 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spoofing Speech Detection Using Rhythm Information
Oct 18, 2023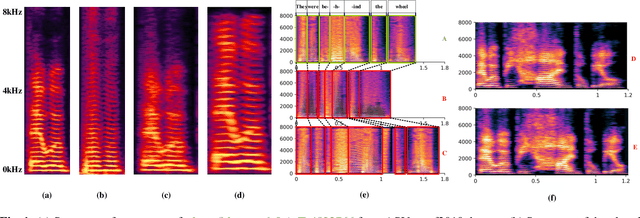
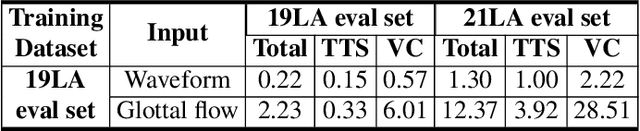
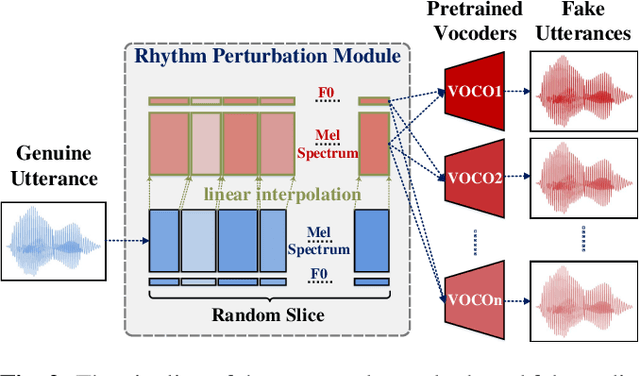
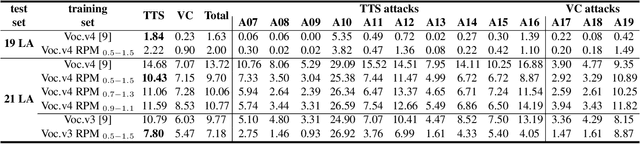
Spoofing speech detection is a hot and in-demand research field. However, current spoofing speech detection systems is lack of convincing evidence. In this paper, to increase the reliability of detection systems, the flaws of rhythm information inherent in the TTS-generated speech are analyzed. TTS models take text as input and utilize acoustic models to predict rhythm information, which introduces artifacts in the rhythm information. By filtering out vocal tract response, the remaining glottal flow with rhythm information retains detection ability for TTS-generated speech. Based on these analyses, a rhythm perturbation module is proposed to enhance the copy-synthesis data augmentation method. Fake utterances generated by the proposed method force the detecting model to pay attention to the artifacts in rhythm information and effectively improve the ability to detect TTS-generated speech of the anti-spoofing countermeasures.
Synthetic Speech Detection Based on Temporal Consistency and Distribution of Speaker Features
Sep 29, 2023Current synthetic speech detection (SSD) methods perform well on certain datasets but still face issues of robustness and interpretability. A possible reason is that these methods do not analyze the deficiencies of synthetic speech. In this paper, the flaws of the speaker features inherent in the text-to-speech (TTS) process are analyzed. Differences in the temporal consistency of intra-utterance speaker features arise due to the lack of fine-grained control over speaker features in TTS. Since the speaker representations in TTS are based on speaker embeddings extracted by encoders, the distribution of inter-utterance speaker features differs between synthetic and bonafide speech. Based on these analyzes, an SSD method based on temporal consistency and distribution of speaker features is proposed. On one hand, modeling the temporal consistency of intra-utterance speaker features can aid speech anti-spoofing. On the other hand, distribution differences in inter-utterance speaker features can be utilized for SSD. The proposed method offers low computational complexity and performs well in both cross-dataset and silence trimming scenarios.
The Impact of Silence on Speech Anti-Spoofing
Sep 21, 2023The current speech anti-spoofing countermeasures (CMs) show excellent performance on specific datasets. However, removing the silence of test speech through Voice Activity Detection (VAD) can severely degrade performance. In this paper, the impact of silence on speech anti-spoofing is analyzed. First, the reasons for the impact are explored, including the proportion of silence duration and the content of silence. The proportion of silence duration in spoof speech generated by text-to-speech (TTS) algorithms is lower than that in bonafide speech. And the content of silence generated by different waveform generators varies compared to bonafide speech. Then the impact of silence on model prediction is explored. Even after retraining, the spoof speech generated by neural network based end-to-end TTS algorithms suffers a significant rise in error rates when the silence is removed. To demonstrate the reasons for the impact of silence on CMs, the attention distribution of a CM is visualized through class activation mapping (CAM). Furthermore, the implementation and analysis of the experiments masking silence or non-silence demonstrates the significance of the proportion of silence duration for detecting TTS and the importance of silence content for detecting voice conversion (VC). Based on the experimental results, improving the robustness of CMs against unknown spoofing attacks by masking silence is also proposed. Finally, the attacks on anti-spoofing CMs through concatenating silence, and the mitigation of VAD and silence attack through low-pass filtering are introduced.
