 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Norms and References Collide: Evaluating LLMs on Normative Reasoning
Feb 03, 2026Embodied agents, such as robots, will need to interact in situated environments where successful communication often depends on reasoning over social norms: shared expectations that constrain what actions are appropriate in context. A key capability in such settings is norm-based reference resolution (NBRR), where interpreting referential expressions requires inferring implicit normative expectations grounded in physical and social context. Yet it remains unclear whether Large Language Models (LLMs) can support this kind of reasoning. In this work, we introduce SNIC (Situated Norms in Context), a human-validated diagnostic testbed designed to probe how well state-of-the-art LLMs can extract and utilize normative principles relevant to NBRR. SNIC emphasizes physically grounded norms that arise in everyday tasks such as cleaning, tidying, and serving. Across a range of controlled evaluations, we find that even the strongest LLMs struggle to consistently identify and apply social norms, particularly when norms are implicit, underspecified, or in conflict. These findings reveal a blind spot in current LLMs and highlight a key challenge for deploying language-based systems in socially situated, embodied settings.
SCOUT: A Situated and Multi-Modal Human-Robot Dialogue Corpus
Nov 19, 2024



We introduce the Situated Corpus Of Understanding Transactions (SCOUT), a multi-modal collection of human-robot dialogue in the task domain of collaborative exploration. The corpus was constructed from multiple Wizard-of-Oz experiments where human participants gave verbal instructions to a remotely-located robot to move and gather information about its surroundings. SCOUT contains 89,056 utterances and 310,095 words from 278 dialogues averaging 320 utterances per dialogue. The dialogues are aligned with the multi-modal data streams available during the experiments: 5,785 images and 30 maps. The corpus has been annotated with Abstract Meaning Representation and Dialogue-AMR to identify the speaker's intent and meaning within an utterance, and with Transactional Units and Relations to track relationships between utterances to reveal patterns of the Dialogue Structure. We describe how the corpus and its annotations have been used to develop autonomous human-robot systems and enable research in open questions of how humans speak to robots. We release this corpus to accelerate progress in autonomous, situated, human-robot dialogue, especially in the context of navigation tasks where details about the environment need to be discovered.
* 14 pages, 7 figures
DriVLMe: Enhancing LLM-based Autonomous Driving Agents with Embodied and Social Experiences
Jun 05, 2024



Recent advancements in foundation models (FMs) have unlocked new prospects in autonomous driving, yet the experimental settings of these studies are preliminary, over-simplified, and fail to capture the complexity of real-world driving scenarios in human environments. It remains under-explored whether FM agents can handle long-horizon navigation tasks with free-from dialogue and deal with unexpected situations caused by environmental dynamics or task changes. To explore the capabilities and boundaries of FMs faced with the challenges above, we introduce DriVLMe, a video-language-model-based agent to facilitate natural and effective communication between humans and autonomous vehicles that perceive the environment and navigate. We develop DriVLMe from both embodied experiences in a simulated environment and social experiences from real human dialogue. While DriVLMe demonstrates competitive performance in both open-loop benchmarks and closed-loop human studies, we reveal several limitations and challenges, including unacceptable inference time, imbalanced training data, limited visual understanding, challenges with multi-turn interactions, simplified language generation from robotic experiences, and difficulties in handling on-the-fly unexpected situations like environmental dynamics and task changes.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024
