 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited Linguistic Diversity in Embodied AI Datasets
Jan 06, 2026Language plays a critical role in Vision-Language-Action (VLA) models, yet the linguistic characteristics of the datasets used to train and evaluate these systems remain poorly documented. In this work, we present a systematic dataset audit of several widely used VLA corpora, aiming to characterize what kinds of instructions these datasets actually contain and how much linguistic variety they provide. We quantify instruction language along complementary dimensions-including lexical variety, duplication and overlap, semantic similarity, and syntactic complexity. Our analysis shows that many datasets rely on highly repetitive, template-like commands with limited structural variation, yielding a narrow distribution of instruction forms. We position these findings as descriptive documentation of the language signal available in current VLA training and evaluation data, intended to support more detailed dataset reporting, more principled dataset selection, and targeted curation or augmentation strategies that broaden language coverage.
Scaling Patterns in Adversarial Alignment: Evidence from Multi-LLM Jailbreak Experiments
Nov 16, 2025Large language models (LLMs) increasingly operate in multi-agent and safety-critical settings, raising open questions about how their vulnerabilities scale when models interact adversarially. This study examines whether larger models can systematically jailbreak smaller ones - eliciting harmful or restricted behavior despite alignment safeguards. Using standardized adversarial tasks from JailbreakBench, we simulate over 6,000 multi-turn attacker-target exchanges across major LLM families and scales (0.6B-120B parameters), measuring both harm score and refusal behavior as indicators of adversarial potency and alignment integrity. Each interaction is evaluated through aggregated harm and refusal scores assigned by three independent LLM judges, providing a consistent, model-based measure of adversarial outcomes. Aggregating results across prompts, we find a strong and statistically significant correlation between mean harm and the logarithm of the attacker-to-target size ratio (Pearson r = 0.51, p < 0.001; Spearman rho = 0.52, p < 0.001), indicating that relative model size correlates with the likelihood and severity of harmful completions. Mean harm score variance is higher across attackers (0.18) than across targets (0.10), suggesting that attacker-side behavioral diversity contributes more to adversarial outcomes than target susceptibility. Attacker refusal frequency is strongly and negatively correlated with harm (rho = -0.93, p < 0.001), showing that attacker-side alignment mitigates harmful responses. These findings reveal that size asymmetry influences robustness and provide exploratory evidence for adversarial scaling patterns, motivating more controlled investigations into inter-model alignment and safety.
Topic Modeling and Link-Prediction for Material Property Discovery
Jul 08, 2025



Link prediction infers missing or future relations between graph nodes, based on connection patterns. Scientific literature networks and knowledge graphs are typically large, sparse, and noisy, and often contain missing links between entities. We present an AI-driven hierarchical link prediction framework that integrates matrix factorization to infer hidden associations and steer discovery in complex material domains. Our method combines Hierarchical Nonnegative Matrix Factorization (HNMFk) and Boolean matrix factorization (BNMFk) with automatic model selection, as well as Logistic matrix factorization (LMF), we use to construct a three-level topic tree from a 46,862-document corpus focused on 73 transition-metal dichalcogenides (TMDs). These materials are studied in a variety of physics fields with many current and potential applications. An ensemble BNMFk + LMF approach fuses discrete interpretability with probabilistic scoring. The resulting HNMFk clusters map each material onto coherent topics like superconductivity, energy storage, and tribology. Also, missing or weakly connected links are highlight between topics and materials, suggesting novel hypotheses for cross-disciplinary exploration. We validate our method by removing publications about superconductivity in well-known superconductors, and show the model predicts associations with the superconducting TMD clusters. This shows the method finds hidden connections in a graph of material to latent topic associations built from scientific literature, especially useful when examining a diverse corpus of scientific documents covering the same class of phenomena or materials but originating from distinct communities and perspectives. The inferred links generating new hypotheses, produced by our method, are exposed through an interactive Streamlit dashboard, designed for human-in-the-loop scientific discovery.
