 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation based Consistency Contrastive Pre-training for Automatic Speech Recognition
Paper and Code
Dec 23, 2021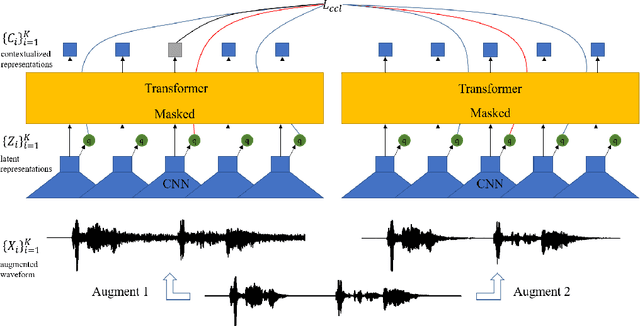
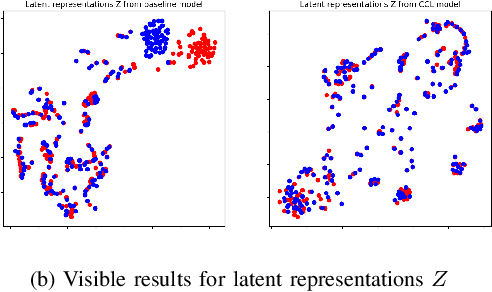
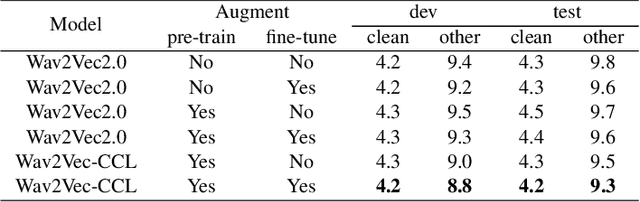
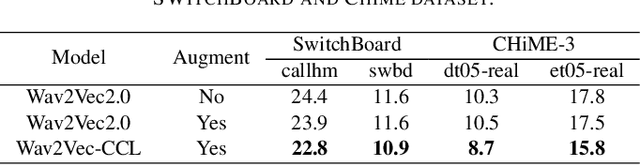
Self-supervised acoustic pre-training has achieved amazing results on the automatic speech recognition (ASR) task. Most of the successful acoustic pre-training methods use contrastive learning to learn the acoustic representations by distinguish the representations from different time steps, ignoring the speaker and environment robustness. As a result, the pre-trained model could show poor performance when meeting out-of-domain data during fine-tuning. In this letter, we design a novel consistency contrastive learning (CCL) method by utilizing data augmentation for acoustic pre-training. Different kinds of augmentation are applied on the original audios and then the augmented audios are fed into an encoder. The encoder should not only contrast the representations within one audio but also maximize the measurement of the representations across different augmented audios. By this way, the pre-trained model can learn a text-related representation method which is more robust with the change of the speaker or the environment.Experiments show that by applying the CCL method on the Wav2Vec2.0, better results can be realized both on the in-domain data and the out-of-domain data. Especially for noisy out-of-domain data, more than 15% relative improvement can be obtained.