 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision Language Models Infer Human Gaze Direction? A Controlled Study
Jun 04, 2025Gaze-referential inference--the ability to infer what others are looking at--is a critical component of a theory of mind that underpins natural human-AI interaction. In a controlled study, we evaluated this skill across 111 Vision Language Models (VLMs) using photos taken with manipulated difficulty and variability, comparing performance with that of human participants (N = 65), and analyzed behaviors using mixed-effects models. We found that 94 of the 111 VLMs failed to do better than random guessing, while humans achieved near-ceiling accuracy. VLMs even respond with each choice almost equally frequently. Are they randomly guessing? Although most VLMs struggle, when we zoom in on five of the top-tier VLMs with above-chance performance, we find that their performance declined with increasing task difficulty but varied only slightly across different prompts and scene objects. These behavioral features cannot be explained by considering them as random guessers. Instead, they likely use a combination of heuristics and guessing such that their performance is subject to the task difficulty but robust to perceptual variations. This suggests that VLMs, lacking gaze inference capability, have yet to become technologies that can naturally interact with humans, but the potential remains.
Machine Psychophysics: Cognitive Control in Vision-Language Models
May 25, 2025Cognitive control refers to the ability to flexibly coordinate thought and action in pursuit of internal goals. A standard method for assessing cognitive control involves conflict tasks that contrast congruent and incongruent trials, measuring the ability to prioritize relevant information while suppressing interference. We evaluate 108 vision-language models on three classic conflict tasks and their more demanding "squared" variants across 2,220 trials. Model performance corresponds closely to human behavior under resource constraints and reveals individual differences. These results indicate that some form of human-like executive function have emerged in current multi-modal foundational models.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Vision-Language Models Are Not Pragmatically Competent in Referring Expression Generation
Apr 22, 2025
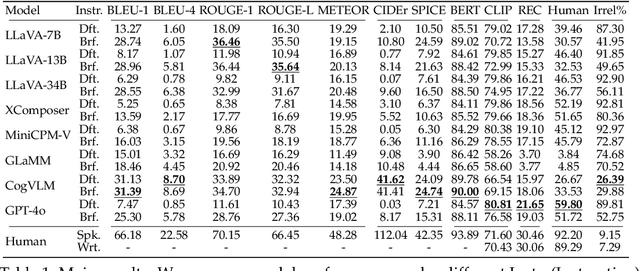

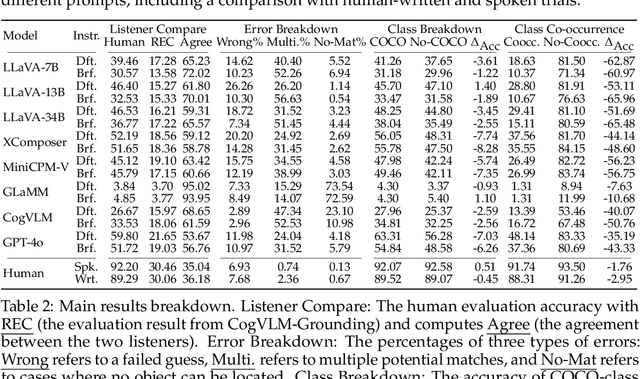
Referring Expression Generation (REG) is a core task for evaluating the pragmatic competence of vision-language systems, requiring not only accurate semantic grounding but also adherence to principles of cooperative communication (Grice, 1975). However, current evaluations of vision-language models (VLMs) often overlook the pragmatic dimension, reducing REG to a region-based captioning task and neglecting Gricean maxims. In this work, we revisit REG from a pragmatic perspective, introducing a new dataset (RefOI) of 1.5k images annotated with both written and spoken referring expressions. Through a systematic evaluation of state-of-the-art VLMs, we identify three key failures of pragmatic competence: (1) failure to uniquely identify the referent, (2) inclusion of excessive or irrelevant information, and (3) misalignment with human pragmatic preference, such as the underuse of minimal spatial cues. We also show that standard automatic evaluations fail to capture these pragmatic violations, reinforcing superficial cues rather than genuine referential success. Our findings call for a renewed focus on pragmatically informed models and evaluation frameworks that align with real human communication.
CogDevelop2K: Reversed Cognitive Development in Multimodal Large Language Models
Oct 06, 2024
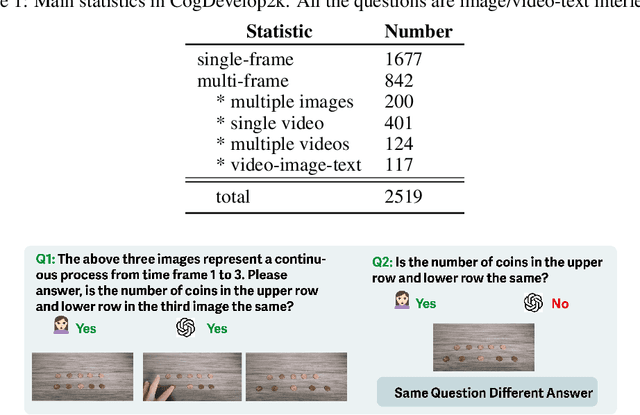


Are Multi-modal Large Language Models (MLLMs) stochastic parrots? Do they genuinely understand and are capable of performing the tasks they excel at? This paper aims to explore the fundamental basis of MLLMs, i.e. core cognitive abilities that human intelligence builds upon to perceive, comprehend, and reason. To this end, we propose CogDevelop2K, a comprehensive benchmark that spans 12 sub-concepts from fundamental knowledge like object permanence and boundary to advanced reasoning like intentionality understanding, structured via the developmental trajectory of a human mind. We evaluate 46 MLLMs on our benchmarks. Comprehensively, we further evaluate the influence of evaluation strategies and prompting techniques. Surprisingly, we observe a reversed cognitive developmental trajectory compared to humans.