 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Bleed: Fast Distributed and Parallel Method for Automatic Model Selection
Paper and Code


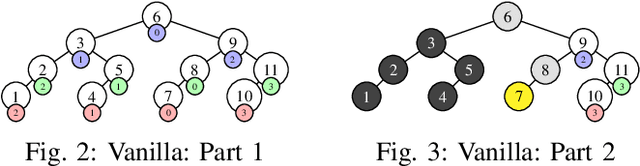
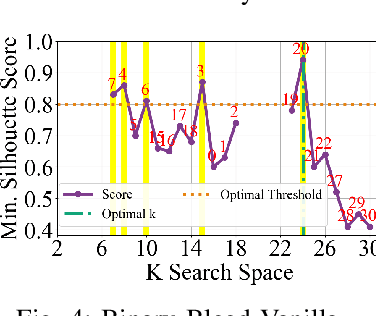
In several Machine Learning (ML) clustering and dimensionality reduction approaches, such as non-negative matrix factorization (NMF), RESCAL, and K-Means clustering, users must select a hyper-parameter k to define the number of clusters or components that yield an ideal separation of samples or clean clusters. This selection, while difficult, is crucial to avoid overfitting or underfitting the data. Several ML applications use scoring methods (e.g., Silhouette and Davies Boulding scores) to evaluate the cluster pattern stability for a specific k. The score is calculated for different trials over a range of k, and the ideal k is heuristically selected as the value before the model starts overfitting, indicated by a drop or increase in the score resembling an elbow curve plot. While the grid-search method can be used to accurately find a good k value, visiting a range of k can become time-consuming and computationally resource-intensive. In this paper, we introduce the Binary Bleed method based on binary search, which significantly reduces the k search space for these grid-search ML algorithms by truncating the target k values from the search space using a heuristic with thresholding over the scores. Binary Bleed is designed to work with single-node serial, single-node multi-processing, and distributed computing resources. In our experiments, we demonstrate the reduced search space gain over a naive sequential search of the ideal k and the accuracy of the Binary Bleed in identifying the correct k for NMFk, K-Means pyDNMFk, and pyDRESCALk with Silhouette and Davies Boulding scores. We make our implementation of Binary Bleed for the NMF algorithm available on GitHub.