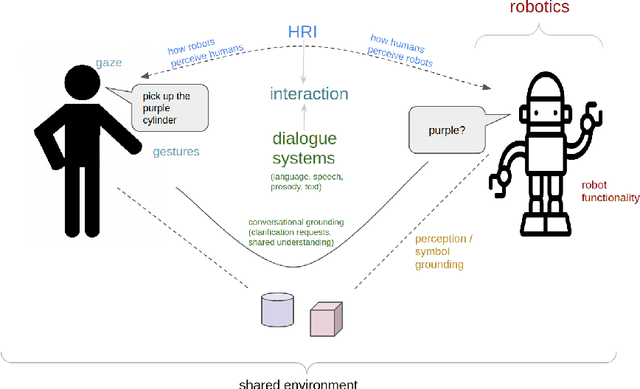
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
DOROTHIE: Spoken Dialogue for Handling Unexpected Situations in Interactive Autonomous Driving Agents
Oct 22, 2022



In the real world, autonomous driving agents navigate in highly dynamic environments full of unexpected situations where pre-trained models are unreliable. In these situations, what is immediately available to vehicles is often only human operators. Empowering autonomous driving agents with the ability to navigate in a continuous and dynamic environment and to communicate with humans through sensorimotor-grounded dialogue becomes critical. To this end, we introduce Dialogue On the ROad To Handle Irregular Events (DOROTHIE), a novel interactive simulation platform that enables the creation of unexpected situations on the fly to support empirical studies on situated communication with autonomous driving agents. Based on this platform, we created the Situated Dialogue Navigation (SDN), a navigation benchmark of 183 trials with a total of 8415 utterances, around 18.7 hours of control streams, and 2.9 hours of trimmed audio. SDN is developed to evaluate the agent's ability to predict dialogue moves from humans as well as generate its own dialogue moves and physical navigation actions. We further developed a transformer-based baseline model for these SDN tasks. Our empirical results indicate that language guided-navigation in a highly dynamic environment is an extremely difficult task for end-to-end models. These results will provide insight towards future work on robust autonomous driving agents. The DOROTHIE platform, SDN benchmark, and code for the baseline model are available at https://github.com/sled-group/DOROTHIE.
Decision-Theoretic Question Generation for Situated Reference Resolution: An Empirical Study and Computational Model
Oct 12, 2021

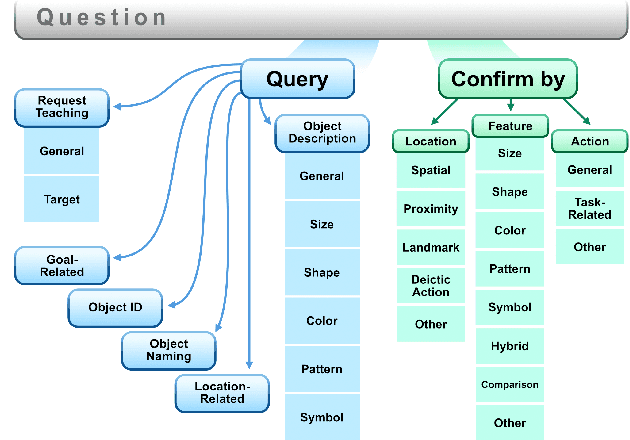
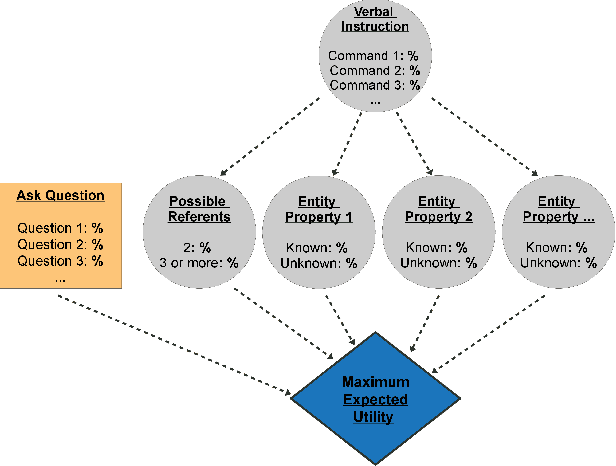
Dialogue agents that interact with humans in situated environments need to manage referential ambiguity across multiple modalities and ask for help as needed. However, it is not clear what kinds of questions such agents should ask nor how the answers to such questions can be used to resolve ambiguity. To address this, we analyzed dialogue data from an interactive study in which participants controlled a virtual robot tasked with organizing a set of tools while engaging in dialogue with a live, remote experimenter. We discovered a number of novel results, including the distribution of question types used to resolve ambiguity and the influence of dialogue-level factors on the reference resolution process. Based on these empirical findings we: (1) developed a computational model for clarification requests using a decision network with an entropy-based utility assignment method that operates across modalities, (2) evaluated the model, showing that it outperforms a slot-filling baseline in environments of varying ambiguity, and (3) interpreted the results to offer insight into the ways that agents can ask questions to facilitate situated reference resolution.
