMF) on five real-world protein-protein interaction networks, showcasing an improved prediction performance.
Bridging Legal Knowledge and AI: Retrieval-Augmented Generation with Vector Stores, Knowledge Graphs, and Hierarchical Non-negative Matrix Factorization
Feb 27, 2025

Agentic Generative AI, powered by Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG), Knowledge Graphs (KGs), and Vector Stores (VSs), represents a transformative technology applicable to specialized domains such as legal systems, research, recommender systems, cybersecurity, and global security, including proliferation research. This technology excels at inferring relationships within vast unstructured or semi-structured datasets. The legal domain here comprises complex data characterized by extensive, interrelated, and semi-structured knowledge systems with complex relations. It comprises constitutions, statutes, regulations, and case law. Extracting insights and navigating the intricate networks of legal documents and their relations is crucial for effective legal research. Here, we introduce a generative AI system that integrates RAG, VS, and KG, constructed via Non-Negative Matrix Factorization (NMF), to enhance legal information retrieval and AI reasoning and minimize hallucinations. In the legal system, these technologies empower AI agents to identify and analyze complex connections among cases, statutes, and legal precedents, uncovering hidden relationships and predicting legal trends-challenging tasks that are essential for ensuring justice and improving operational efficiency. Our system employs web scraping techniques to systematically collect legal texts, such as statutes, constitutional provisions, and case law, from publicly accessible platforms like Justia. It bridges the gap between traditional keyword-based searches and contextual understanding by leveraging advanced semantic representations, hierarchical relationships, and latent topic discovery. This framework supports legal document clustering, summarization, and cross-referencing, for scalable, interpretable, and accurate retrieval for semi-structured data while advancing computational law and AI.
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024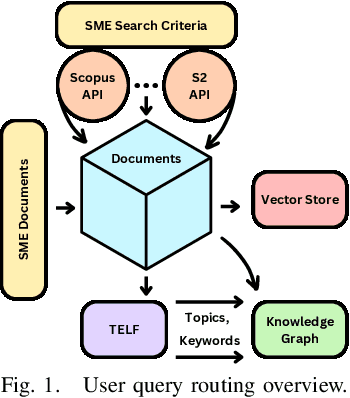
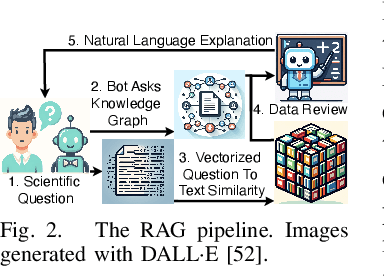
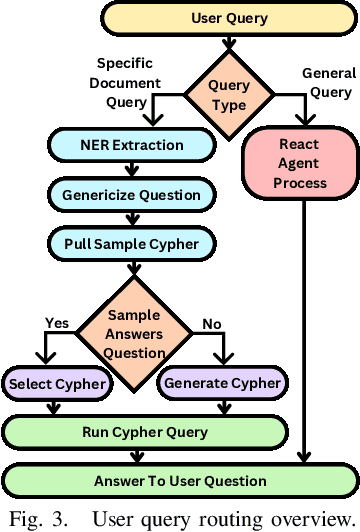
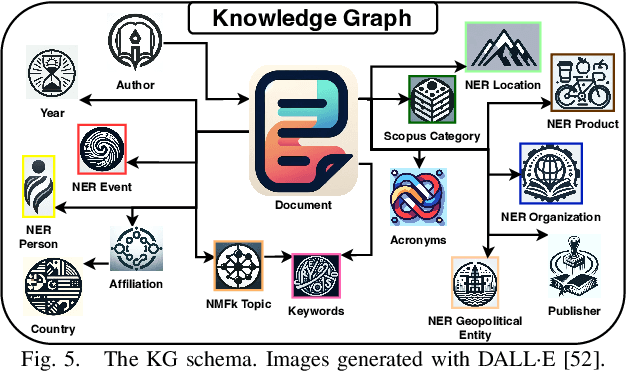
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.
Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs
Aug 02, 2024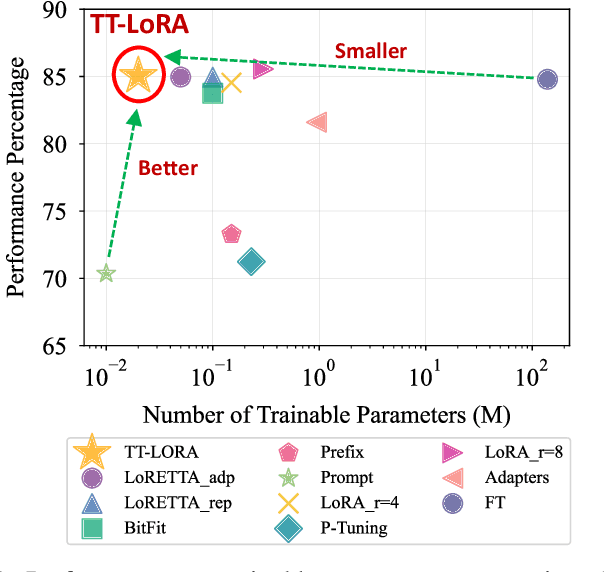
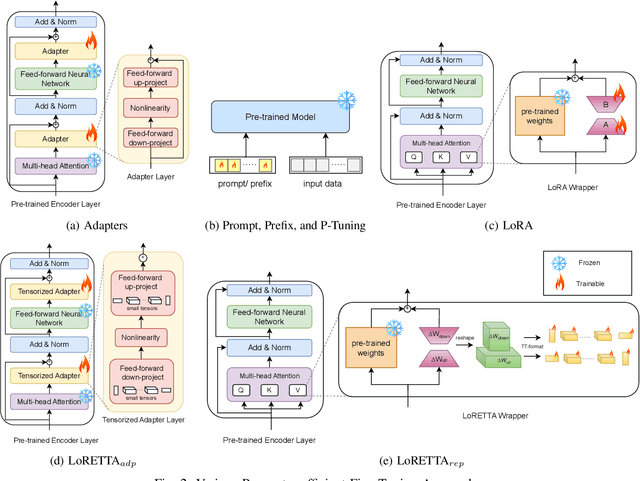
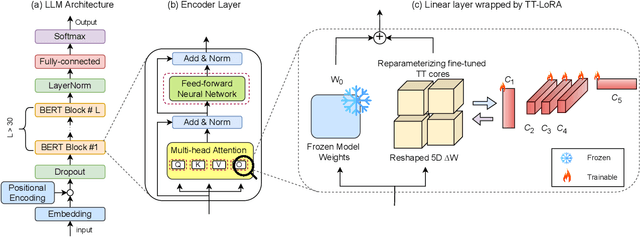
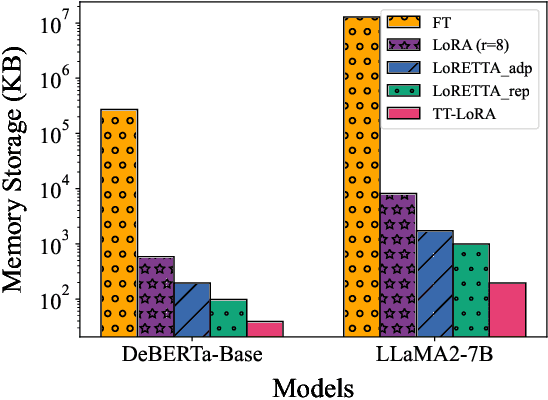
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide range of natural language processing (NLP) tasks, such as question-answering, sentiment analysis, text summarization, and machine translation. However, the ever-growing complexity of LLMs demands immense computational resources, hindering the broader research and application of these models. To address this, various parameter-efficient fine-tuning strategies, such as Low-Rank Approximation (LoRA) and Adapters, have been developed. Despite their potential, these methods often face limitations in compressibility. Specifically, LoRA struggles to scale effectively with the increasing number of trainable parameters in modern large scale LLMs. Additionally, Low-Rank Economic Tensor-Train Adaptation (LoRETTA), which utilizes tensor train decomposition, has not yet achieved the level of compression necessary for fine-tuning very large scale models with limited resources. This paper introduces Tensor Train Low-Rank Approximation (TT-LoRA), a novel parameter-efficient fine-tuning (PEFT) approach that extends LoRETTA with optimized tensor train (TT) decomposition integration. By eliminating Adapters and traditional LoRA-based structures, TT-LoRA achieves greater model compression without compromising downstream task performance, along with reduced inference latency and computational overhead. We conduct an exhaustive parameter search to establish benchmarks that highlight the trade-off between model compression and performance. Our results demonstrate significant compression of LLMs while maintaining comparable performance to larger models, facilitating their deployment on resource-constraint platforms.
