 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Spoofing Speech Detection Using Rhythm Information
Paper and Code
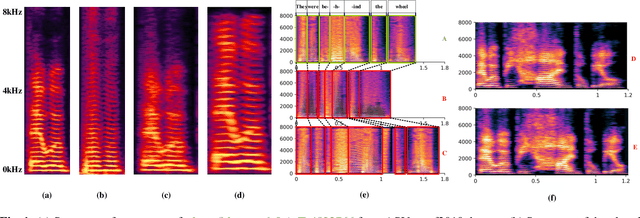
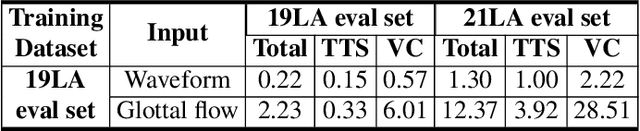
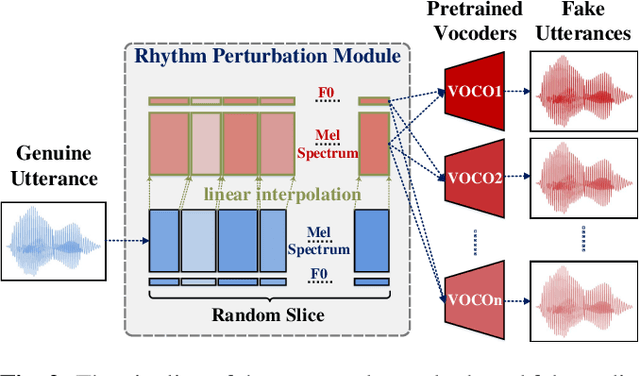
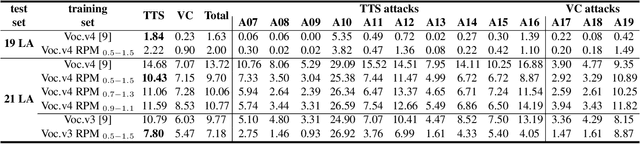
Spoofing speech detection is a hot and in-demand research field. However, current spoofing speech detection systems is lack of convincing evidence. In this paper, to increase the reliability of detection systems, the flaws of rhythm information inherent in the TTS-generated speech are analyzed. TTS models take text as input and utilize acoustic models to predict rhythm information, which introduces artifacts in the rhythm information. By filtering out vocal tract response, the remaining glottal flow with rhythm information retains detection ability for TTS-generated speech. Based on these analyses, a rhythm perturbation module is proposed to enhance the copy-synthesis data augmentation method. Fake utterances generated by the proposed method force the detecting model to pay attention to the artifacts in rhythm information and effectively improve the ability to detect TTS-generated speech of the anti-spoofing countermeasures.