 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniCanvas: A Diffusion-base Unified Model for Text-in-Image Joint Generation
Jun 02, 2026Recent years have seen remarkable progress in unified vision-language models handling both multimodal understanding and generation within a single architecture. While autoregressive VLMs can reason across modalities, they fail to generate high-quality images. In contrast, diffusion models produce photorealistic visuals yet struggle to generate coherent text, making it challenging to develop a single unified model that can seamlessly handle both visual and text generation. Recent advances suggest that language can be effectively embedded within visual representations, allowing models to reason about textual semantics directly from images. To this end, we propose UniCanvas, a first attempt that unifies diffusion models to generate interleaved multimodal contents through text-in-image generation. Diffusion models naturally capture transformations on a shared pixel canvas, which can be viewed as world models of visual change. Instead of producing discrete text tokens, the model learns to represent language as visual patterns inside images, leveraging its inherent multimodal embedding space. This design allows the model to "draw" text naturally within a single pixel canvas during image synthesis, achieving seamless multimodal generation. Experiments demonstrate that UniCanvas improves performance over previous unified models, positioning text-in-image generation with diffusion models as a promising unified multimodal generation paradigm.
CocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
Fast Spatial Memory with Elastic Test-Time Training
Apr 08, 2026Large Chunk Test-Time Training (LaCT) has shown strong performance on long-context 3D reconstruction, but its fully plastic inference-time updates remain vulnerable to catastrophic forgetting and overfitting. As a result, LaCT is typically instantiated with a single large chunk spanning the full input sequence, falling short of the broader goal of handling arbitrarily long sequences in a single pass. We propose Elastic Test-Time Training inspired by elastic weight consolidation, that stabilizes LaCT fast-weight updates with a Fisher-weighted elastic prior around a maintained anchor state. The anchor evolves as an exponential moving average of past fast weights to balance stability and plasticity. Based on this updated architecture, we introduce Fast Spatial Memory (FSM), an efficient and scalable model for 4D reconstruction that learns spatiotemporal representations from long observation sequences and renders novel view-time combinations. We pre-trained FSM on large-scale curated 3D/4D data to capture the dynamics and semantics of complex spatial environments. Extensive experiments show that FSM supports fast adaptation over long sequences and delivers high-quality 3D/4D reconstruction with smaller chunks and mitigating the camera-interpolation shortcut. Overall, we hope to advance LaCT beyond the bounded single-chunk setting toward robust multi-chunk adaptation, a necessary step for generalization to genuinely longer sequences, while substantially alleviating the activation-memory bottleneck.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
Next-Embedding Prediction Makes Strong Vision Learners
Dec 23, 2025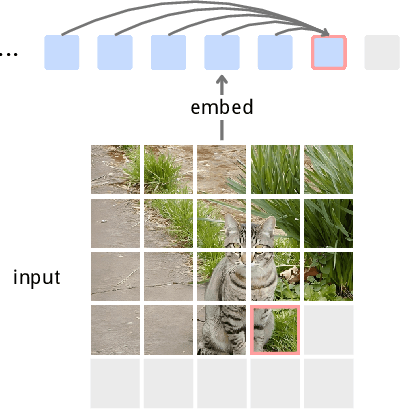
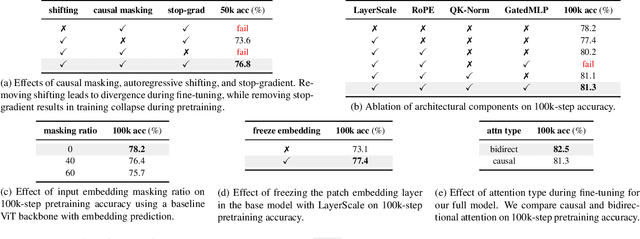
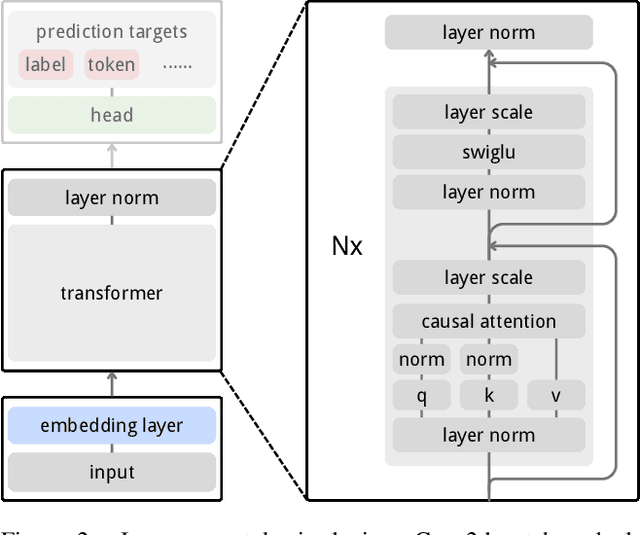