AI-HRI 2021 Proceedings
Sep 23, 2021The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. During that time, these symposia provided a fertile ground for numerous collaborations and pioneered many discussions revolving trust in HRI, XAI for HRI, service robots, interactive learning, and more. This year, we aim to review the achievements of the AI-HRI community in the last decade, identify the challenges facing ahead, and welcome new researchers who wish to take part in this growing community. Taking this wide perspective, this year there will be no single theme to lead the symposium and we encourage AI-HRI submissions from across disciplines and research interests. Moreover, with the rising interest in AR and VR as part of an interaction and following the difficulties in running physical experiments during the pandemic, this year we specifically encourage researchers to submit works that do not include a physical robot in their evaluation, but promote HRI research in general. In addition, acknowledging that ethics is an inherent part of the human-robot interaction, we encourage submissions of works on ethics for HRI. Over the course of the two-day meeting, we will host a collaborative forum for discussion of current efforts in AI-HRI, with additional talks focused on the topics of ethics in HRI and ubiquitous HRI.
How Should Agents Ask Questions For Situated Learning? An Annotated Dialogue Corpus
Jun 11, 2021



Intelligent agents that are confronted with novel concepts in situated environments will need to ask their human teammates questions to learn about the physical world. To better understand this problem, we need data about asking questions in situated task-based interactions. To this end, we present the Human-Robot Dialogue Learning (HuRDL) Corpus - a novel dialogue corpus collected in an online interactive virtual environment in which human participants play the role of a robot performing a collaborative tool-organization task. We describe the corpus data and a corresponding annotation scheme to offer insight into the form and content of questions that humans ask to facilitate learning in a situated environment. We provide the corpus as an empirically-grounded resource for improving question generation in situated intelligent agents.
Balancing Efficiency and Coverage in Human-Robot Dialogue Collection
Oct 07, 2018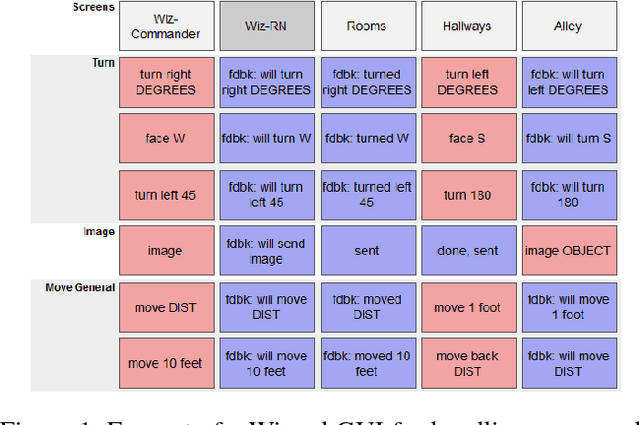
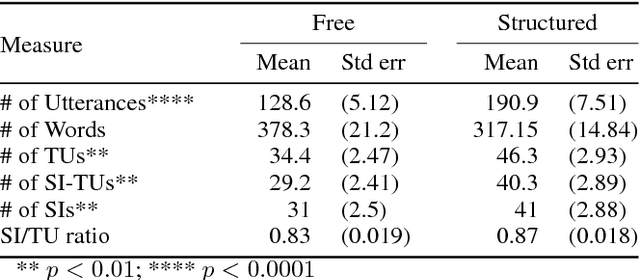
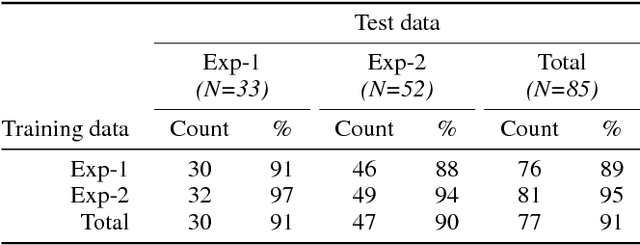
We describe a multi-phased Wizard-of-Oz approach to collecting human-robot dialogue in a collaborative search and navigation task. The data is being used to train an initial automated robot dialogue system to support collaborative exploration tasks. In the first phase, a wizard freely typed robot utterances to human participants. For the second phase, this data was used to design a GUI that includes buttons for the most common communications, and templates for communications with varying parameters. Comparison of the data gathered in these phases show that the GUI enabled a faster pace of dialogue while still maintaining high coverage of suitable responses, enabling more efficient targeted data collection, and improvements in natural language understanding using GUI-collected data. As a promising first step towards interactive learning, this work shows that our approach enables the collection of useful training data for navigation-based HRI tasks.