TopicTag: Automatic Annotation of NMF Topic Models Using Chain of Thought and Prompt Tuning with LLMs
Jul 29, 2024
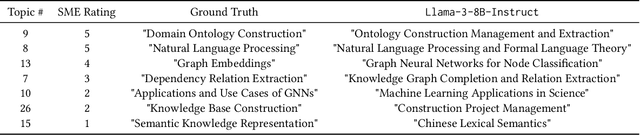
Topic modeling is a technique for organizing and extracting themes from large collections of unstructured text. Non-negative matrix factorization (NMF) is a common unsupervised approach that decomposes a term frequency-inverse document frequency (TF-IDF) matrix to uncover latent topics and segment the dataset accordingly. While useful for highlighting patterns and clustering documents, NMF does not provide explicit topic labels, necessitating subject matter experts (SMEs) to assign labels manually. We present a methodology for automating topic labeling in documents clustered via NMF with automatic model determination (NMFk). By leveraging the output of NMFk and employing prompt engineering, we utilize large language models (LLMs) to generate accurate topic labels. Our case study on over 34,000 scientific abstracts on Knowledge Graphs demonstrates the effectiveness of our method in enhancing knowledge management and document organization.
Binary Bleed: Fast Distributed and Parallel Method for Automatic Model Selection
Jul 26, 2024

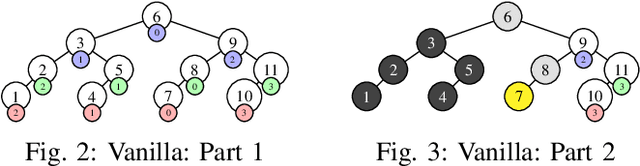
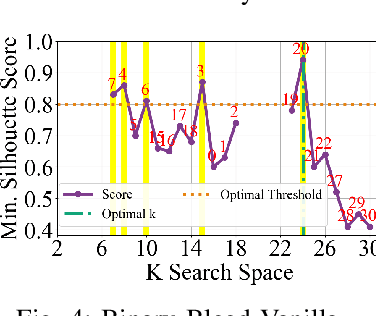
In several Machine Learning (ML) clustering and dimensionality reduction approaches, such as non-negative matrix factorization (NMF), RESCAL, and K-Means clustering, users must select a hyper-parameter k to define the number of clusters or components that yield an ideal separation of samples or clean clusters. This selection, while difficult, is crucial to avoid overfitting or underfitting the data. Several ML applications use scoring methods (e.g., Silhouette and Davies Boulding scores) to evaluate the cluster pattern stability for a specific k. The score is calculated for different trials over a range of k, and the ideal k is heuristically selected as the value before the model starts overfitting, indicated by a drop or increase in the score resembling an elbow curve plot. While the grid-search method can be used to accurately find a good k value, visiting a range of k can become time-consuming and computationally resource-intensive. In this paper, we introduce the Binary Bleed method based on binary search, which significantly reduces the k search space for these grid-search ML algorithms by truncating the target k values from the search space using a heuristic with thresholding over the scores. Binary Bleed is designed to work with single-node serial, single-node multi-processing, and distributed computing resources. In our experiments, we demonstrate the reduced search space gain over a naive sequential search of the ideal k and the accuracy of the Binary Bleed in identifying the correct k for NMFk, K-Means pyDNMFk, and pyDRESCALk with Silhouette and Davies Boulding scores. We make our implementation of Binary Bleed for the NMF algorithm available on GitHub.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.
Interactive Distillation of Large Single-Topic Corpora of Scientific Papers
Sep 19, 2023



Highly specific datasets of scientific literature are important for both research and education. However, it is difficult to build such datasets at scale. A common approach is to build these datasets reductively by applying topic modeling on an established corpus and selecting specific topics. A more robust but time-consuming approach is to build the dataset constructively in which a subject matter expert (SME) handpicks documents. This method does not scale and is prone to error as the dataset grows. Here we showcase a new tool, based on machine learning, for constructively generating targeted datasets of scientific literature. Given a small initial "core" corpus of papers, we build a citation network of documents. At each step of the citation network, we generate text embeddings and visualize the embeddings through dimensionality reduction. Papers are kept in the dataset if they are "similar" to the core or are otherwise pruned through human-in-the-loop selection. Additional insight into the papers is gained through sub-topic modeling using SeNMFk. We demonstrate our new tool for literature review by applying it to two different fields in machine learning.