 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Camera Pose from Perspective Descriptions for Spatial Reasoning
Feb 05, 2026Multi-image spatial reasoning remains challenging for current multimodal large language models (MLLMs). While single-view perception is inherently 2D, reasoning over multiple views requires building a coherent scene understanding across viewpoints. In particular, we study perspective taking, where a model must build a coherent 3D understanding from multi-view observations and use it to reason from a new, language-specified viewpoint. We introduce CAMCUE, a pose-aware multi-image framework that uses camera pose as an explicit geometric anchor for cross-view fusion and novel-view reasoning. CAMCUE injects per-view pose into visual tokens, grounds natural-language viewpoint descriptions to a target camera pose, and synthesizes a pose-conditioned imagined target view to support answering. To support this setting, we curate CAMCUE-DATA with 27,668 training and 508 test instances pairing multi-view images and poses with diverse target-viewpoint descriptions and perspective-shift questions. We also include human-annotated viewpoint descriptions in the test split to evaluate generalization to human language. CAMCUE improves overall accuracy by 9.06% and predicts target poses from natural-language viewpoint descriptions with over 90% rotation accuracy within 20° and translation accuracy within a 0.5 error threshold. This direct grounding avoids expensive test-time search-and-match, reducing inference time from 256.6s to 1.45s per example and enabling fast, interactive use in real-world scenarios.
Vision-Language Models Are Not Pragmatically Competent in Referring Expression Generation
Apr 22, 2025
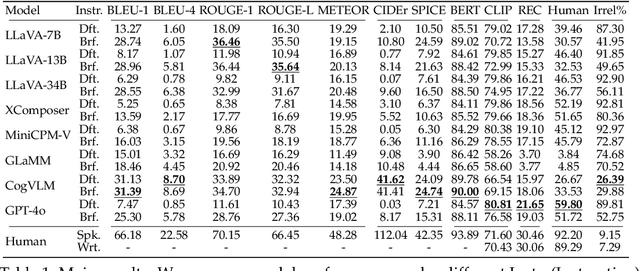

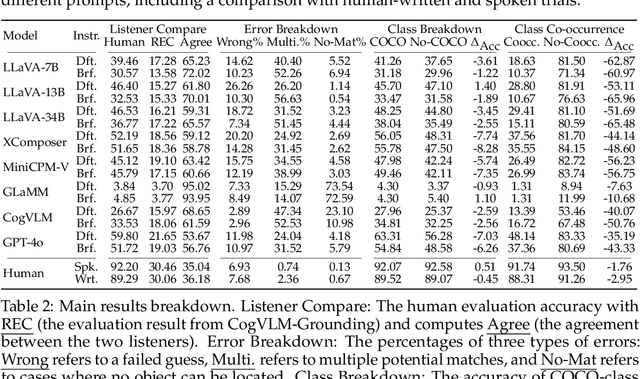
Referring Expression Generation (REG) is a core task for evaluating the pragmatic competence of vision-language systems, requiring not only accurate semantic grounding but also adherence to principles of cooperative communication (Grice, 1975). However, current evaluations of vision-language models (VLMs) often overlook the pragmatic dimension, reducing REG to a region-based captioning task and neglecting Gricean maxims. In this work, we revisit REG from a pragmatic perspective, introducing a new dataset (RefOI) of 1.5k images annotated with both written and spoken referring expressions. Through a systematic evaluation of state-of-the-art VLMs, we identify three key failures of pragmatic competence: (1) failure to uniquely identify the referent, (2) inclusion of excessive or irrelevant information, and (3) misalignment with human pragmatic preference, such as the underuse of minimal spatial cues. We also show that standard automatic evaluations fail to capture these pragmatic violations, reinforcing superficial cues rather than genuine referential success. Our findings call for a renewed focus on pragmatically informed models and evaluation frameworks that align with real human communication.