Grounding Synthetic Data Evaluations of Language Models in Unsupervised Document Corpora
May 13, 2025Language Models (LMs) continue to advance, improving response quality and coherence. Given Internet-scale training datasets, LMs have likely encountered much of what users might ask them to generate in some form during their training. A plethora of evaluation benchmarks have been constructed to assess model quality, response appropriateness, and reasoning capabilities. However, the human effort required for benchmark construction is limited and being rapidly outpaced by the size and scope of the models under evaluation. Additionally, having humans build a benchmark for every possible domain of interest is impractical. Therefore, we propose a methodology for automating the construction of fact-based synthetic data model evaluations grounded in document populations. This work leverages those very same LMs to evaluate domain-specific knowledge automatically, using only grounding documents (e.g., a textbook) as input. This synthetic data benchmarking approach corresponds well with human curated questions with a Spearman ranking correlation of 0.96 and a benchmark evaluation Pearson accuracy correlation of 0.79. This novel tool supports generating both multiple choice and open-ended synthetic data questions to gain diagnostic insight of LM capability. We apply this methodology to evaluate model performance on a recent relevant arXiv preprint, discovering a surprisingly strong performance from Gemma3 models.
Matrix Factorization for Inferring Associations and Missing Links
Mar 06, 2025Missing link prediction is a method for network analysis, with applications in recommender systems, biology, social sciences, cybersecurity, information retrieval, and Artificial Intelligence (AI) reasoning in Knowledge Graphs. Missing link prediction identifies unseen but potentially existing connections in a network by analyzing the observed patterns and relationships. In proliferation detection, this supports efforts to identify and characterize attempts by state and non-state actors to acquire nuclear weapons or associated technology - a notoriously challenging but vital mission for global security. Dimensionality reduction techniques like Non-Negative Matrix Factorization (NMF) and Logistic Matrix Factorization (LMF) are effective but require selection of the matrix rank parameter, that is, of the number of hidden features, k, to avoid over/under-fitting. We introduce novel Weighted (WNMFk), Boolean (BNMFk), and Recommender (RNMFk) matrix factorization methods, along with ensemble variants incorporating logistic factorization, for link prediction. Our methods integrate