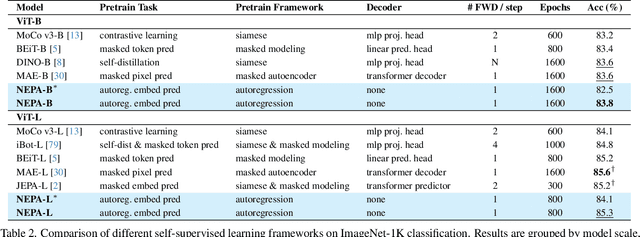
Inspired by the success of generative pretraining in natural language, we ask whether the same principles can yield strong self-supervised visual learners. Instead of training models to output features for downstream use, we train them to generate embeddings to perform predictive tasks directly. This work explores such a shift from learning representations to learning models. Specifically, models learn to predict future patch embeddings conditioned on past ones, using causal masking and stop gradient, which we refer to as Next-Embedding Predictive Autoregression (NEPA). We demonstrate that a simple Transformer pretrained on ImageNet-1k with next embedding prediction as its sole learning objective is effective - no pixel reconstruction, discrete tokens, contrastive loss, or task-specific heads. This formulation retains architectural simplicity and scalability, without requiring additional design complexity. NEPA achieves strong results across tasks, attaining 83.8% and 85.3% top-1 accuracy on ImageNet-1K with ViT-B and ViT-L backbones after fine-tuning, and transferring effectively to semantic segmentation on ADE20K. We believe generative pretraining from embeddings provides a simple, scalable, and potentially modality-agnostic alternative to visual self-supervised learning.
DeliveryBench: Can Agents Earn Profit in Real World?
Dec 22, 2025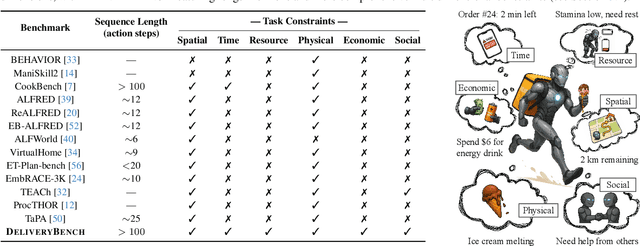
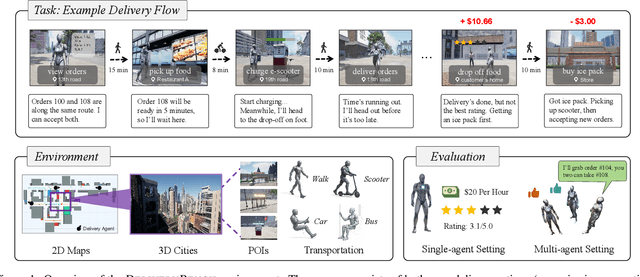
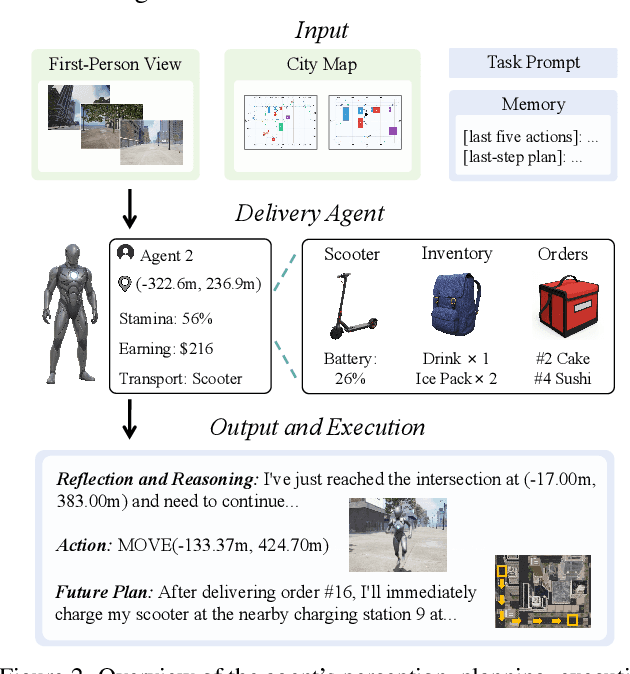
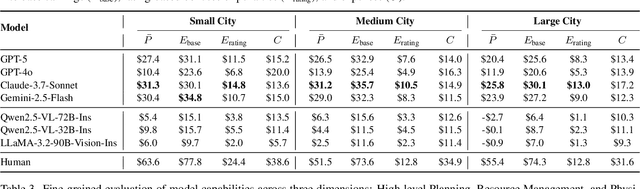
LLMs and VLMs are increasingly deployed as embodied agents, yet existing benchmarks largely revolve around simple short-term tasks and struggle to capture rich realistic constraints that shape real-world decision making. To close this gap, we propose DeliveryBench, a city-scale embodied benchmark grounded in the real-world profession of food delivery. Food couriers naturally operate under long-horizon objectives (maximizing net profit over hours) while managing diverse constraints, e.g., delivery deadline, transportation expense, vehicle battery, and necessary interactions with other couriers and customers. DeliveryBench instantiates this setting in procedurally generated 3D cities with diverse road networks, buildings, functional locations, transportation modes, and realistic resource dynamics, enabling systematic evaluation of constraint-aware, long-horizon planning. We benchmark a range of VLM-based agents across nine cities and compare them with human players. Our results reveal a substantial performance gap to humans, and find that these agents are short-sighted and frequently break basic commonsense constraints. Additionally, we observe distinct personalities across models (e.g., adventurous GPT-5 vs. conservative Claude), highlighting both the brittleness and the diversity of current VLM-based embodied agents in realistic, constraint-dense environments. Our code, data, and benchmark are available at https://deliverybench.github.io.
SimWorld-Robotics: Synthesizing Photorealistic and Dynamic Urban Environments for Multimodal Robot Navigation and Collaboration