Multi-Object Hallucination in Vision-Language Models
Jul 08, 2024



Large vision language models (LVLMs) often suffer from object hallucination, producing objects not present in the given images. While current benchmarks for object hallucination primarily concentrate on the presence of a single object class rather than individual entities, this work systematically investigates multi-object hallucination, examining how models misperceive (e.g., invent nonexistent objects or become distracted) when tasked with focusing on multiple objects simultaneously. We introduce Recognition-based Object Probing Evaluation (ROPE), an automated evaluation protocol that considers the distribution of object classes within a single image during testing and uses visual referring prompts to eliminate ambiguity. With comprehensive empirical studies and analysis of potential factors leading to multi-object hallucination, we found that (1) LVLMs suffer more hallucinations when focusing on multiple objects compared to a single object. (2) The tested object class distribution affects hallucination behaviors, indicating that LVLMs may follow shortcuts and spurious correlations.(3) Hallucinatory behaviors are influenced by data-specific factors, salience and frequency, and model intrinsic behaviors. We hope to enable LVLMs to recognize and reason about multiple objects that often occur in realistic visual scenes, provide insights, and quantify our progress towards mitigating the issues.
Ask Question First for Enhancing Lifelong Language Learning
Aug 17, 2022


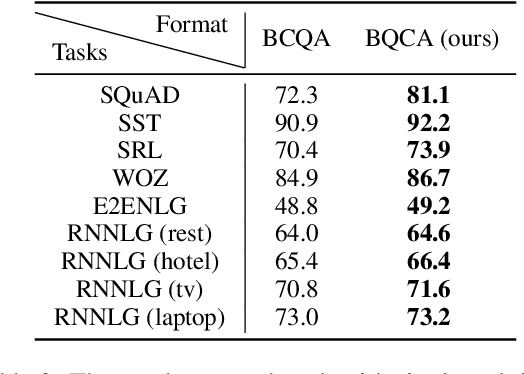
Lifelong language learning aims to stream learning NLP tasks while retaining knowledge of previous tasks. Previous works based on the language model and following data-free constraint approaches have explored formatting all data as "begin token (\textit{B}) + context (\textit{C}) + question (\textit{Q}) + answer (\textit{A})" for different tasks. However, they still suffer from catastrophic forgetting and are exacerbated when the previous task's pseudo data is insufficient for the following reasons: (1) The model has difficulty generating task-corresponding pseudo data, and (2) \textit{A} is prone to error when \textit{A} and \textit{C} are separated by \textit{Q} because the information of the \textit{C} is diminished before generating \textit{A}. Therefore, we propose the Ask Question First and Replay Question (AQF-RQ), including a novel data format "\textit{BQCA}" and a new training task to train pseudo questions of previous tasks. Experimental results demonstrate that AQF-RQ makes it easier for the model to generate more pseudo data that match corresponding tasks, and is more robust to both sufficient and insufficient pseudo-data when the task boundary is both clear and unclear. AQF-RQ can achieve only 0.36\% lower performance than multi-task learning.
