 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe HCCL System for the NIST SRE21
Paper and Code
Jul 11, 2022
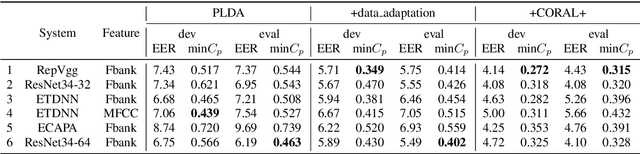
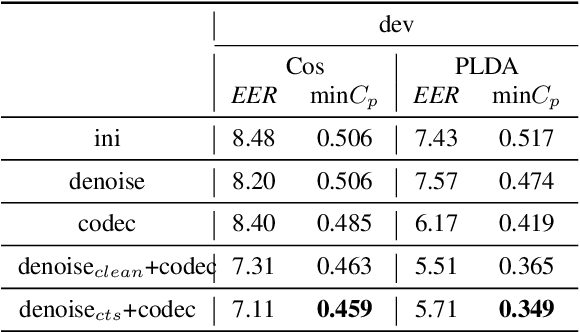
This paper describes the systems developed by the HCCL team for the NIST 2021 speaker recognition evaluation (NIST SRE21).We first explore various state-of-the-art speaker embedding extractors combined with a novel circle loss to obtain discriminative deep speaker embeddings. Considering that cross-channel and cross-linguistic speaker recognition are the key challenges of SRE21, we introduce several techniques to reduce the cross-domain mismatch. Specifically, Codec and speech enhancement are directly applied to the raw speech to eliminate the codecs and the environment noise mismatch. We denote the methods that work directly on speech to eliminate the relatively explicit mismatches collectively as data adaptation methods. Experiments show that data adaption methods achieve 15\% improvements over our baseline. Furthermore, some popular back-ends domain adaptation algorithms are deployed on speaker embeddings to alleviate speaker performance degradation caused by the implicit mismatch. Score calibration is a major failure for us in SRE21. The reason is that score calibration with too many parameters easily lead to overfitting problems.