 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransliterated Zero-Shot Domain Adaptation for Automatic Speech Recognition
Dec 15, 2024
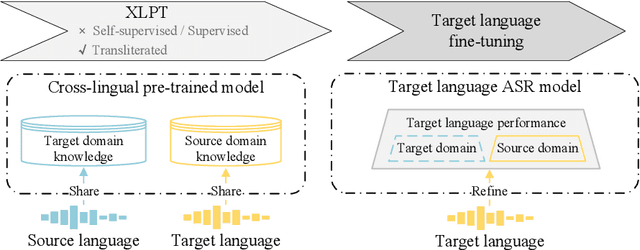
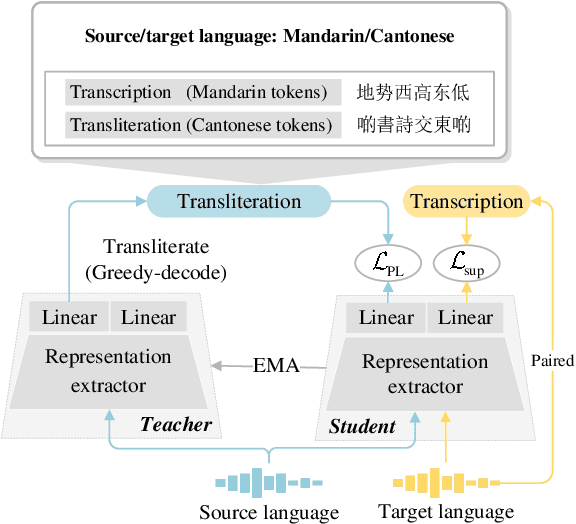
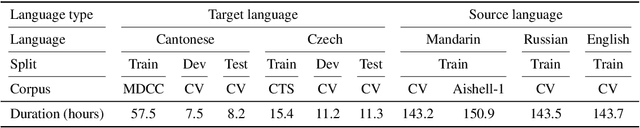
The performance of automatic speech recognition models often degenerates on domains not covered by the training data. Domain adaptation can address this issue, assuming the availability of the target domain data in the target language. However, such assumption does not stand in many real-world applications. To make domain adaptation more applicable, we address the problem of zero-shot domain adaptation (ZSDA), where target domain data is unavailable in the target language. Instead, we transfer the target domain knowledge from another source language where the target domain data is more accessible. To do that, we first perform cross-lingual pre-training (XLPT) to share domain knowledge across languages, then use target language fine-tuning to build the final model. One challenge in this practice is that the pre-trained knowledge can be forgotten during fine-tuning, resulting in sub-optimal adaptation performance. To address this issue, we propose transliterated ZSDA to achieve consistent pre-training and fine-tuning labels, leading to maximum preservation of the pre-trained knowledge. Experimental results show that transliterated ZSDA relatively decreases the word error rate by 9.2% compared with a wav2vec 2.0 baseline. Moreover, transliterated ZSDA consistently outperforms self-supervised ZSDA and performs on par with supervised ZSDA, proving the superiority of transliteration-based pre-training labels.
Ask Question First for Enhancing Lifelong Language Learning
Aug 17, 2022


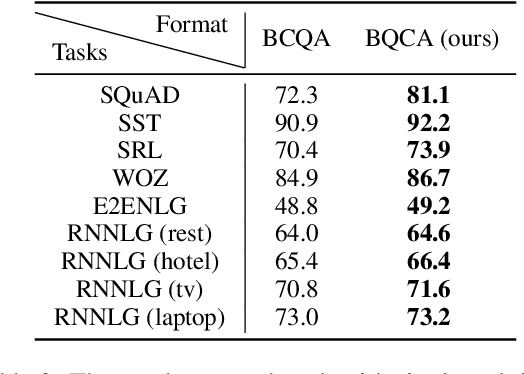
Lifelong language learning aims to stream learning NLP tasks while retaining knowledge of previous tasks. Previous works based on the language model and following data-free constraint approaches have explored formatting all data as "begin token (\textit{B}) + context (\textit{C}) + question (\textit{Q}) + answer (\textit{A})" for different tasks. However, they still suffer from catastrophic forgetting and are exacerbated when the previous task's pseudo data is insufficient for the following reasons: (1) The model has difficulty generating task-corresponding pseudo data, and (2) \textit{A} is prone to error when \textit{A} and \textit{C} are separated by \textit{Q} because the information of the \textit{C} is diminished before generating \textit{A}. Therefore, we propose the Ask Question First and Replay Question (AQF-RQ), including a novel data format "\textit{BQCA}" and a new training task to train pseudo questions of previous tasks. Experimental results demonstrate that AQF-RQ makes it easier for the model to generate more pseudo data that match corresponding tasks, and is more robust to both sufficient and insufficient pseudo-data when the task boundary is both clear and unclear. AQF-RQ can achieve only 0.36\% lower performance than multi-task learning.
Data Augmentation based Consistency Contrastive Pre-training for Automatic Speech Recognition
Dec 23, 2021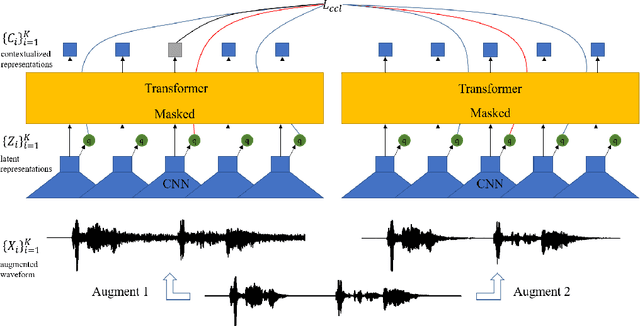
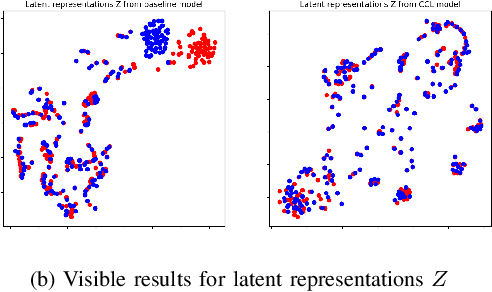
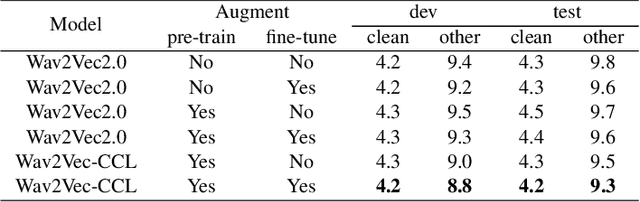
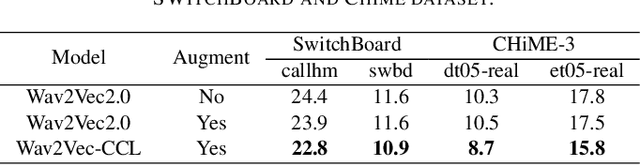
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.