 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe HCCL system for VoxCeleb Speaker Recognition Challenge 2022
May 22, 2023
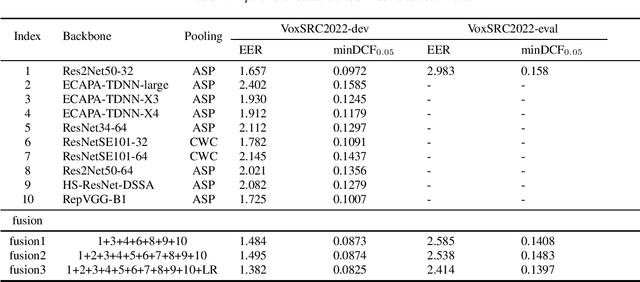


This report describes our submission to track1 and track3 for VoxCeleb Speaker Recognition Challenge 2022(VoxSRC2022). Our best system achieves minDCF 0.1397 and EER 2.414 in track1, minDCF 0.388 and EER 7.030 in track3.
Progressive Sub-Graph Clustering Algorithm for Semi-Supervised Domain Adaptation Speaker Verification
May 22, 2023Utilizing the large-scale unlabeled data from the target domain via pseudo-label clustering algorithms is an important approach for addressing domain adaptation problems in speaker verification tasks. In this paper, we propose a novel progressive subgraph clustering algorithm based on multi-model voting and double-Gaussian based assessment (PGMVG clustering). To fully exploit the relationships among utterances and the complementarity among multiple models, our method constructs multiple k-nearest neighbors graphs based on diverse models and generates high-confidence edges using a voting mechanism. Further, to maximize the intra-class diversity, the connected subgraph is utilized to obtain the initial pseudo-labels. Finally, to prevent disastrous clustering results, we adopt an iterative approach that progressively increases k and employs a double-Gaussian based assessment algorithm to decide whether merging sub-classes.
PCF: ECAPA-TDNN with Progressive Channel Fusion for Speaker Verification