automatic model determination for rank estimation by evaluating stability and accuracy using a modified bootstrap methodology and uncertainty quantification (UQ), assessing prediction reliability under random perturbations. We incorporate Otsu threshold selection and k-means clustering for Boolean matrix factorization, comparing them to coordinate descent-based Boolean thresholding. Our experiments highlight the impact of rank k selection, evaluate model performance under varying test-set sizes, and demonstrate the benefits of UQ for reliable predictions using abstention. We validate our methods on three synthetic datasets (Boolean and uniformly distributed) and benchmark them against LMF and symmetric LMF (symLMF) on five real-world protein-protein interaction networks, showcasing an improved prediction performance.
Bridging Legal Knowledge and AI: Retrieval-Augmented Generation with Vector Stores, Knowledge Graphs, and Hierarchical Non-negative Matrix Factorization
Feb 27, 2025

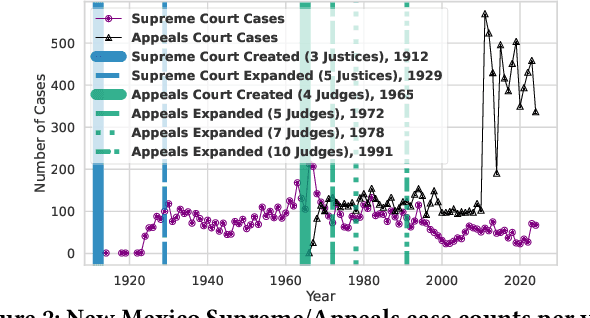
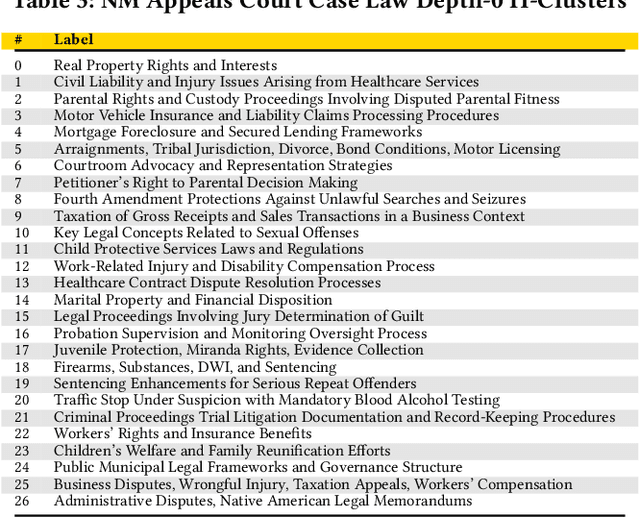
Agentic Generative AI, powered by Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG), Knowledge Graphs (KGs), and Vector Stores (VSs), represents a transformative technology applicable to specialized domains such as legal systems, research, recommender systems, cybersecurity, and global security, including proliferation research. This technology excels at inferring relationships within vast unstructured or semi-structured datasets. The legal domain here comprises complex data characterized by extensive, interrelated, and semi-structured knowledge systems with complex relations. It comprises constitutions, statutes, regulations, and case law. Extracting insights and navigating the intricate networks of legal documents and their relations is crucial for effective legal research. Here, we introduce a generative AI system that integrates RAG, VS, and KG, constructed via Non-Negative Matrix Factorization (NMF), to enhance legal information retrieval and AI reasoning and minimize hallucinations. In the legal system, these technologies empower AI agents to identify and analyze complex connections among cases, statutes, and legal precedents, uncovering hidden relationships and predicting legal trends-challenging tasks that are essential for ensuring justice and improving operational efficiency. Our system employs web scraping techniques to systematically collect legal texts, such as statutes, constitutional provisions, and case law, from publicly accessible platforms like Justia. It bridges the gap between traditional keyword-based searches and contextual understanding by leveraging advanced semantic representations, hierarchical relationships, and latent topic discovery. This framework supports legal document clustering, summarization, and cross-referencing, for scalable, interpretable, and accurate retrieval for semi-structured data while advancing computational law and AI.