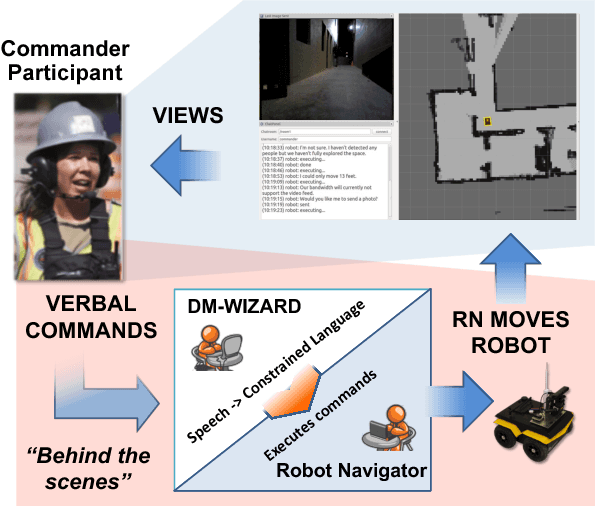
ScoutBot: A Dialogue System for Collaborative Navigation
Jul 21, 2018
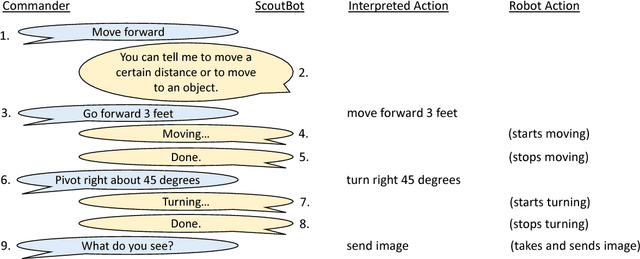
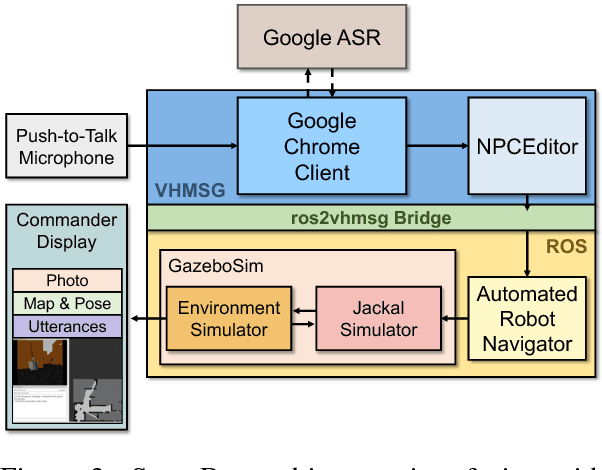

ScoutBot is a dialogue interface to physical and simulated robots that supports collaborative exploration of environments. The demonstration will allow users to issue unconstrained spoken language commands to ScoutBot. ScoutBot will prompt for clarification if the user's instruction needs additional input. It is trained on human-robot dialogue collected from Wizard-of-Oz experiments, where robot responses were initiated by a human wizard in previous interactions. The demonstration will show a simulated ground robot (Clearpath Jackal) in a simulated environment supported by ROS (Robot Operating System).