 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmilia: A Large-Scale, Extensive, Multilingual, and Diverse Dataset for Speech Generation
Jan 27, 2025Recent advancements in speech generation have been driven by the large-scale training datasets. However, current models fall short of capturing the spontaneity and variability inherent in real-world human speech, due to their reliance on audiobook datasets limited to formal read-aloud speech styles. To bridge this gap, we introduce Emilia-Pipe, an open-source preprocessing pipeline to extract high-quality training data from valuable yet underexplored in-the-wild data that capture spontaneous human speech in real-world contexts. By leveraging Emilia-Pipe, we construct Emilia, the first multilingual speech generation dataset derived from in-the-wild speech data. This dataset comprises over 101k hours of speech across six languages: English, Chinese, German, French, Japanese, and Korean. Besides, we expand Emilia to Emilia-Large, a dataset exceeding 216k hours, making it the largest open-source speech generation dataset available. Extensive experiments demonstrate that Emilia significantly outperforms traditional audiobook datasets in generating spontaneous and human-like speech, showcasing superior performance in capturing diverse speaker timbre and speaking styles of real-world human speech. Furthermore, this work underscores the importance of scaling dataset size to advance speech generation research and validates the effectiveness of Emilia for both multilingual and crosslingual speech generation.
Controlling your Attributes in Voice
Jan 03, 2025Attribute control in generative tasks aims to modify personal attributes, such as age and gender while preserving the identity information in the source sample. Although significant progress has been made in controlling facial attributes in image generation, similar approaches for speech generation remain largely unexplored. This letter proposes a novel method for controlling speaker attributes in speech without parallel data. Our approach consists of two main components: a GAN-based speaker representation variational autoencoder that extracts speaker identity and attributes from speaker vector, and a two-stage voice conversion model that captures the natural expression of speaker attributes in speech. Experimental results show that our proposed method not only achieves attribute control at the speaker representation level but also enables manipulation of the speaker age and gender at the speech level while preserving speech quality and speaker identity.
SLIDE: Integrating Speech Language Model with LLM for Spontaneous Spoken Dialogue Generation
Jan 01, 2025



Recently, ``textless" speech language models (SLMs) based on speech units have made huge progress in generating naturalistic speech, including non-verbal vocalizations. However, the generated speech samples often lack semantic coherence. In this paper, we propose SLM and LLM Integration for spontaneous spoken Dialogue gEneration (SLIDE). Specifically, we first utilize an LLM to generate the textual content of spoken dialogue. Next, we convert the textual dialogues into phoneme sequences and use a two-tower transformer-based duration predictor to predict the duration of each phoneme. Finally, an SLM conditioned on the spoken phoneme sequences is used to vocalize the textual dialogue. Experimental results on the Fisher dataset demonstrate that our system can generate naturalistic spoken dialogue while maintaining high semantic coherence.
Transliterated Zero-Shot Domain Adaptation for Automatic Speech Recognition
Dec 15, 2024
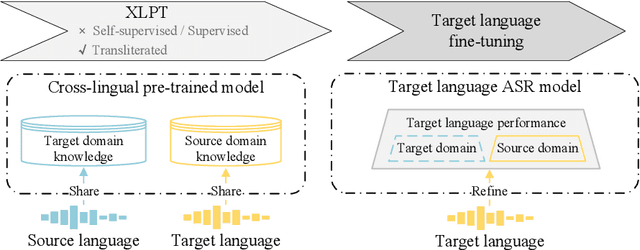
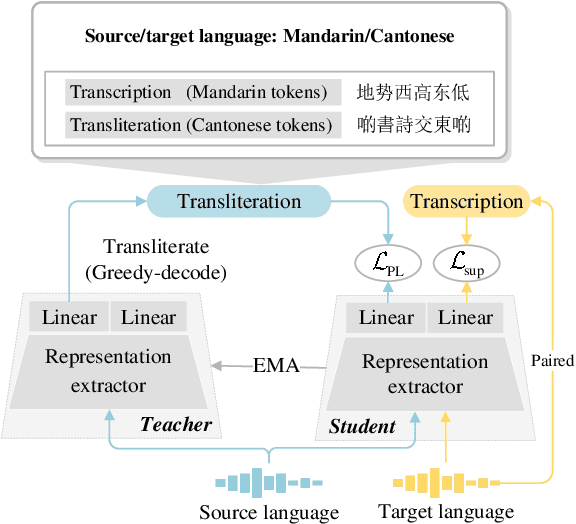
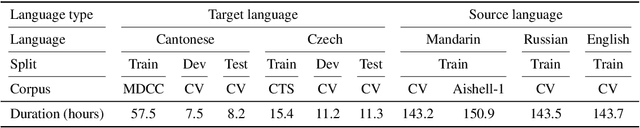
The performance of automatic speech recognition models often degenerates on domains not covered by the training data. Domain adaptation can address this issue, assuming the availability of the target domain data in the target language. However, such assumption does not stand in many real-world applications. To make domain adaptation more applicable, we address the problem of zero-shot domain adaptation (ZSDA), where target domain data is unavailable in the target language. Instead, we transfer the target domain knowledge from another source language where the target domain data is more accessible. To do that, we first perform cross-lingual pre-training (XLPT) to share domain knowledge across languages, then use target language fine-tuning to build the final model. One challenge in this practice is that the pre-trained knowledge can be forgotten during fine-tuning, resulting in sub-optimal adaptation performance. To address this issue, we propose transliterated ZSDA to achieve consistent pre-training and fine-tuning labels, leading to maximum preservation of the pre-trained knowledge. Experimental results show that transliterated ZSDA relatively decreases the word error rate by 9.2% compared with a wav2vec 2.0 baseline. Moreover, transliterated ZSDA consistently outperforms self-supervised ZSDA and performs on par with supervised ZSDA, proving the superiority of transliteration-based pre-training labels.
