 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk Question First for Enhancing Lifelong Language Learning
Aug 17, 2022


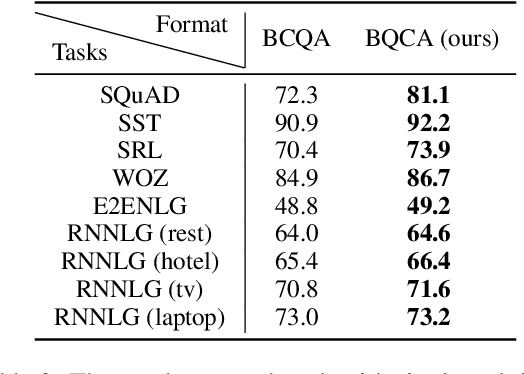
Lifelong language learning aims to stream learning NLP tasks while retaining knowledge of previous tasks. Previous works based on the language model and following data-free constraint approaches have explored formatting all data as "begin token (\textit{B}) + context (\textit{C}) + question (\textit{Q}) + answer (\textit{A})" for different tasks. However, they still suffer from catastrophic forgetting and are exacerbated when the previous task's pseudo data is insufficient for the following reasons: (1) The model has difficulty generating task-corresponding pseudo data, and (2) \textit{A} is prone to error when \textit{A} and \textit{C} are separated by \textit{Q} because the information of the \textit{C} is diminished before generating \textit{A}. Therefore, we propose the Ask Question First and Replay Question (AQF-RQ), including a novel data format "\textit{BQCA}" and a new training task to train pseudo questions of previous tasks. Experimental results demonstrate that AQF-RQ makes it easier for the model to generate more pseudo data that match corresponding tasks, and is more robust to both sufficient and insufficient pseudo-data when the task boundary is both clear and unclear. AQF-RQ can achieve only 0.36\% lower performance than multi-task learning.
RVAE-LAMOL: Residual Variational Autoencoder to Enhance Lifelong Language Learning
May 22, 2022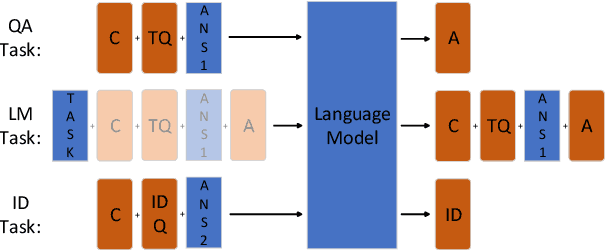
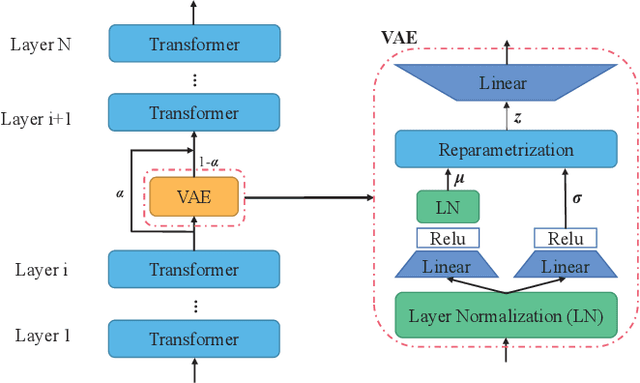
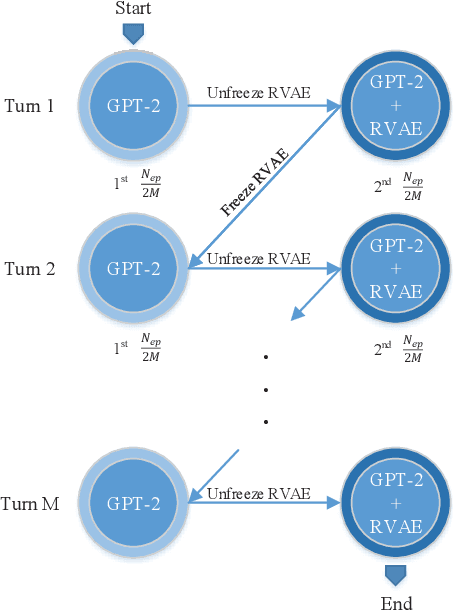