Mar 01, 2023ECAPA-TDNN is currently the most popular TDNN-series model for speaker verification, which refreshed the state-of-the-art(SOTA) performance of TDNN models. However, one-dimensional convolution has a global receptive field over the feature channel. It destroys the time-frequency relevance of the spectrogram. Besides, as ECAPA-TDNN only has five layers, a much shallower structure compared to ResNet restricts the capability to generate deep representations. To further improve ECAPA-TDNN, we propose a progressive channel fusion strategy that splits the spectrogram across the feature channel and gradually expands the receptive field through the network. Secondly, we enlarge the model by extending the depth and adding branches. Our proposed model achieves EER with 0.718 and minDCF(0.01) with 0.0858 on vox1o, relatively improved 16.1\% and 19.5\% compared with ECAPA-TDNN-large.
The HCCL System for the NIST SRE21
Jul 11, 2022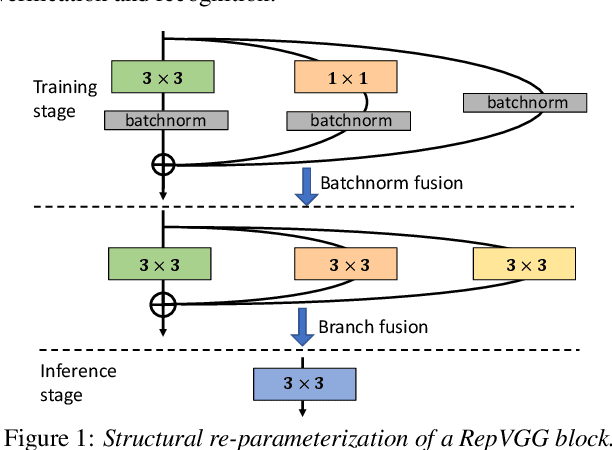
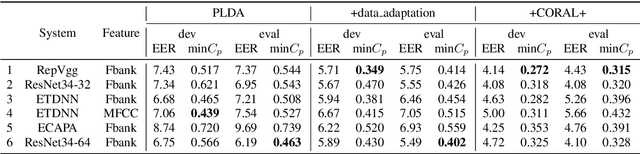
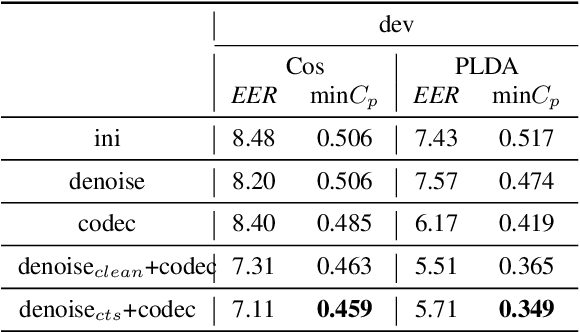
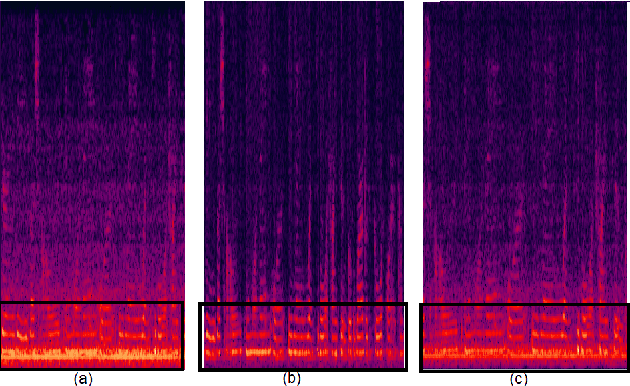
This paper describes the systems developed by the HCCL team for the NIST 2021 speaker recognition evaluation (NIST SRE21).We first explore various state-of-the-art speaker embedding extractors combined with a novel circle loss to obtain discriminative deep speaker embeddings. Considering that cross-channel and cross-linguistic speaker recognition are the key challenges of SRE21, we introduce several techniques to reduce the cross-domain mismatch. Specifically, Codec and speech enhancement are directly applied to the raw speech to eliminate the codecs and the environment noise mismatch. We denote the methods that work directly on speech to eliminate the relatively explicit mismatches collectively as data adaptation methods. Experiments show that data adaption methods achieve 15\% improvements over our baseline. Furthermore, some popular back-ends