SF-Speech: Straightened Flow for Zero-Shot Voice Clone on Small-Scale Dataset
Oct 16, 2024



Large-scale speech generation models have achieved impressive performance in the zero-shot voice clone tasks relying on large-scale datasets. However, exploring how to achieve zero-shot voice clone with small-scale datasets is also essential. This paper proposes SF-Speech, a novel state-of-the-art voice clone model based on ordinary differential equations and contextual learning. Unlike the previous works, SF-Speech employs a multi-stage generation strategy to obtain the coarse acoustic feature and utilizes this feature to straighten the curved reverse trajectories caused by training the ordinary differential equation model with flow matching. In addition, we find the difference between the local correlations of different types of acoustic features and demonstrate the potential role of 2D convolution in modeling mel-spectrogram features. After training with less than 1000 hours of speech, SF-Speech significantly outperforms those methods based on global speaker embedding or autoregressive large language models. In particular, SF-Speech also shows a significant advantage over VoiceBox, the best-performing ordinary differential equation model, in speech intelligibility (a relative decrease of 22.4\% on word error rate) and timbre similarity (a relative improvement of 5.6\% on cosine distance) at a similar scale of parameters, and even keep a slight advantage when the parameters of VoiceBox are tripled.
Emilia: An Extensive, Multilingual, and Diverse Speech Dataset for Large-Scale Speech Generation
Jul 07, 2024



Recently, speech generation models have made significant progress by using large-scale training data. However, the research community struggle to produce highly spontaneous and human-like speech due to the lack of large-scale, diverse, and spontaneous speech data. This paper presents \textit{Emilia}, the first multilingual speech generation dataset from in-the-wild speech data, and Emilia-Pipe, the first open-source preprocessing pipeline designed to transform in-the-wild speech data into high-quality training data with annotations for speech generation. Emilia starts with over 101k hours of speech in six languages and features diverse speech with varied speaking styles. To facilitate the scale-up of Emilia, the open-source pipeline Emilia-Pipe can process one hour of raw speech data ready for model training in a few mins, which enables the research community to collaborate on large-scale speech generation research. Experimental results validate the effectiveness of Emilia. Demos are available at: https://emilia-dataset.github.io/Emilia-Demo-Page/.
TRNet: Two-level Refinement Network leveraging Speech Enhancement for Noise Robust Speech Emotion Recognition
Apr 19, 2024



One persistent challenge in Speech Emotion Recognition (SER) is the ubiquitous environmental noise, which frequently results in diminished SER performance in practical use. In this paper, we introduce a Two-level Refinement Network, dubbed TRNet, to address this challenge. Specifically, a pre-trained speech enhancement module is employed for front-end noise reduction and noise level estimation. Later, we utilize clean speech spectrograms and their corresponding deep representations as reference signals to refine the spectrogram distortion and representation shift of enhanced speech during model training. Experimental results validate that the proposed TRNet substantially increases the system's robustness in both matched and unmatched noisy environments, without compromising its performance in clean environments.
