 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccounting for Sycophancy in Language Model Uncertainty Estimation
Oct 17, 2024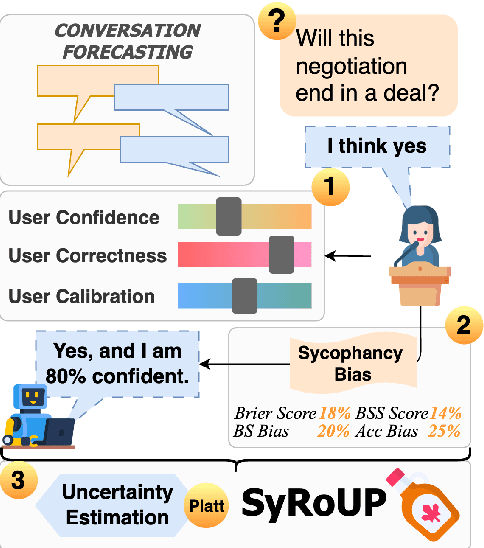



Effective human-machine collaboration requires machine learning models to externalize uncertainty, so users can reflect and intervene when necessary. For language models, these representations of uncertainty may be impacted by sycophancy bias: proclivity to agree with users, even if they are wrong. For instance, models may be over-confident in (incorrect) problem solutions suggested by a user. We study the relationship between sycophancy and uncertainty estimation for the first time. We propose a generalization of the definition of sycophancy bias to measure downstream impacts on uncertainty estimation, and also propose a new algorithm (SyRoUP) to account for sycophancy in the uncertainty estimation process. Unlike previous works on sycophancy, we study a broad array of user behaviors, varying both correctness and confidence of user suggestions to see how model answers (and their certainty) change. Our experiments across conversation forecasting and question-answering tasks show that user confidence plays a critical role in modulating the effects of sycophancy, and that SyRoUP can better predict these effects. From these results, we argue that externalizing both model and user uncertainty can help to mitigate the impacts of sycophancy bias.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024
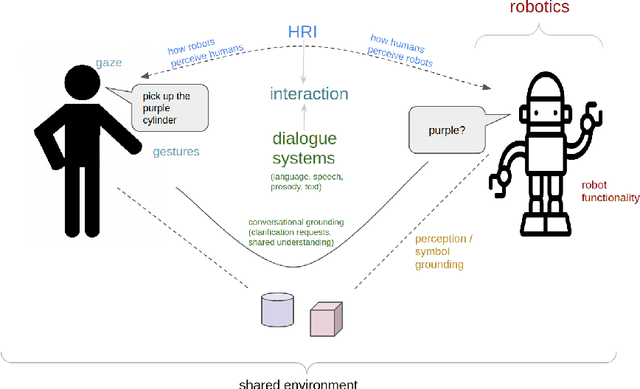
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Learning to Generate Context-Sensitive Backchannel Smiles for Embodied AI Agents with Applications in Mental Health Dialogues
Feb 13, 2024Addressing the critical shortage of mental health resources for effective screening, diagnosis, and treatment remains a significant challenge. This scarcity underscores the need for innovative solutions, particularly in enhancing the accessibility and efficacy of therapeutic support. Embodied agents with advanced interactive capabilities emerge as a promising and cost-effective supplement to traditional caregiving methods. Crucial to these agents' effectiveness is their ability to simulate non-verbal behaviors, like backchannels, that are pivotal in establishing rapport and understanding in therapeutic contexts but remain under-explored. To improve the rapport-building capabilities of embodied agents we annotated backchannel smiles in videos of intimate face-to-face conversations over topics such as mental health, illness, and relationships. We hypothesized that both speaker and listener behaviors affect the duration and intensity of backchannel smiles. Using cues from speech prosody and language along with the demographics of the speaker and listener, we found them to contain significant predictors of the intensity of backchannel smiles. Based on our findings, we introduce backchannel smile production in embodied agents as a generation problem. Our attention-based generative model suggests that listener information offers performance improvements over the baseline speaker-centric generation approach. Conditioned generation using the significant predictors of smile intensity provides statistically significant improvements in empirical measures of generation quality. Our user study by transferring generated smiles to an embodied agent suggests that agent with backchannel smiles is perceived to be more human-like and is an attractive alternative for non-personal conversations over agent without backchannel smiles.
Zero-shot Cross-Linguistic Learning of Event Semantics
Jul 05, 2022


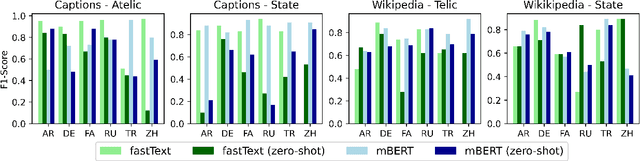
Typologically diverse languages offer systems of lexical and grammatical aspect that allow speakers to focus on facets of event structure in ways that comport with the specific communicative setting and discourse constraints they face. In this paper, we look specifically at captions of images across Arabic, Chinese, Farsi, German, Russian, and Turkish and describe a computational model for predicting lexical aspects. Despite the heterogeneity of these languages, and the salient invocation of distinctive linguistic resources across their caption corpora, speakers of these languages show surprising similarities in the ways they frame image content. We leverage this observation for zero-shot cross-lingual learning and show that lexical aspects can be predicted for a given language despite not having observed any annotated data for this language at all.