Lifelong Language Learning (LLL) aims to train a neural network to learn a stream of NLP tasks while retaining knowledge from previous tasks. However, previous works which followed data-free constraint still suffer from catastrophic forgetting issue, where the model forgets what it just learned from previous tasks. In order to alleviate catastrophic forgetting, we propose the residual variational autoencoder (RVAE) to enhance LAMOL, a recent LLL model, by mapping different tasks into a limited unified semantic space. In this space, previous tasks are easy to be correct to their own distribution by pseudo samples. Furthermore, we propose an identity task to make the model is discriminative to recognize the sample belonging to which task. For training RVAE-LAMOL better, we propose a novel training scheme Alternate Lag Training. In the experiments, we test RVAE-LAMOL on permutations of three datasets from DecaNLP. The experimental results demonstrate that RVAE-LAMOL outperforms na\"ive LAMOL on all permutations and generates more meaningful pseudo-samples.
Decomposing Complex Questions Makes Multi-Hop QA Easier and More Interpretable
Oct 26, 2021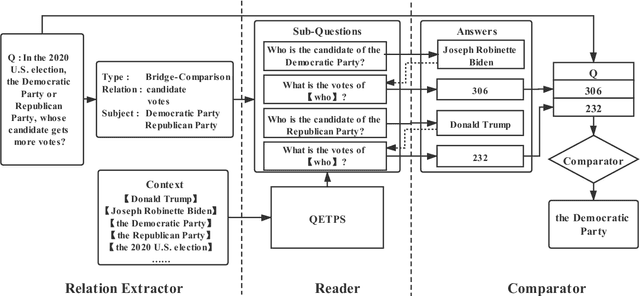
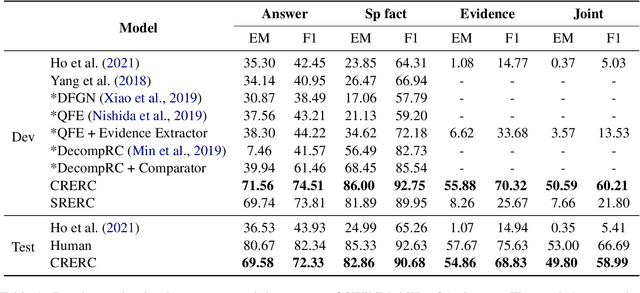
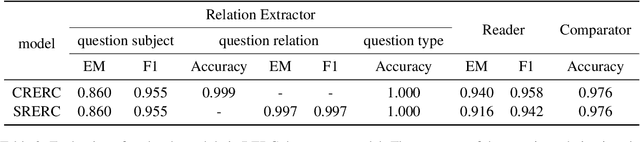
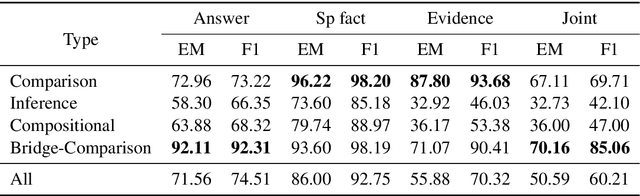
Multi-hop QA requires the machine to answer complex questions through finding multiple clues and reasoning, and provide explanatory evidence to demonstrate the machine reasoning process. We propose Relation Extractor-Reader and Comparator (RERC), a three-stage framework based on complex question decomposition, which is the first work that the RERC model has been proposed and applied in solving the multi-hop QA challenges. The Relation Extractor decomposes the complex question, and then the Reader answers the sub-questions in turn, and finally the Comparator performs numerical comparison and summarizes all to get the final answer, where the entire process itself constitutes a complete reasoning evidence path. In the 2WikiMultiHopQA dataset, our RERC model has achieved the most advanced performance, with a winning joint F1 score of 53.58 on the leaderboard. All indicators of our RERC are close to human performance, with only 1.95 behind the human level in F1 score of support fact. At the same time, the evidence path provided by our RERC framework has excellent readability and faithfulness.
Reminding the Incremental Language Model via Data-Free Self-Distillation
Oct 17, 2021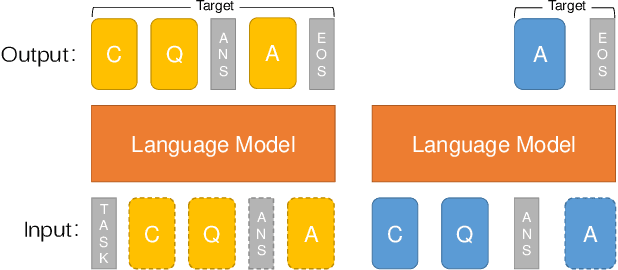
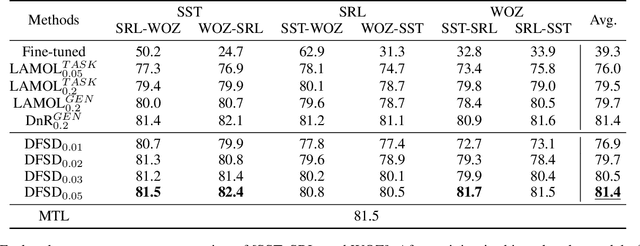
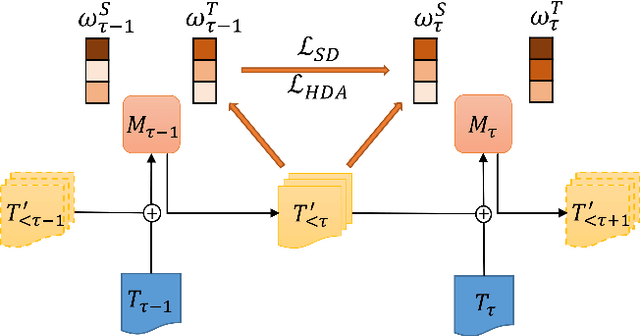

Incremental language learning with pseudo-data can alleviate catastrophic forgetting in neural networks. However, to obtain better performance, former methods have higher demands for pseudo-data of the previous tasks. The performance dramatically decreases when fewer pseudo-data are employed. In addition, the distribution of pseudo-data gradually deviates from the real data with the sequential learning of different tasks. The deviation will be greater with more tasks learned, which results in more serious catastrophic forgetting. To address these issues, we propose reminding incremental language model via data-free self-distillation (DFSD), which includes self-distillation based on the Earth Mover's Distance and hidden data augmentation. By estimating the knowledge distribution in all layers of GPT-2 and transforming it from teacher model to student model, the Self-distillation based on the Earth Mover's Distance can significantly reduce the demand for pseudo-data. Hidden data augmentation can greatly alleviate the catastrophic forgetting caused by deviations via modeling the generation of pseudo-data as a hidden data augmentation process, where each sample is a mixture of all trained task data. The experimental results demonstrate that our DFSD can exceed the previous state-of-the-art methods even if the maximum decrease in pseudo-data is 90%.