One-Class Knowledge Distillation for Spoofing Speech Detection
Sep 15, 2023The detection of spoofing speech generated by unseen algorithms remains an unresolved challenge. One reason for the lack of generalization ability is traditional detecting systems follow the binary classification paradigm, which inherently assumes the possession of prior knowledge of spoofing speech. One-class methods attempt to learn the distribution of bonafide speech and are inherently suited to the task where spoofing speech exhibits significant differences. However, training a one-class system using only bonafide speech is challenging. In this paper, we introduce a teacher-student framework to provide guidance for the training of a one-class model. The proposed one-class knowledge distillation method outperforms other state-of-the-art methods on the ASVspoof 21DF dataset and InTheWild dataset, which demonstrates its superior generalization ability.
Improving Short Utterance Anti-Spoofing with AASIST2
Sep 15, 2023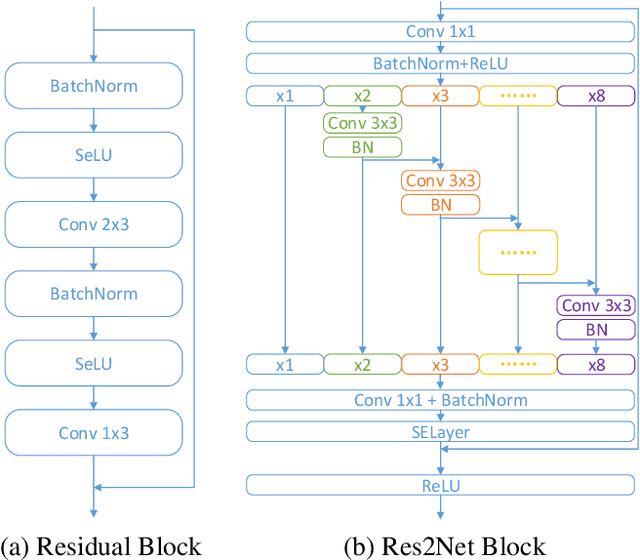

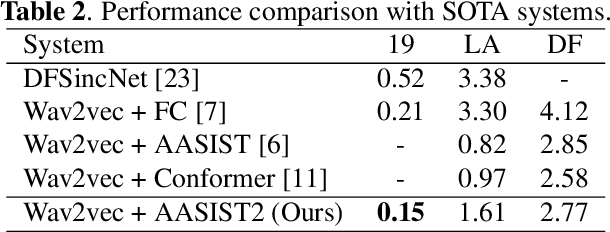
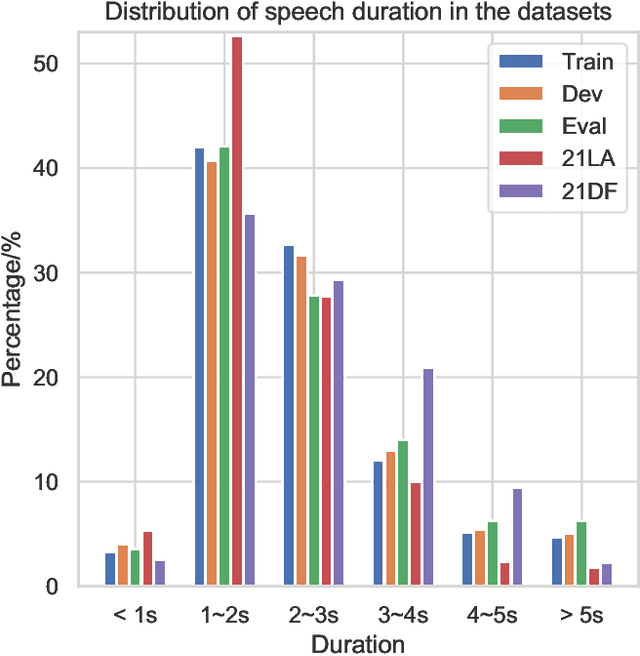
The wav2vec 2.0 and integrated spectro-temporal graph attention network (AASIST) based countermeasure achieves great performance in speech anti-spoofing. However, current spoof speech detection systems have fixed training and evaluation durations, while the performance degrades significantly during short utterance evaluation. To solve this problem, AASIST can be improved to AASIST2 by modifying the residual blocks to Res2Net blocks. The modified Res2Net blocks can extract multi-scale features and improve the detection performance for speech of different durations, thus improving the short utterance evaluation performance. On the other hand, adaptive large margin fine-tuning (ALMFT) has achieved performance improvement in short utterance speaker verification. Therefore, we apply Dynamic Chunk Size (DCS) and ALMFT training strategies in speech anti-spoofing to further improve the performance of short utterance evaluation. Experiments demonstrate that the proposed AASIST2 improves the performance of short utterance evaluation while maintaining the performance of regular evaluation on different datasets.