Modality-Collaborative Transformer with Hybrid Feature Reconstruction for Robust Emotion Recognition
Dec 26, 2023As a vital aspect of affective computing, Multimodal Emotion Recognition has been an active research area in the multimedia community. Despite recent progress, this field still confronts two major challenges in real-world applications: 1) improving the efficiency of constructing joint representations from unaligned multimodal features, and 2) relieving the performance decline caused by random modality feature missing. In this paper, we propose a unified framework, Modality-Collaborative Transformer with Hybrid Feature Reconstruction (MCT-HFR), to address these issues. The crucial component of MCT is a novel attention-based encoder which concurrently extracts and dynamically balances the intra- and inter-modality relations for all associated modalities. With additional modality-wise parameter sharing, a more compact representation can be encoded with less time and space complexity. To improve the robustness of MCT, we further introduce HFR which consists of two modules: Local Feature Imagination (LFI) and Global Feature Alignment (GFA). During model training, LFI leverages complete features as supervisory signals to recover local missing features, while GFA is designed to reduce the global semantic gap between pairwise complete and incomplete representations. Experimental evaluations on two popular benchmark datasets demonstrate that our proposed method consistently outperforms advanced baselines in both complete and incomplete data scenarios.
DSNet: Disentangled Siamese Network with Neutral Calibration for Speech Emotion Recognition
Dec 25, 2023One persistent challenge in deep learning based speech emotion recognition (SER) is the unconscious encoding of emotion-irrelevant factors (e.g., speaker or phonetic variability), which limits the generalization of SER in practical use. In this paper, we propose DSNet, a Disentangled Siamese Network with neutral calibration, to meet the demand for a more robust and explainable SER model. Specifically, we introduce an orthogonal feature disentanglement module to explicitly project the high-level representation into two distinct subspaces. Later, we propose a novel neutral calibration mechanism to encourage one subspace to capture sufficient emotion-irrelevant information. In this way, the other one can better isolate and emphasize the emotion-relevant information within speech signals. Experimental results on two popular benchmark datasets demonstrate the superiority of DSNet over various state-of-the-art methods for speaker-independent SER.
Enhancing Spoofing Speech Detection Using Rhythm Information
Oct 18, 2023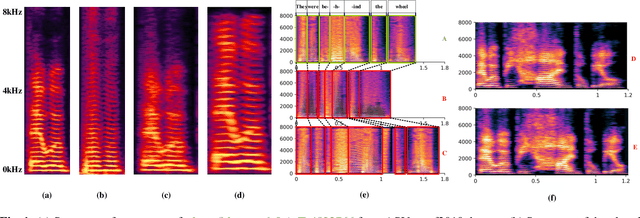
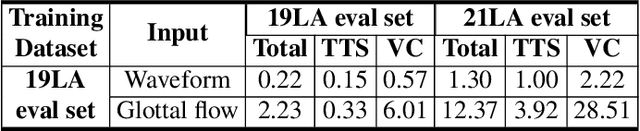
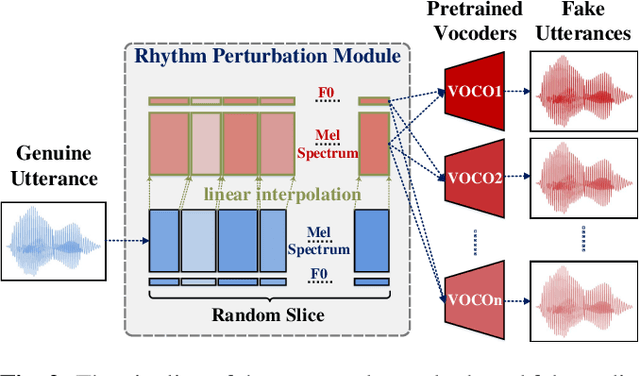
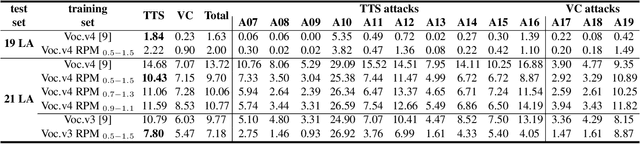
Spoofing speech detection is a hot and in-demand research field. However, current spoofing speech detection systems is lack of convincing evidence. In this paper, to increase the reliability of detection systems, the flaws of rhythm information inherent in the TTS-generated speech are analyzed. TTS models take text as input and utilize acoustic models to predict rhythm information, which introduces artifacts in the rhythm information. By filtering out vocal tract response, the remaining glottal flow with rhythm information retains detection ability for TTS-generated speech. Based on these analyses, a rhythm perturbation module is proposed to enhance the copy-synthesis data augmentation method. Fake utterances generated by the proposed method force the detecting model to pay attention to the artifacts in rhythm information and effectively improve the ability to detect TTS-generated speech of the anti-spoofing countermeasures.