RVAE-LAMOL: Residual Variational Autoencoder to Enhance Lifelong Language Learning
May 22, 2022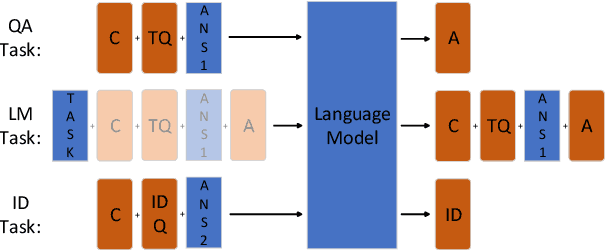
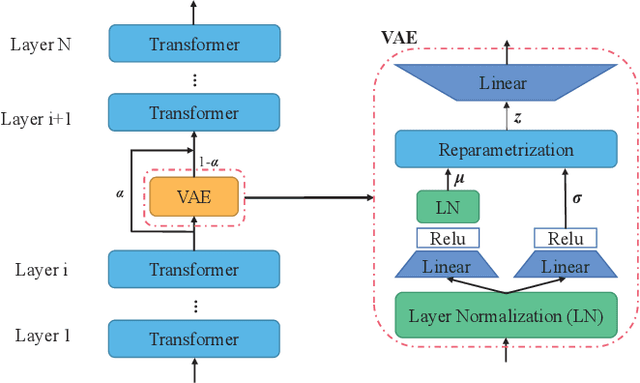
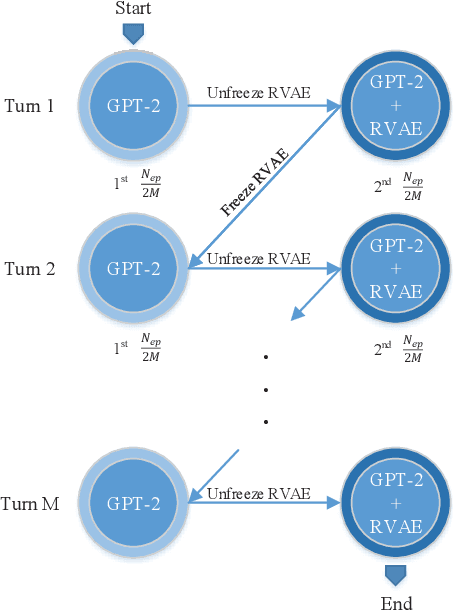

Lifelong Language Learning (LLL) aims to train a neural network to learn a stream of NLP tasks while retaining knowledge from previous tasks. However, previous works which followed data-free constraint still suffer from catastrophic forgetting issue, where the model forgets what it just learned from previous tasks. In order to alleviate catastrophic forgetting, we propose the residual variational autoencoder (RVAE) to enhance LAMOL, a recent LLL model, by mapping different tasks into a limited unified semantic space. In this space, previous tasks are easy to be correct to their own distribution by pseudo samples. Furthermore, we propose an identity task to make the model is discriminative to recognize the sample belonging to which task. For training RVAE-LAMOL better, we propose a novel training scheme Alternate Lag Training. In the experiments, we test RVAE-LAMOL on permutations of three datasets from DecaNLP. The experimental results demonstrate that RVAE-LAMOL outperforms na\"ive LAMOL on all permutations and generates more meaningful pseudo-samples.
Decomposing Complex Questions Makes Multi-Hop QA Easier and More Interpretable
Oct 26, 2021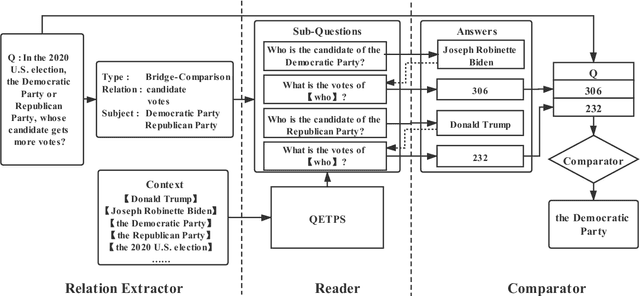
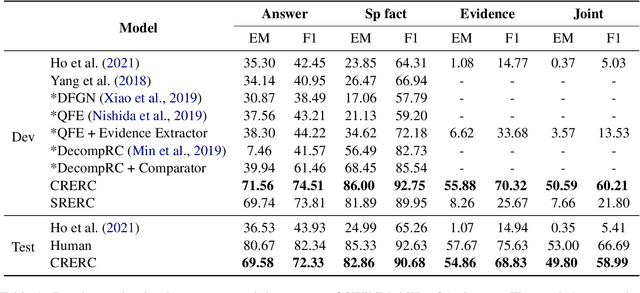
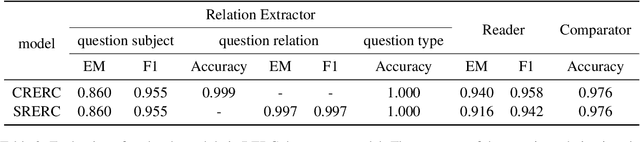
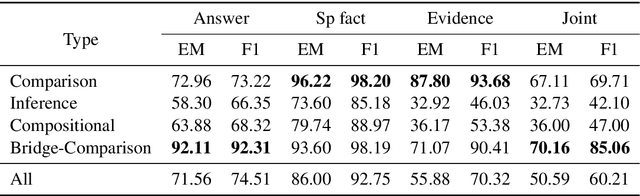
Multi-hop QA requires the machine to answer complex questions through finding multiple clues and reasoning, and provide explanatory evidence to demonstrate the machine reasoning process. We propose Relation Extractor-Reader and Comparator (RERC), a three-stage framework based on complex question decomposition, which is the first work that the RERC model has been proposed and applied in solving the multi-hop QA challenges. The Relation Extractor decomposes the complex question, and then the Reader answers the sub-questions in turn, and finally the Comparator performs numerical comparison and summarizes all to get the final answer, where the entire process itself constitutes a complete reasoning evidence path. In the 2WikiMultiHopQA dataset, our RERC model has achieved the most advanced performance, with a winning joint F1 score of 53.58 on the leaderboard. All indicators of our RERC are close to human performance, with only 1.95 behind the human level in F1 score of support fact. At the same time, the evidence path provided by our RERC framework has excellent readability and faithfulness.