domain adaptation algorithms are deployed on speaker embeddings to alleviate speaker performance degradation caused by the implicit mismatch. Score calibration is a major failure for us in SRE21. The reason is that score calibration with too many parameters easily lead to overfitting problems.
Back-ends Selection for Deep Speaker Embeddings
Apr 25, 2022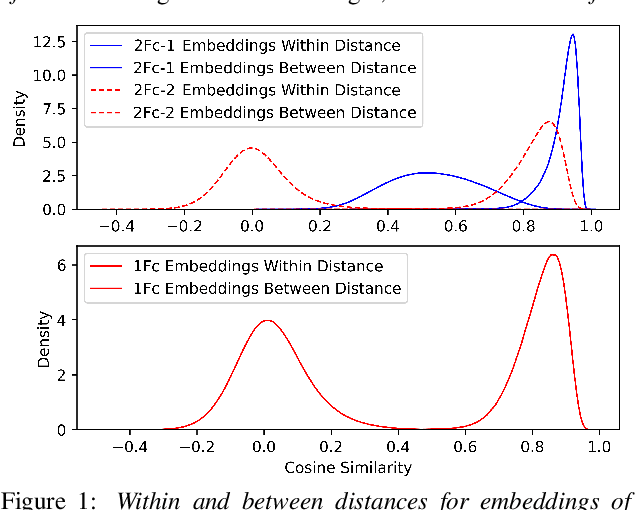
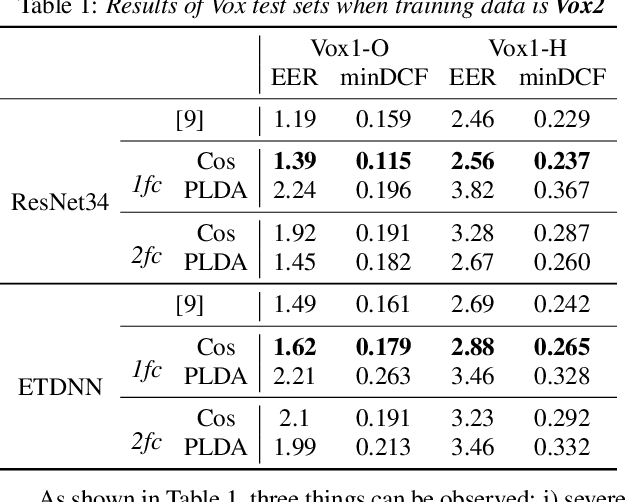
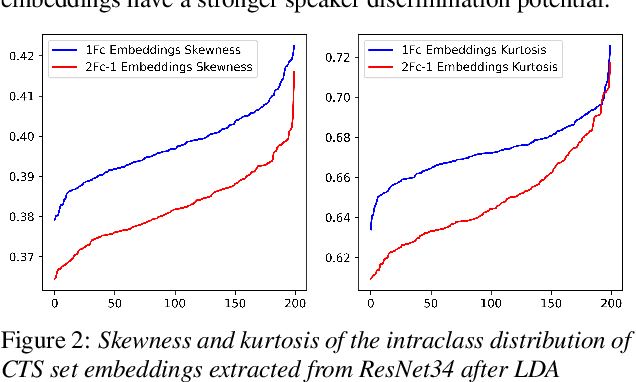
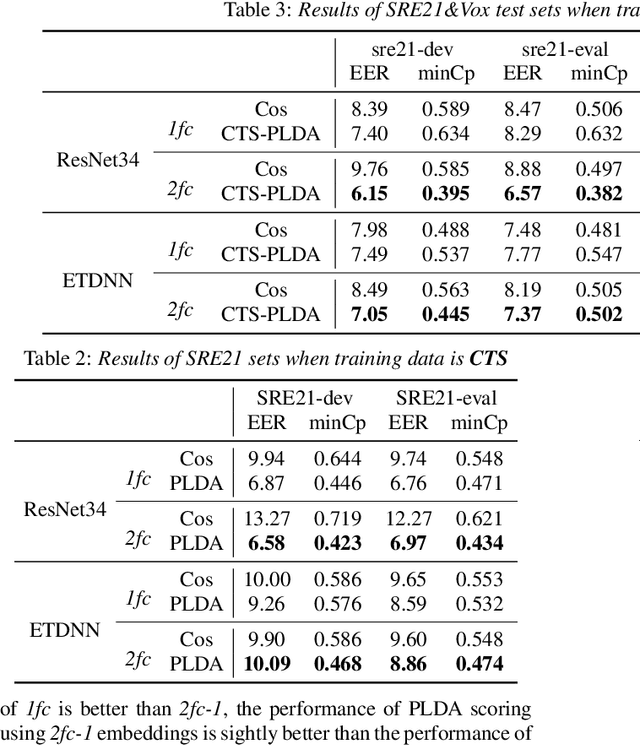
Probabilistic Linear Discriminant Analysis (PLDA) was the dominant and necessary back-end for early speaker recognition approaches, like i-vector and x-vector. However, with the development of neural networks and margin-based loss functions, we can obtain deep speaker embeddings (DSEs), which have advantages of increased inter-class separation and smaller intra-class distances. In this case, PLDA seems unnecessary or even counterproductive for the discriminative embeddings, and cosine similarity scoring (Cos) achieves better performance than PLDA in some situations. Motivated by this, in this paper, we systematically explore how to select back-ends (Cos or PLDA) for deep speaker embeddings to achieve better performance in different situations. By analyzing PLDA and the properties of DSEs extracted from models with different numbers of segment-level layers, we make the conjecture that Cos is better in same-domain situations and PLDA is better in cross-domain situations. We conduct experiments on VoxCeleb and NIST SRE datasets in four application situations, single-/multi-domain training and same-/cross-domain test, to validate our conjecture and briefly explain why back-ends adaption algorithms work.