Progressive Sub-Graph Clustering Algorithm for Semi-Supervised Domain Adaptation Speaker Verification
May 22, 2023Utilizing the large-scale unlabeled data from the target domain via pseudo-label clustering algorithms is an important approach for addressing domain adaptation problems in speaker verification tasks. In this paper, we propose a novel progressive subgraph clustering algorithm based on multi-model voting and double-Gaussian based assessment (PGMVG clustering). To fully exploit the relationships among utterances and the complementarity among multiple models, our method constructs multiple k-nearest neighbors graphs based on diverse models and generates high-confidence edges using a voting mechanism. Further, to maximize the intra-class diversity, the connected subgraph is utilized to obtain the initial pseudo-labels. Finally, to prevent disastrous clustering results, we adopt an iterative approach that progressively increases k and employs a double-Gaussian based assessment algorithm to decide whether merging sub-classes.
Deepfake Detection System for the ADD Challenge Track 3.2 Based on Score Fusion
Oct 13, 2022
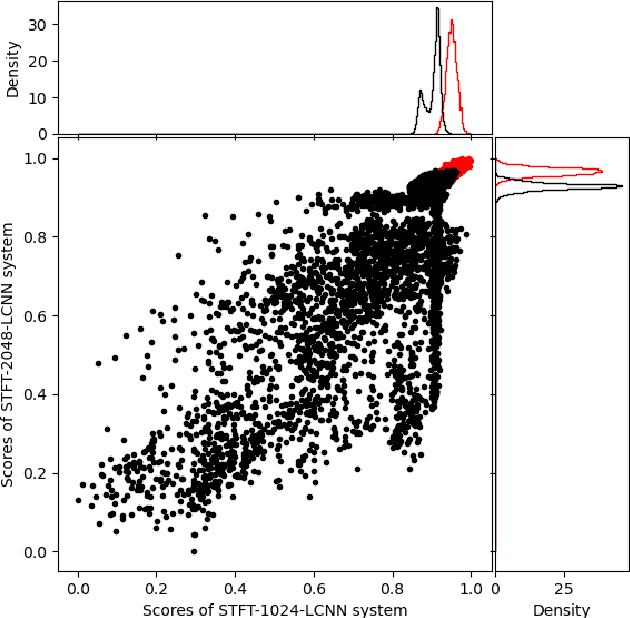
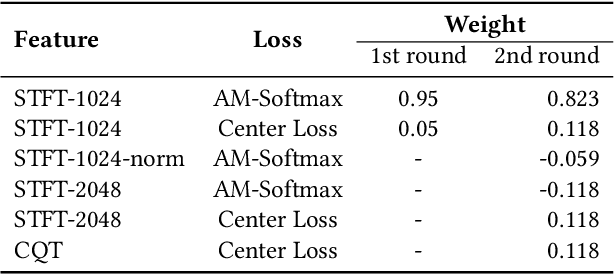
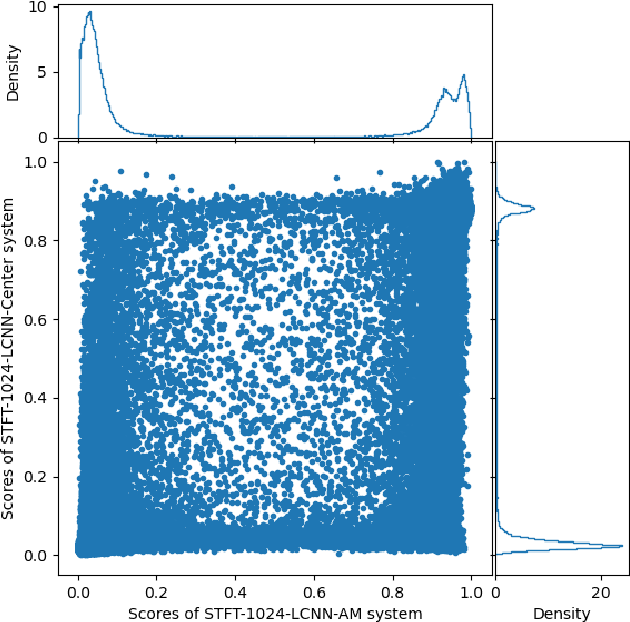
This paper describes the deepfake audio detection system submitted to the Audio Deep Synthesis Detection (ADD) Challenge Track 3.2 and gives an analysis of score fusion. The proposed system is a score-level fusion of several light convolutional neural network (LCNN) based models. Various front-ends are used as input features, including low-frequency short-time Fourier transform and Constant Q transform. Due to the complex noise and rich synthesis algorithms, it is difficult to obtain the desired performance using the training set directly. Online data augmentation methods effectively improve the robustness of fake audio detection systems. In particular, the reasons for the poor improvement of score fusion are explored through visualization of the score distributions and comparison with score distribution on another dataset. The overfitting of the model to the training set leads to extreme values of the scores and low correlation of the score distributions, which makes score fusion difficult. Fusion with partially fake audio detection system improves system performance further. The submission on track 3.2 obtained the weighted equal error rate (WEER) of 11.04\%, which is one of the best performing systems in the challenge.