Reminding the Incremental Language Model via Data-Free Self-Distillation
Oct 17, 2021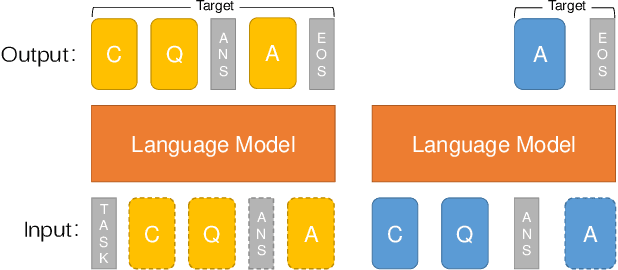
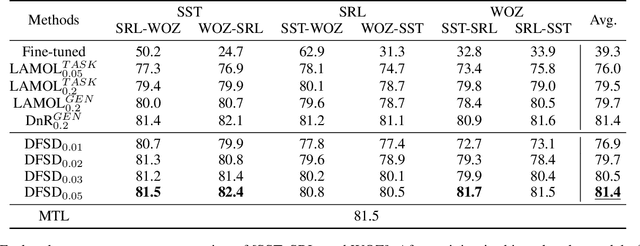
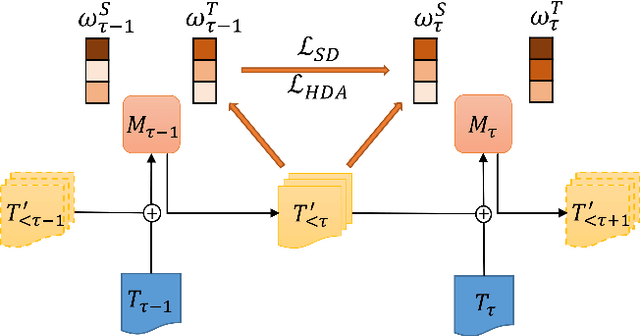

Incremental language learning with pseudo-data can alleviate catastrophic forgetting in neural networks. However, to obtain better performance, former methods have higher demands for pseudo-data of the previous tasks. The performance dramatically decreases when fewer pseudo-data are employed. In addition, the distribution of pseudo-data gradually deviates from the real data with the sequential learning of different tasks. The deviation will be greater with more tasks learned, which results in more serious catastrophic forgetting. To address these issues, we propose reminding incremental language model via data-free self-distillation (DFSD), which includes self-distillation based on the Earth Mover's Distance and hidden data augmentation. By estimating the knowledge distribution in all layers of GPT-2 and transforming it from teacher model to student model, the Self-distillation based on the Earth Mover's Distance can significantly reduce the demand for pseudo-data. Hidden data augmentation can greatly alleviate the catastrophic forgetting caused by deviations via modeling the generation of pseudo-data as a hidden data augmentation process, where each sample is a mixture of all trained task data. The experimental results demonstrate that our DFSD can exceed the previous state-of-the-art methods even if the maximum decrease in pseudo-data is 90%.