Dec 10, 2025Recent advances in foundation models have shown promising results in developing generalist robotics that can perform diverse tasks in open-ended scenarios given multimodal inputs. However, current work has been mainly focused on indoor, household scenarios. In this work, we present SimWorld-Robotics~(SWR), a simulation platform for embodied AI in large-scale, photorealistic urban environments. Built on Unreal Engine 5, SWR procedurally generates unlimited photorealistic urban scenes populated with dynamic elements such as pedestrians and traffic systems, surpassing prior urban simulations in realism, complexity, and scalability. It also supports multi-robot control and communication. With these key features, we build two challenging robot benchmarks: (1) a multimodal instruction-following task, where a robot must follow vision-language navigation instructions to reach a destination in the presence of pedestrians and traffic; and (2) a multi-agent search task, where two robots must communicate to cooperatively locate and meet each other. Unlike existing benchmarks, these two new benchmarks comprehensively evaluate a wide range of critical robot capacities in realistic scenarios, including (1) multimodal instructions grounding, (2) 3D spatial reasoning in large environments, (3) safe, long-range navigation with people and traffic, (4) multi-robot collaboration, and (5) grounded communication. Our experimental results demonstrate that state-of-the-art models, including vision-language models (VLMs), struggle with our tasks, lacking robust perception, reasoning, and planning abilities necessary for urban environments.
From Behavioral Performance to Internal Competence: Interpreting Vision-Language Models with VLM-Lens
Oct 02, 2025We introduce VLM-Lens, a toolkit designed to enable systematic benchmarking, analysis, and interpretation of vision-language models (VLMs) by supporting the extraction of intermediate outputs from any layer during the forward pass of open-source VLMs. VLM-Lens provides a unified, YAML-configurable interface that abstracts away model-specific complexities and supports user-friendly operation across diverse VLMs. It currently supports 16 state-of-the-art base VLMs and their over 30 variants, and is extensible to accommodate new models without changing the core logic. The toolkit integrates easily with various interpretability and analysis methods. We demonstrate its usage with two simple analytical experiments, revealing systematic differences in the hidden representations of VLMs across layers and target concepts. VLM-Lens is released as an open-sourced project to accelerate community efforts in understanding and improving VLMs.
AimBot: A Simple Auxiliary Visual Cue to Enhance Spatial Awareness of Visuomotor Policies
Aug 11, 2025In this paper, we propose AimBot, a lightweight visual augmentation technique that provides explicit spatial cues to improve visuomotor policy learning in robotic manipulation. AimBot overlays shooting lines and scope reticles onto multi-view RGB images, offering auxiliary visual guidance that encodes the end-effector's state. The overlays are computed from depth images, camera extrinsics, and the current end-effector pose, explicitly conveying spatial relationships between the gripper and objects in the scene. AimBot incurs minimal computational overhead (less than 1 ms) and requires no changes to model architectures, as it simply replaces original RGB images with augmented counterparts. Despite its simplicity, our results show that AimBot consistently improves the performance of various visuomotor policies in both simulation and real-world settings, highlighting the benefits of spatially grounded visual feedback.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.