On the Promise for Assurance of Differentiable Neurosymbolic Reasoning Paradigms
Feb 13, 2025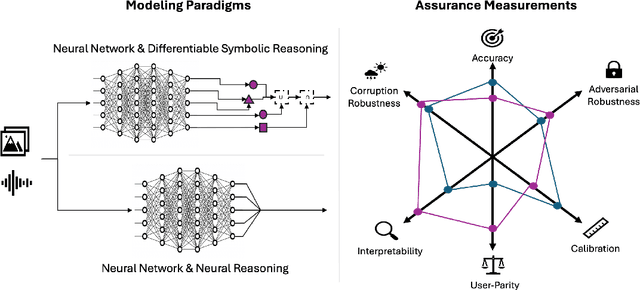
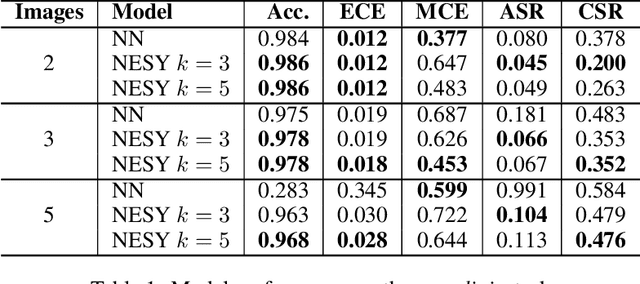
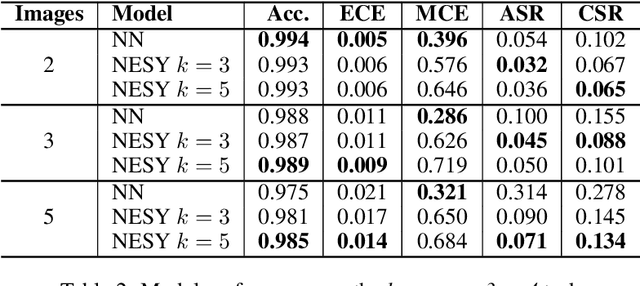
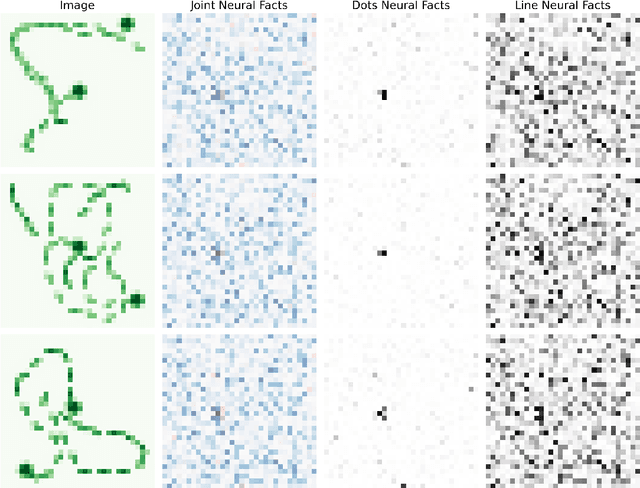
To create usable and deployable Artificial Intelligence (AI) systems, there requires a level of assurance in performance under many different conditions. Many times, deployed machine learning systems will require more classic logic and reasoning performed through neurosymbolic programs jointly with artificial neural network sensing. While many prior works have examined the assurance of a single component of the system solely with either the neural network alone or entire enterprise systems, very few works have examined the assurance of integrated neurosymbolic systems. Within this work, we assess the assurance of end-to-end fully differentiable neurosymbolic systems that are an emerging method to create data-efficient and more interpretable models. We perform this investigation using Scallop, an end-to-end neurosymbolic library, across classification and reasoning tasks in both the image and audio domains. We assess assurance across adversarial robustness, calibration, user performance parity, and interpretability of solutions for catching misaligned solutions. We find end-to-end neurosymbolic methods present unique opportunities for assurance beyond their data efficiency through our empirical results but not across the board. We find that this class of neurosymbolic models has higher assurance in cases where arithmetic operations are defined and where there is high dimensionality to the input space, where fully neural counterparts struggle to learn robust reasoning operations. We identify the relationship between neurosymbolic models' interpretability to catch shortcuts that later result in increased adversarial vulnerability despite performance parity. Finally, we find that the promise of data efficiency is typically only in the case of class imbalanced reasoning problems.
HEAL: Hierarchical Embedding Alignment Loss for Improved Retrieval and Representation Learning
Dec 05, 2024Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by integrating external document retrieval to provide domain-specific or up-to-date knowledge. The effectiveness of RAG depends on the relevance of retrieved documents, which is influenced by the semantic alignment of embeddings with the domain's specialized content. Although full fine-tuning can align language models to specific domains, it is computationally intensive and demands substantial data. This paper introduces Hierarchical Embedding Alignment Loss (HEAL), a novel method that leverages hierarchical fuzzy clustering with matrix factorization within contrastive learning to efficiently align LLM embeddings with domain-specific content. HEAL computes level/depth-wise contrastive losses and incorporates hierarchical penalties to align embeddings with the underlying relationships in label hierarchies. This approach enhances retrieval relevance and document classification, effectively reducing hallucinations in LLM outputs. In our experiments, we benchmark and evaluate HEAL across diverse domains, including Healthcare, Material Science, Cyber-security, and Applied Maths.
Living off the Analyst: Harvesting Features from Yara Rules for Malware Detection
Nov 27, 2024
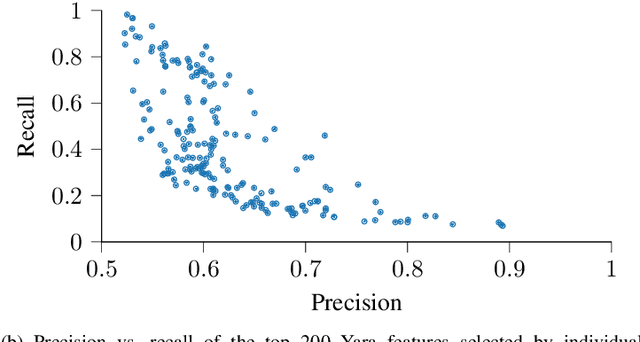
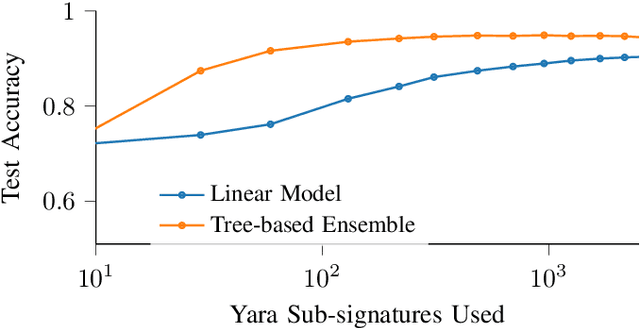
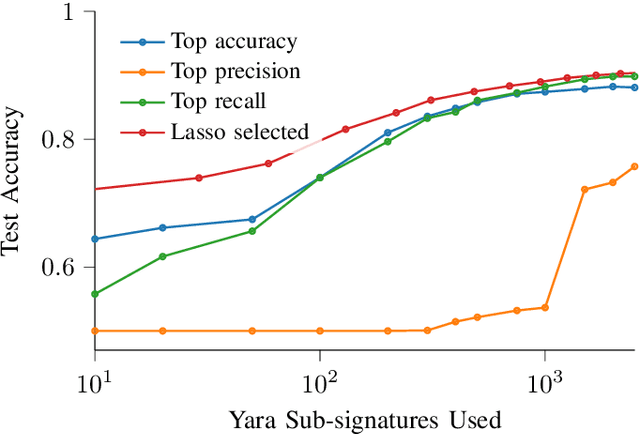
A strategy used by malicious actors is to "live off the land," where benign systems and tools already available on a victim's systems are used and repurposed for the malicious actor's intent. In this work, we ask if there is a way for anti-virus developers to similarly re-purpose existing work to improve their malware detection capability. We show that this is plausible via YARA rules, which use human-written signatures to detect specific malware families, functionalities, or other markers of interest. By extracting sub-signatures from publicly available YARA rules, we assembled a set of features that can more effectively discriminate malicious samples from benign ones. Our experiments demonstrate that these features add value beyond traditional features on the EMBER 2018 dataset. Manual analysis of the added sub-signatures shows a power-law behavior in a combination of features that are specific and unique, as well as features that occur often. A prior expectation may be that the features would be limited in being overly specific to unique malware families. This behavior is observed, and is apparently useful in practice. In addition, we also find sub-signatures that are dual-purpose (e.g., detecting virtual machine environments) or broadly generic (e.g., DLL imports).
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024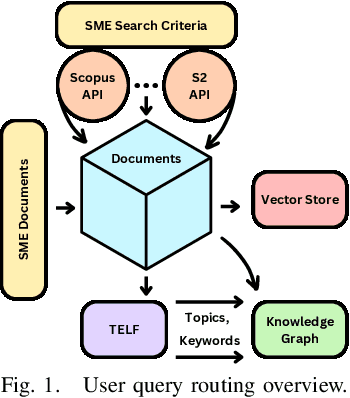
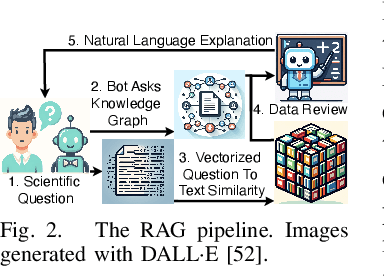
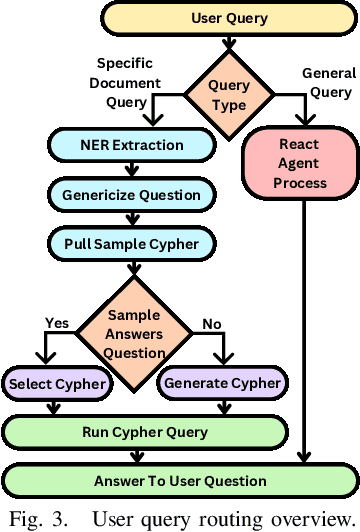
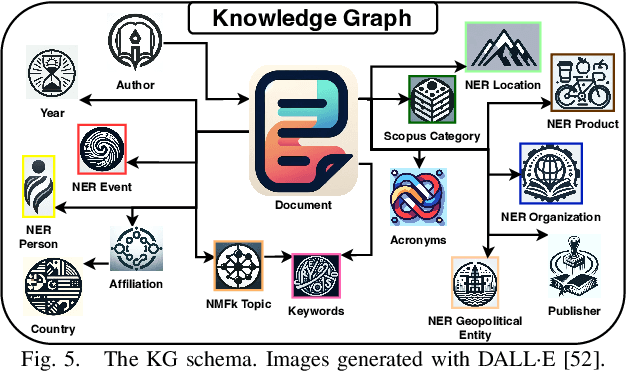
Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.